Abstract
Mainstream BLAS libraries deliver high performance on large-scale GEMM and TRSM, but remain insufficient for batch operations on large groups of fixed-size small matrices — a pattern widely used across scientific computing. We propose IATF, an input-aware tuning framework that boosts near-optimal performance for large groups of fixed-size small GEMM and TRSM on the ARMv8 architecture.
IATF has two stages. At install time, using a SIMD-friendly data layout, it builds computing-kernel templates for GEMM and TRSM, derives optimal kernel sizes to raise the computational-instruction ratio, and applies kernel optimizations plus an optimized data-packing strategy to cut memory-access overhead. At run time, it generates an efficient execution plan from the input matrix properties. Experiments show significant improvements in both GEMM and TRSM over other mainstream BLAS libraries.
Key Contributions
Input-aware tuning framework
A high-performance framework for large groups of small-matrix operations that selects an optimal execution plan based on input matrix properties — size, transpose mode, side, triangle, and unit-diagonal.
Kernel & packing design
A SIMD-friendly data layout plus template-generated kernels and data-packing methods for compact GEMM and compact TRSM, dramatically improving performance and reducing edge-processing waste.
IATF library on ARMv8
A complete library for fixed-size small GEMM and TRSM on the Kunpeng 920, competitive even with Intel MKL's compact BLAS (measured as % of peak performance).
The Problem with Traditional Methods
Applications from PDE simulations to high-order CFD and ML process huge groups of tiny matrices. Four properties break classic large-GEMM optimizations:
① SIMD underuse
A very small matrix can't fill the width of a SIMD register under traditional layouts.
② Edge overhead
Boundary processing is a large fraction of work for small matrices, not a negligible tail.
③ Tiling is moot
A small matrix fits entirely in L1 cache, so classic multi-level tiling buys nothing.
④ No input-aware tuning
No framework generates high-performance plans across the many small sizes that appear.
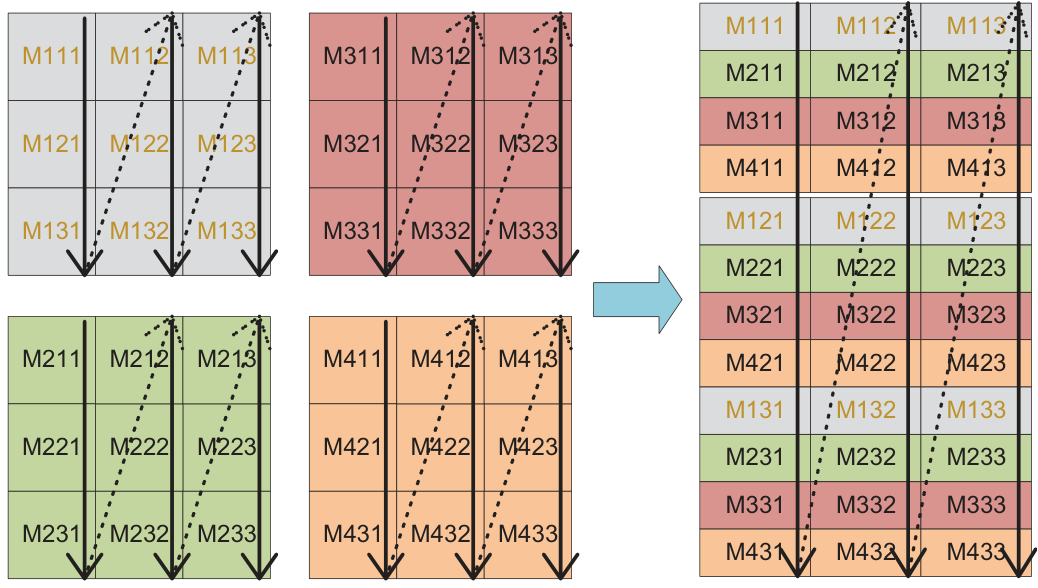
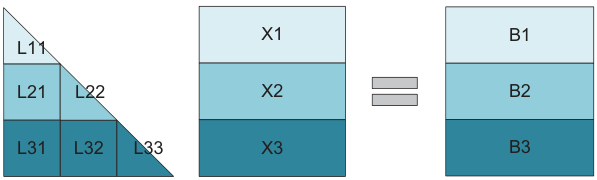
SIMD-friendly Layout & Smaller Kernels
Because P matrices fill one SIMD register, IATF can use a much smaller register-level kernel than traditional tiling — which in turn slashes the number of awkward edge blocks.
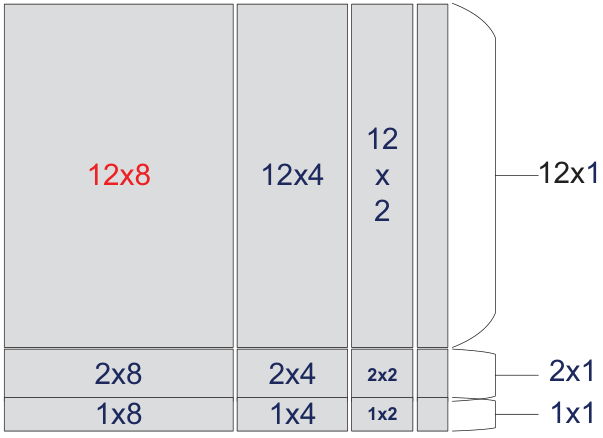
Kernel Templates, Sizing & Packing
Maximizing the compute-to-memory-access ratio
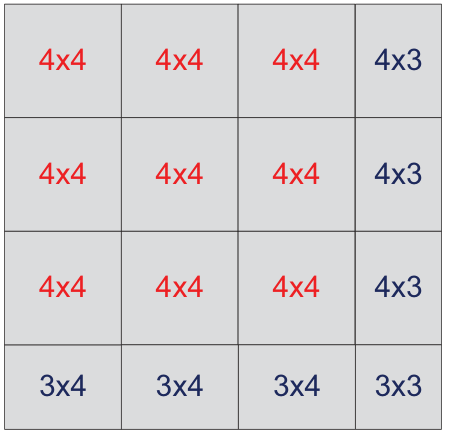
Kernels are built from 6 reusable templates (I, M1, M2, E, SAVE, SUB) that implement a "ping-pong" schedule — loading the next iteration's data during the current compute to avoid pipeline bubbles. Maximizing CMAR under the 32-register budget (2mc+2nc+mcnc ≤ 32) yields an optimal 4×4 kernel for real GEMM and 3×2 for complex. IATF then generates kernels for every edge size.
Kernel optimization & data packing
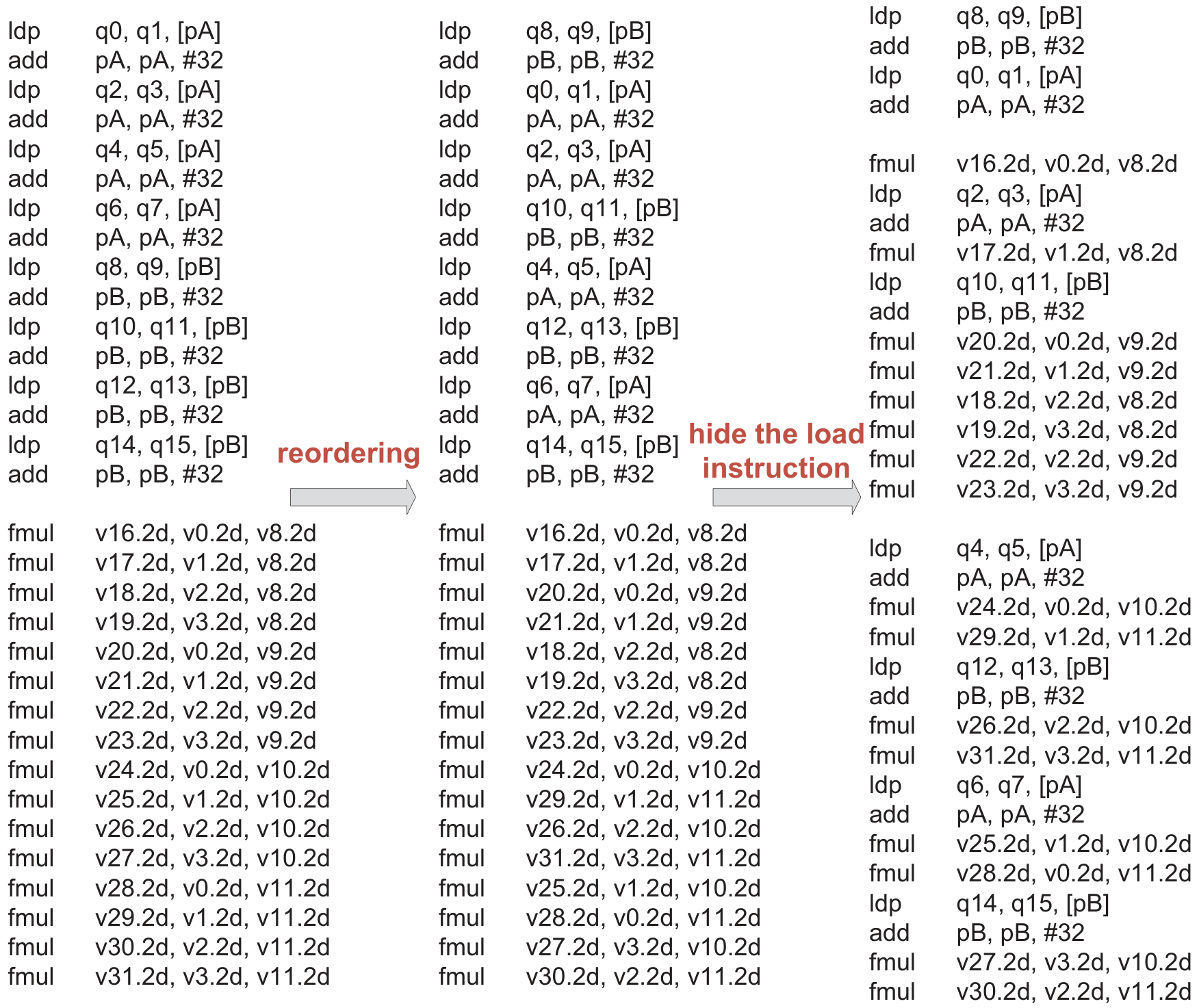
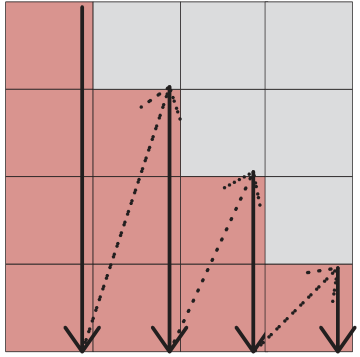
Building the Execution Plan
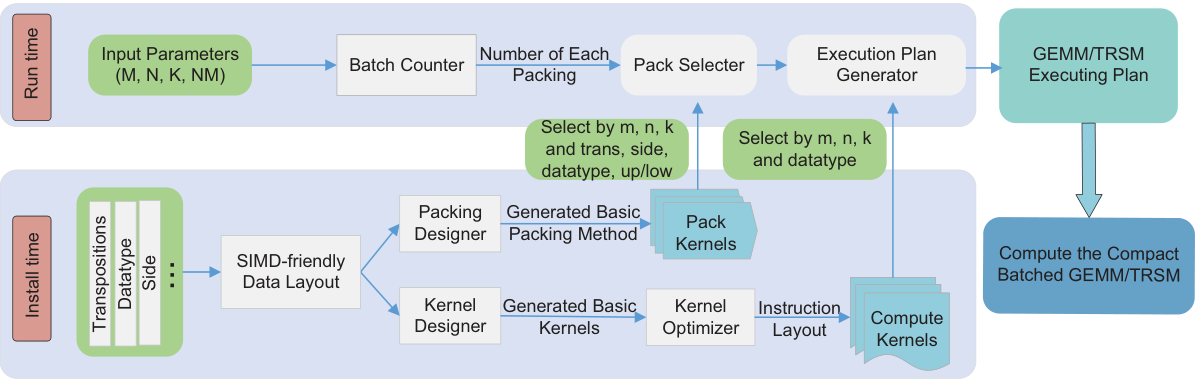
Batch Counter
- Picks how many matrices to batch per operation
- Keeps the working set within L1 cache
- Reserves space for matrix C (GEMM) / triangle (TRSM)
Pack Selector + Plan Generator
- Chooses the optimal packing kernel — or no-packing
- Selects the best-matching computing kernel per size
- Links everything into a high-performance command queue
The run-time plan is generated once per batch, so its overhead is negligible when amortized across a large group of matrices.
Performance on Kunpeng 920
Evaluated on a Kunpeng 920 (ARMv8.2) against OpenBLAS, ARMPL (incl. batched GEMM), and LIBXSMM; square matrices of size 1–33, batch size 16384. Intel MKL's compact BLAS on a Xeon Gold 6240 is included as a % -of-peak reference.
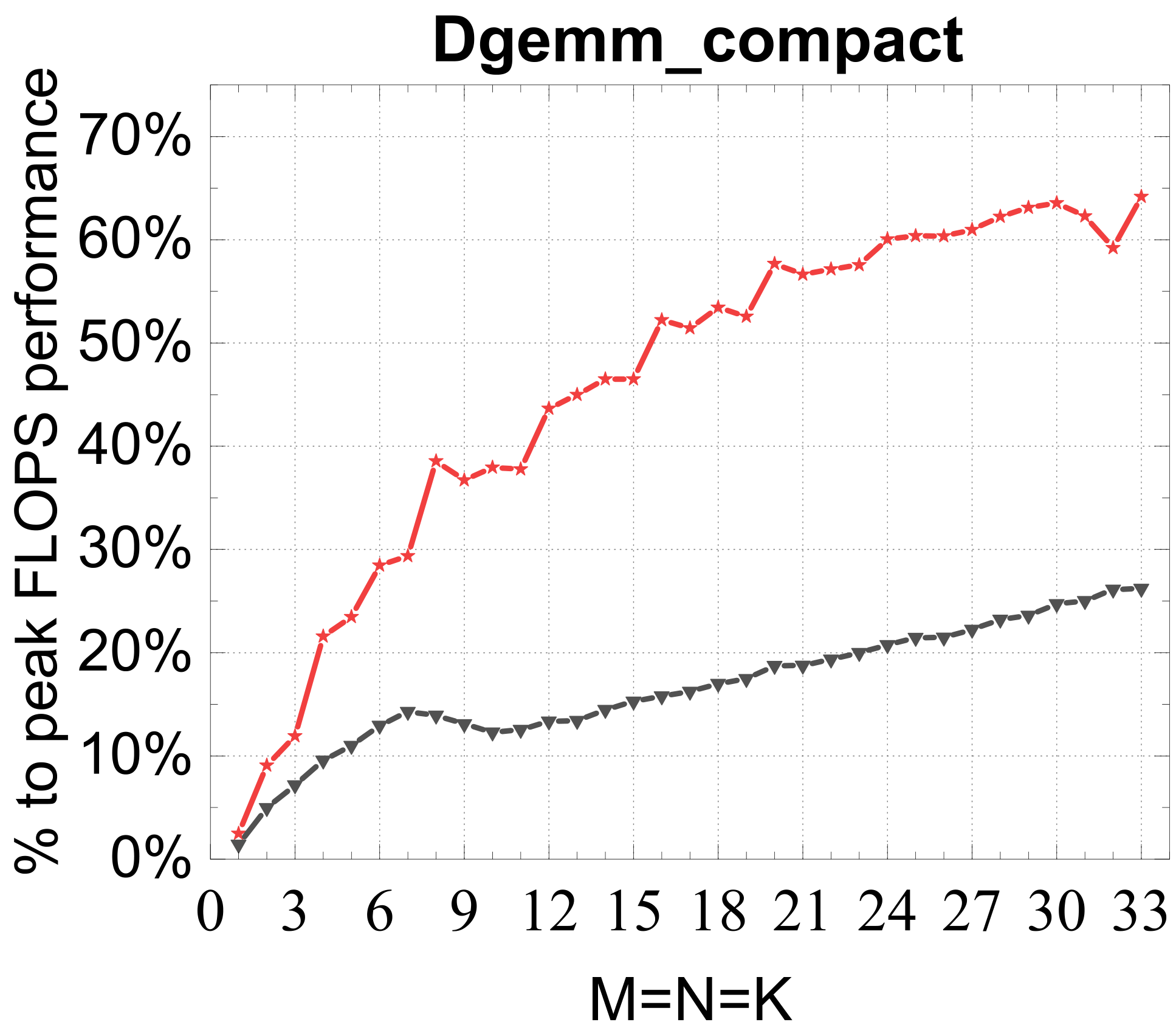
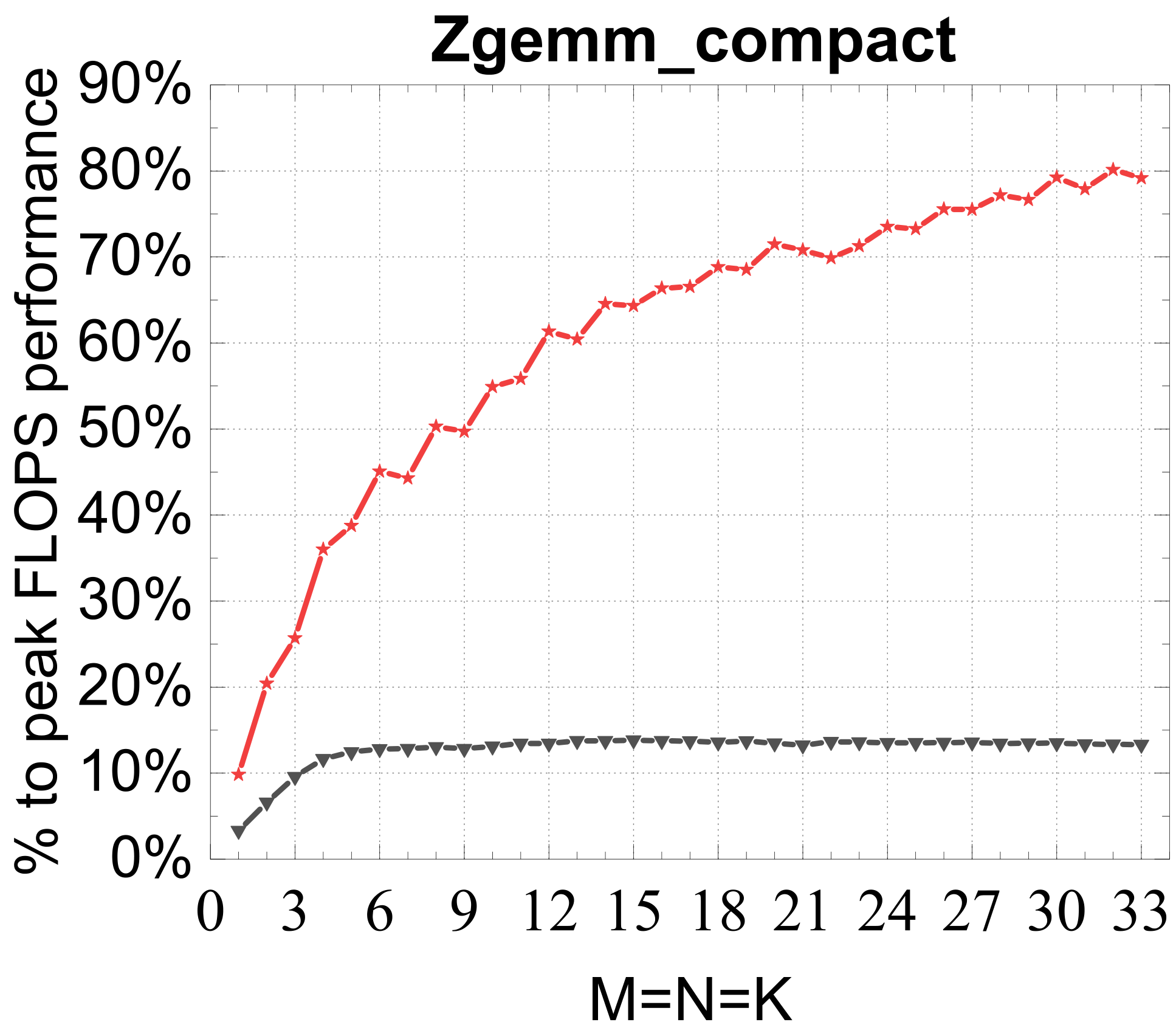
Compact GEMM
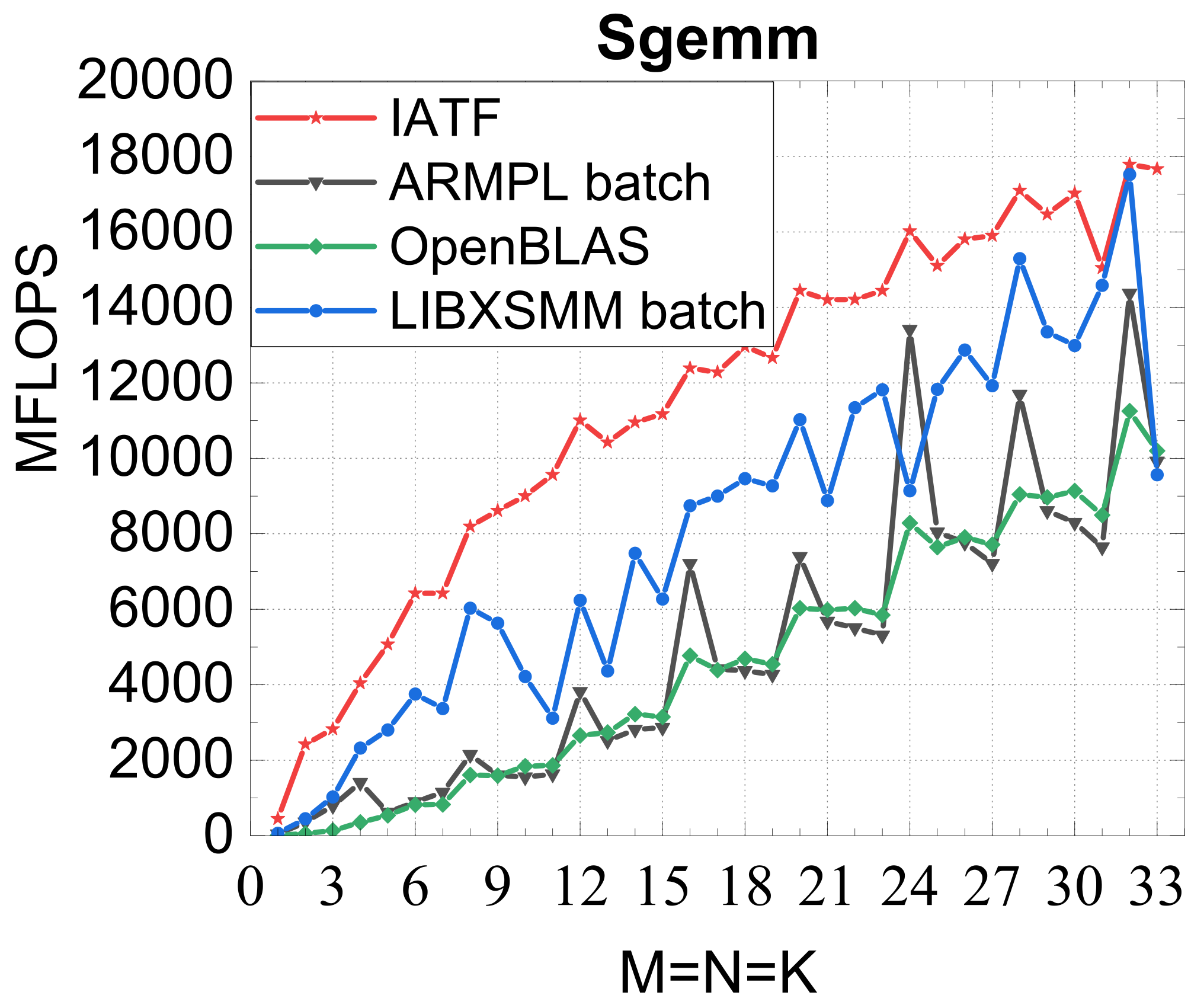
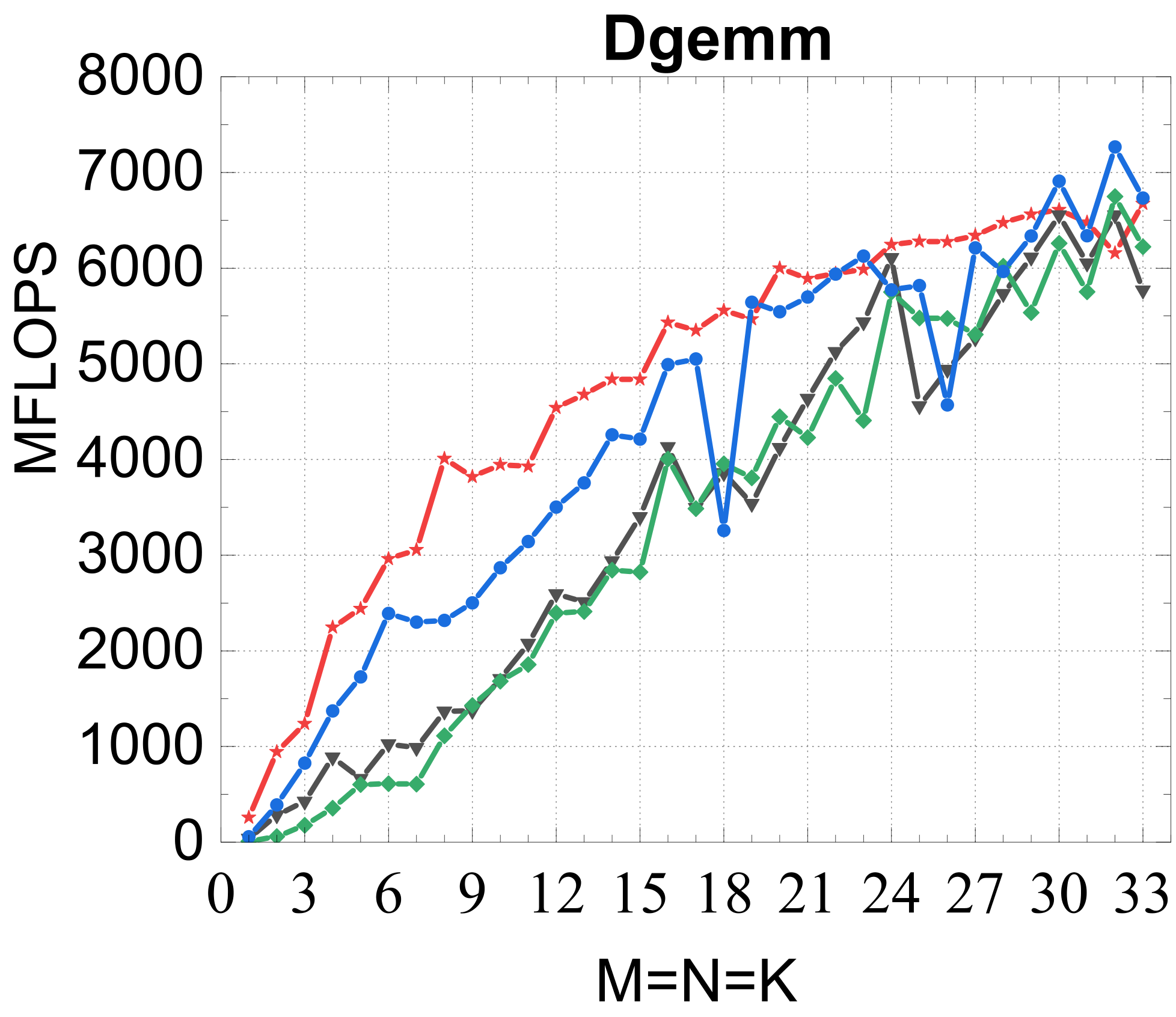
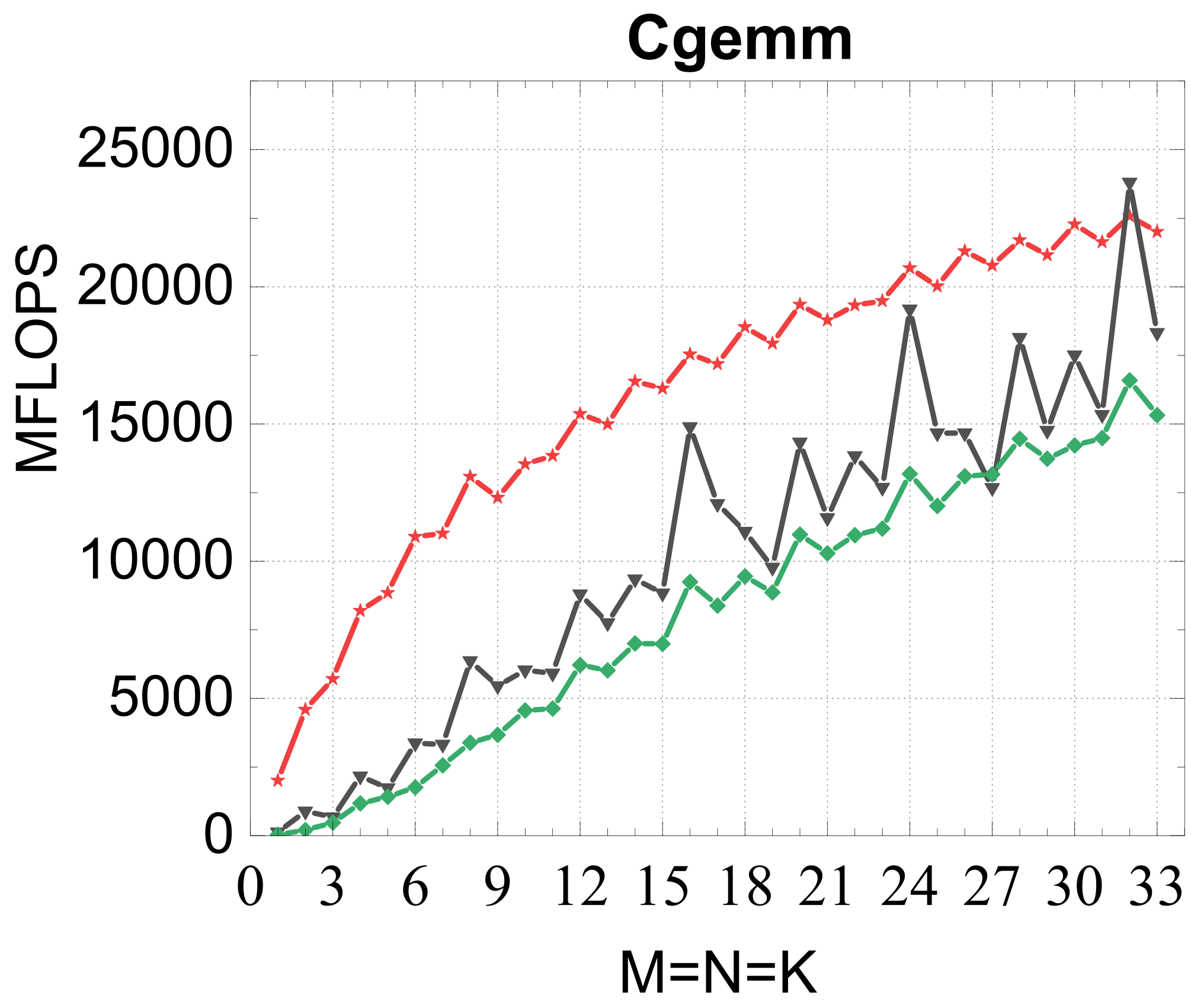
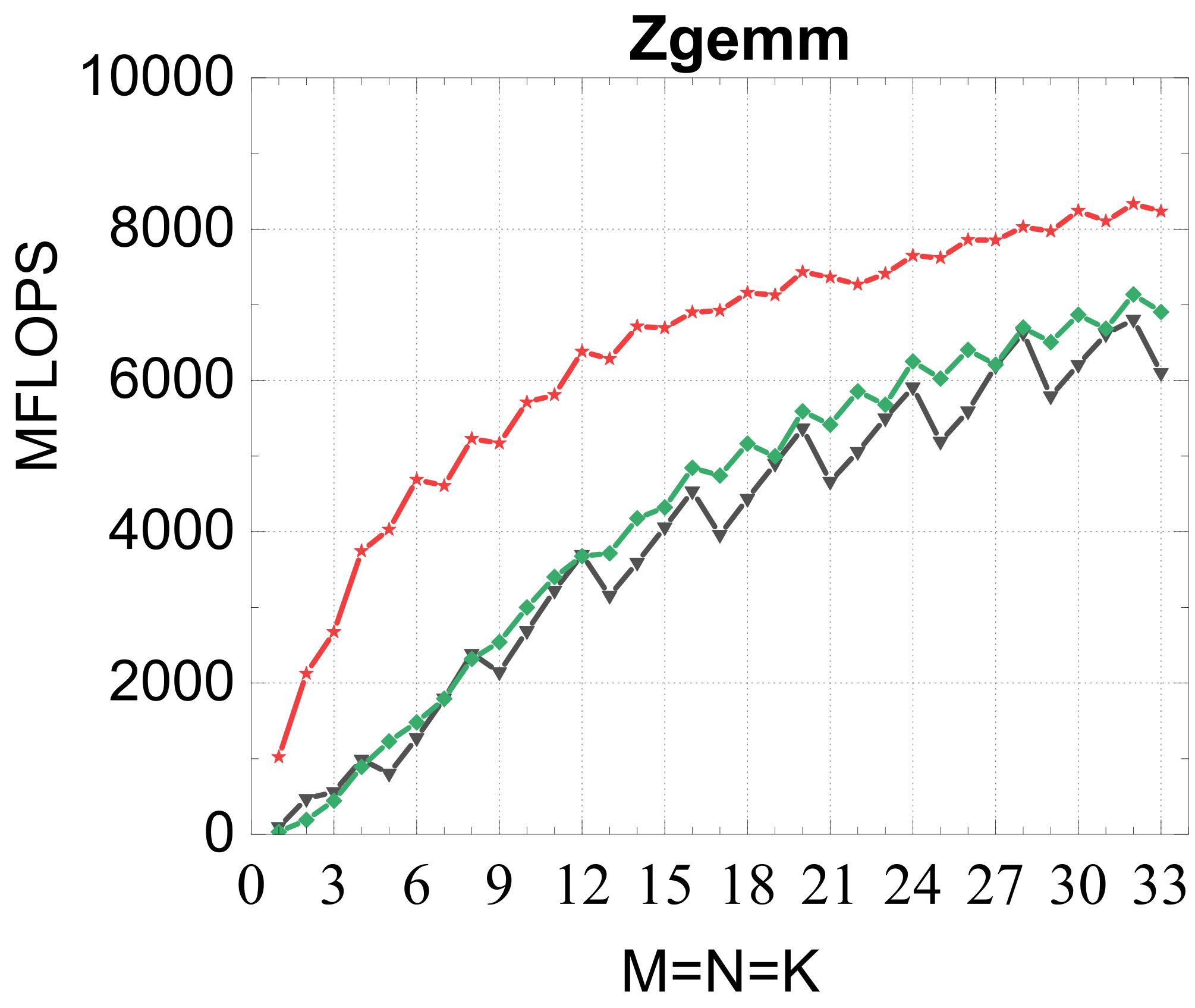
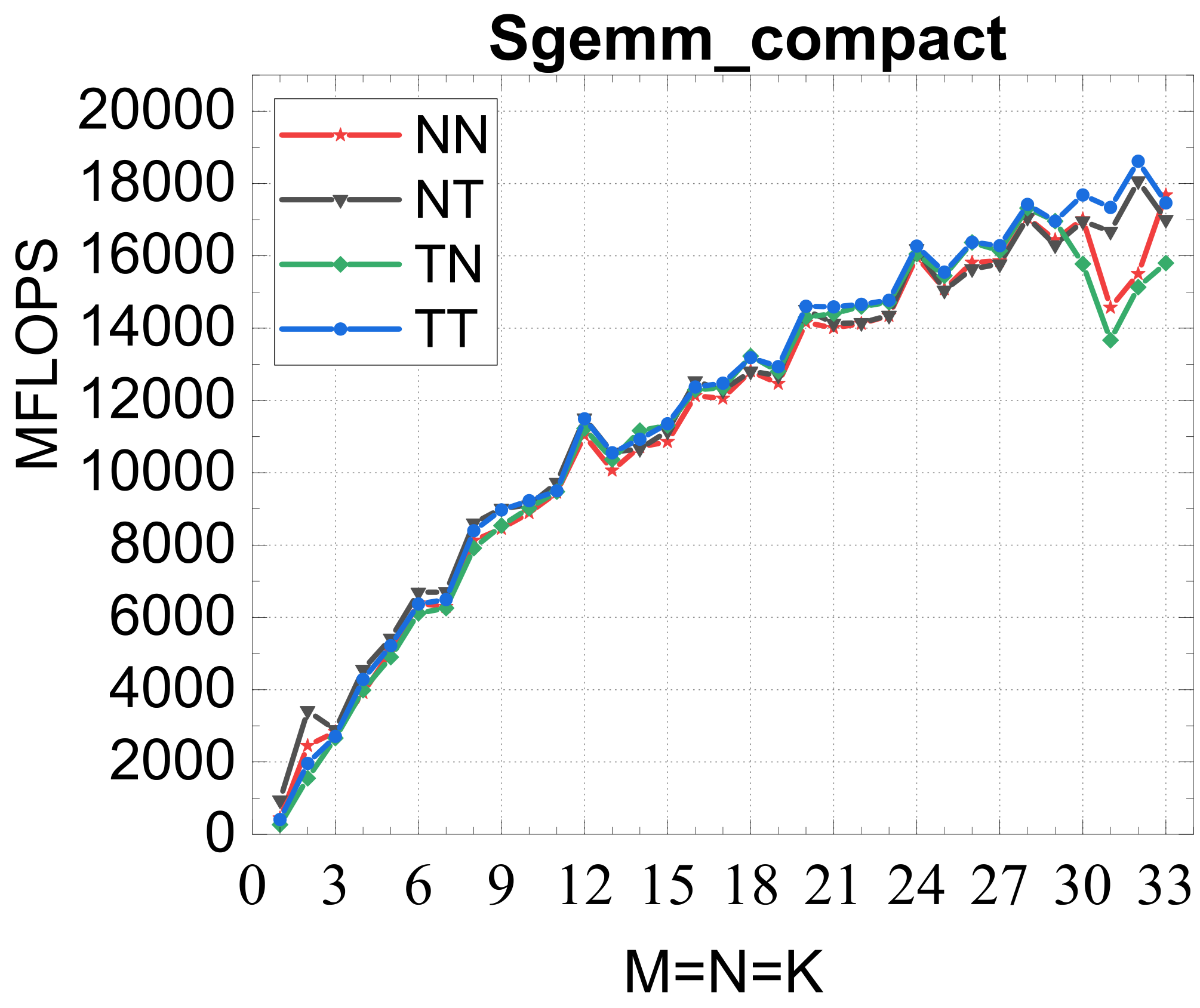
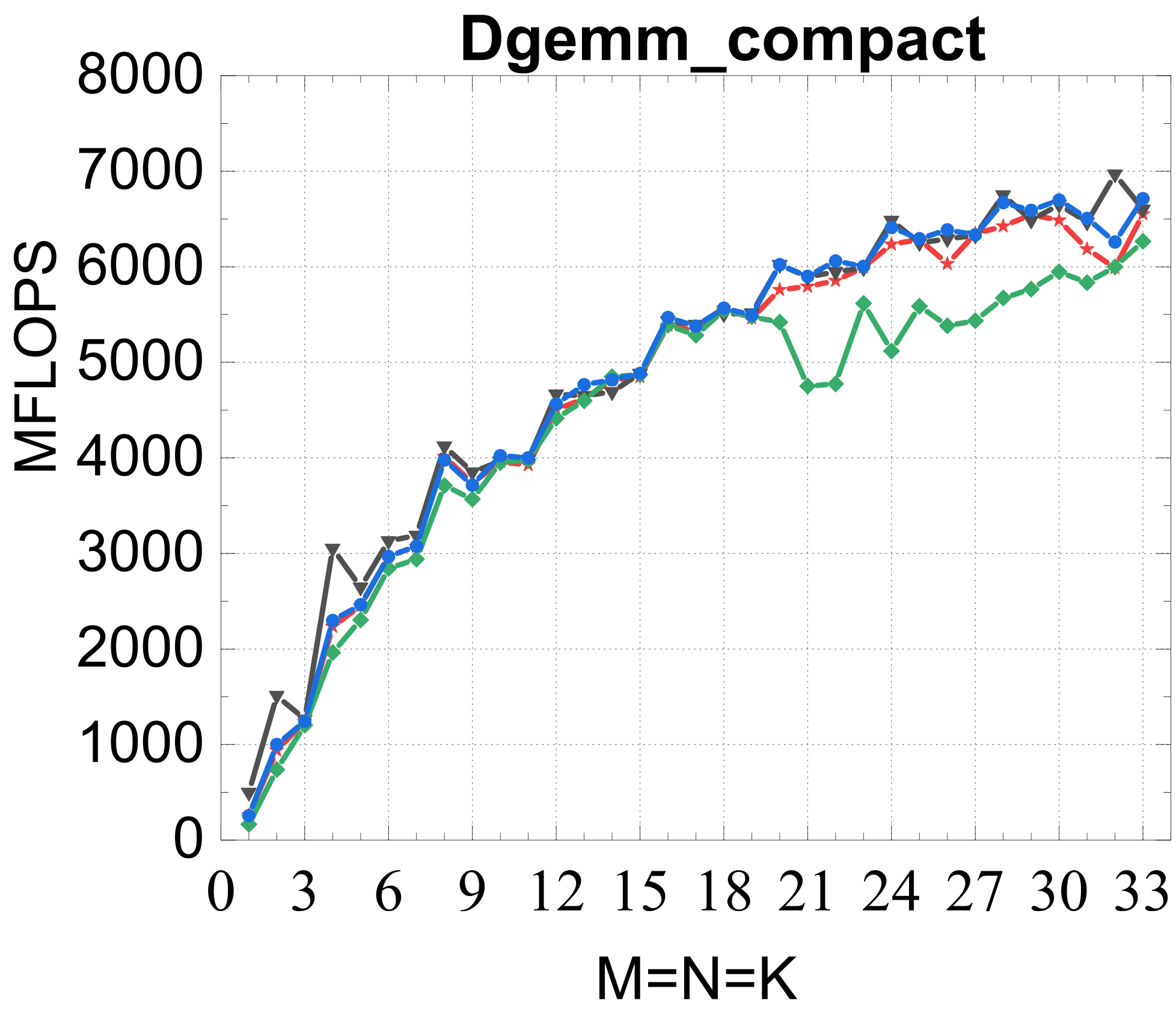
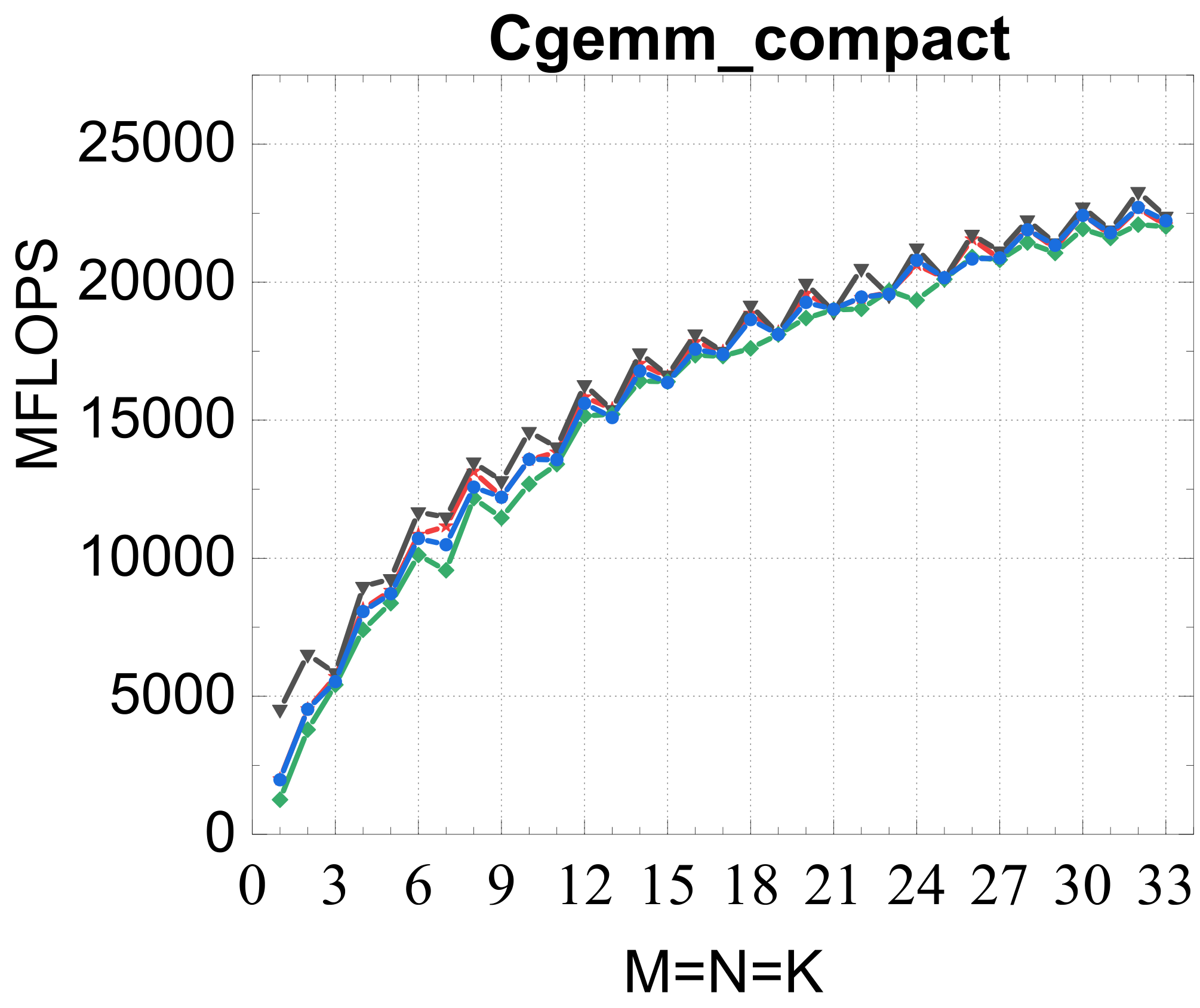
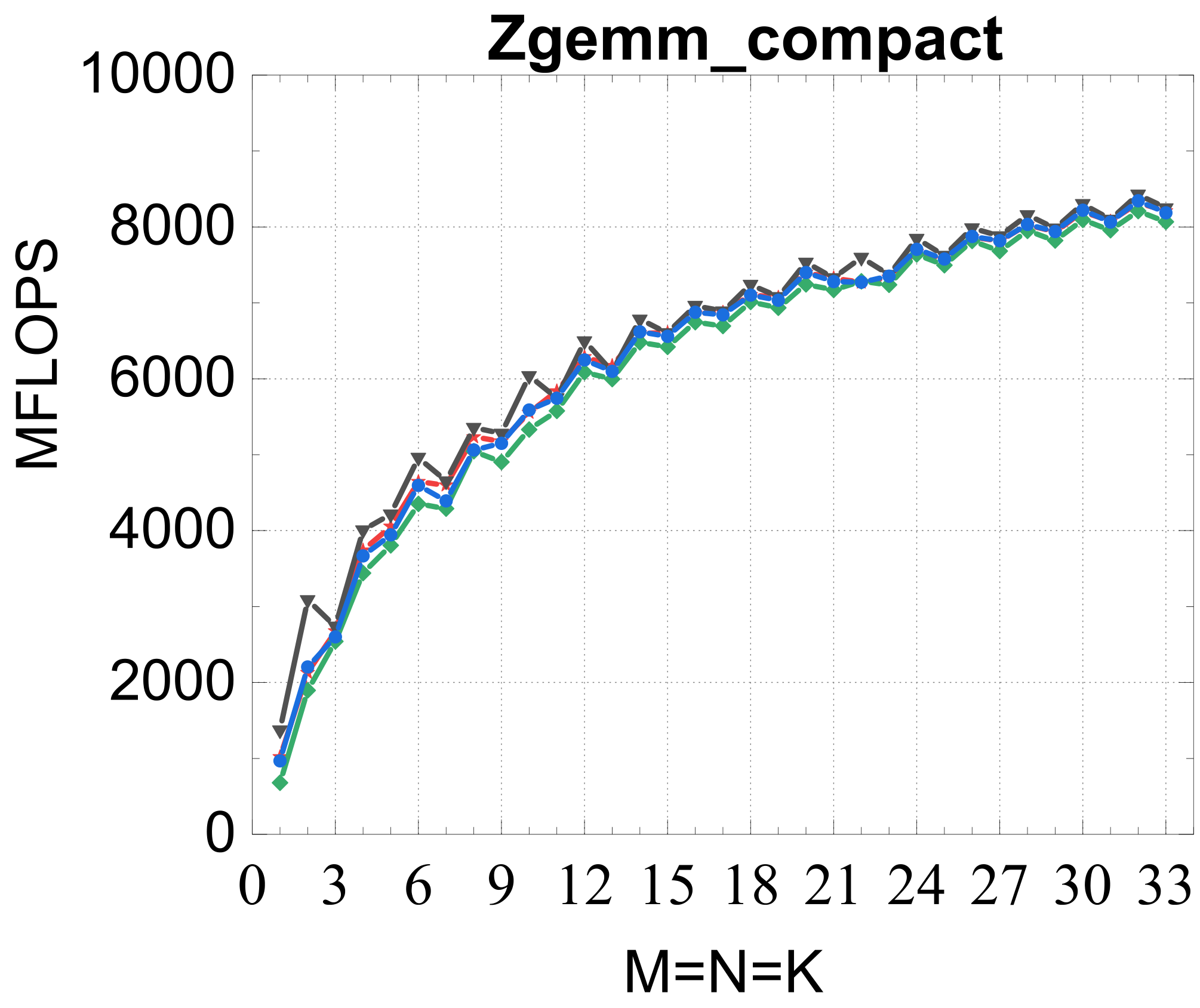
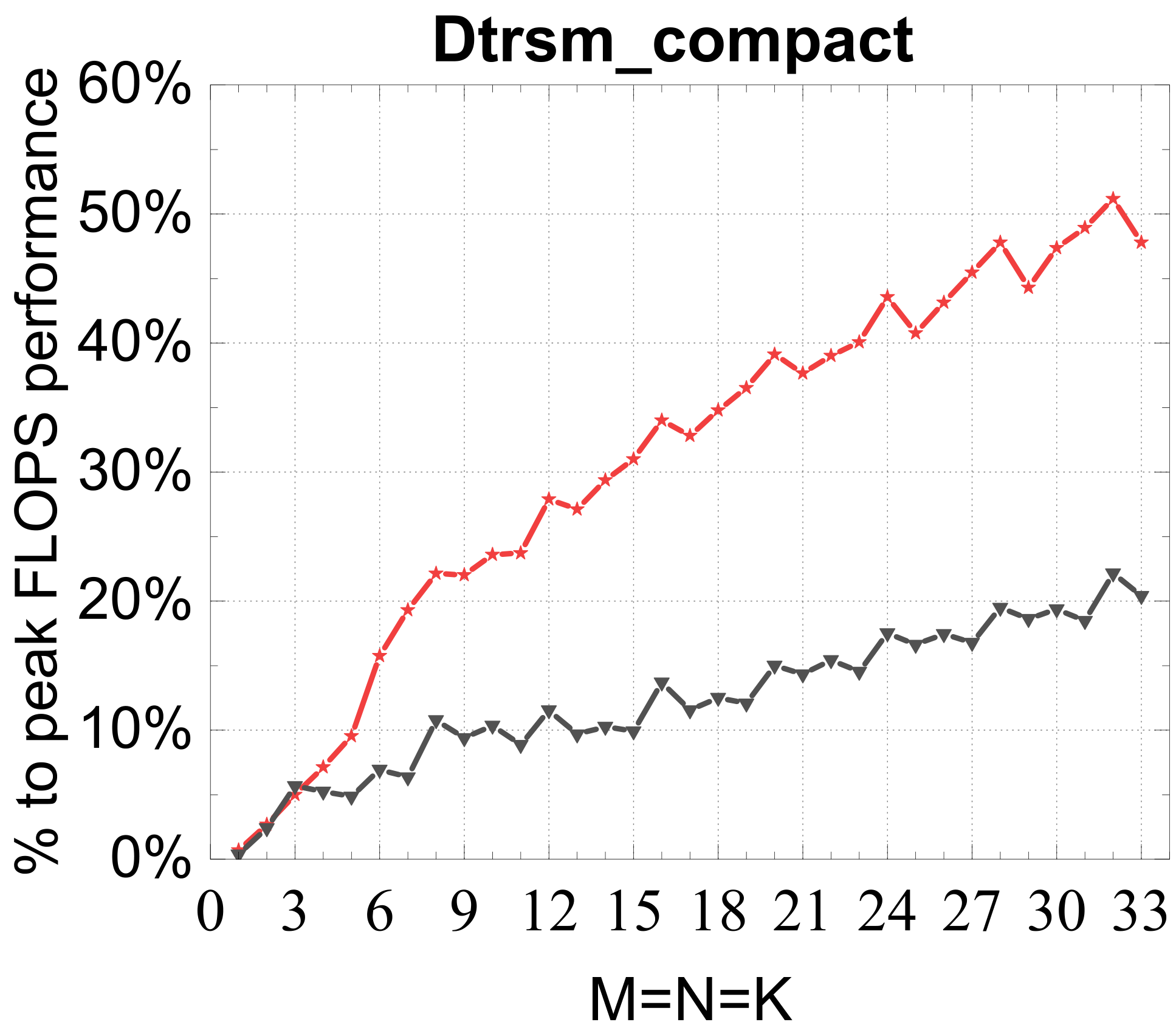
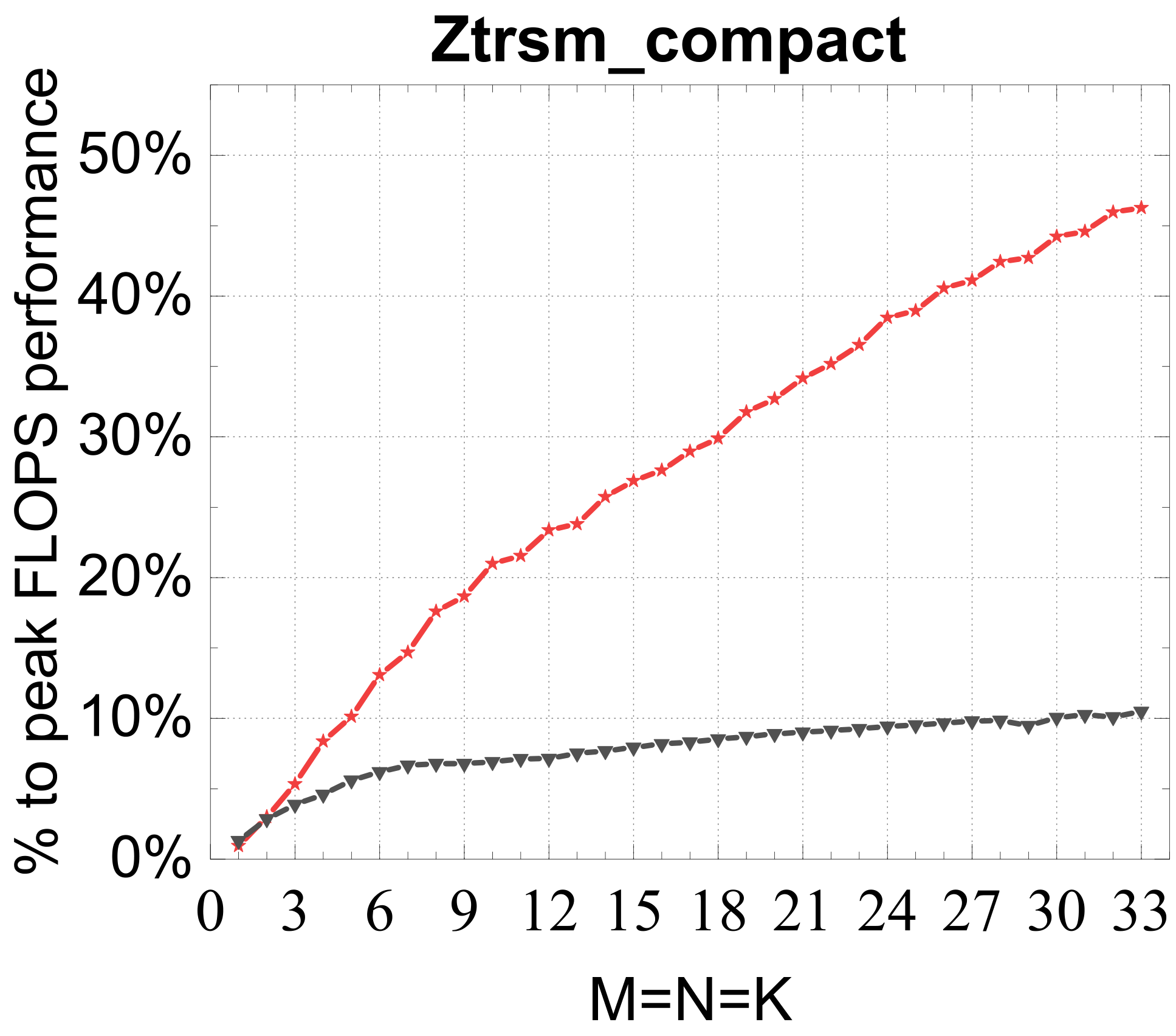
Compact TRSM
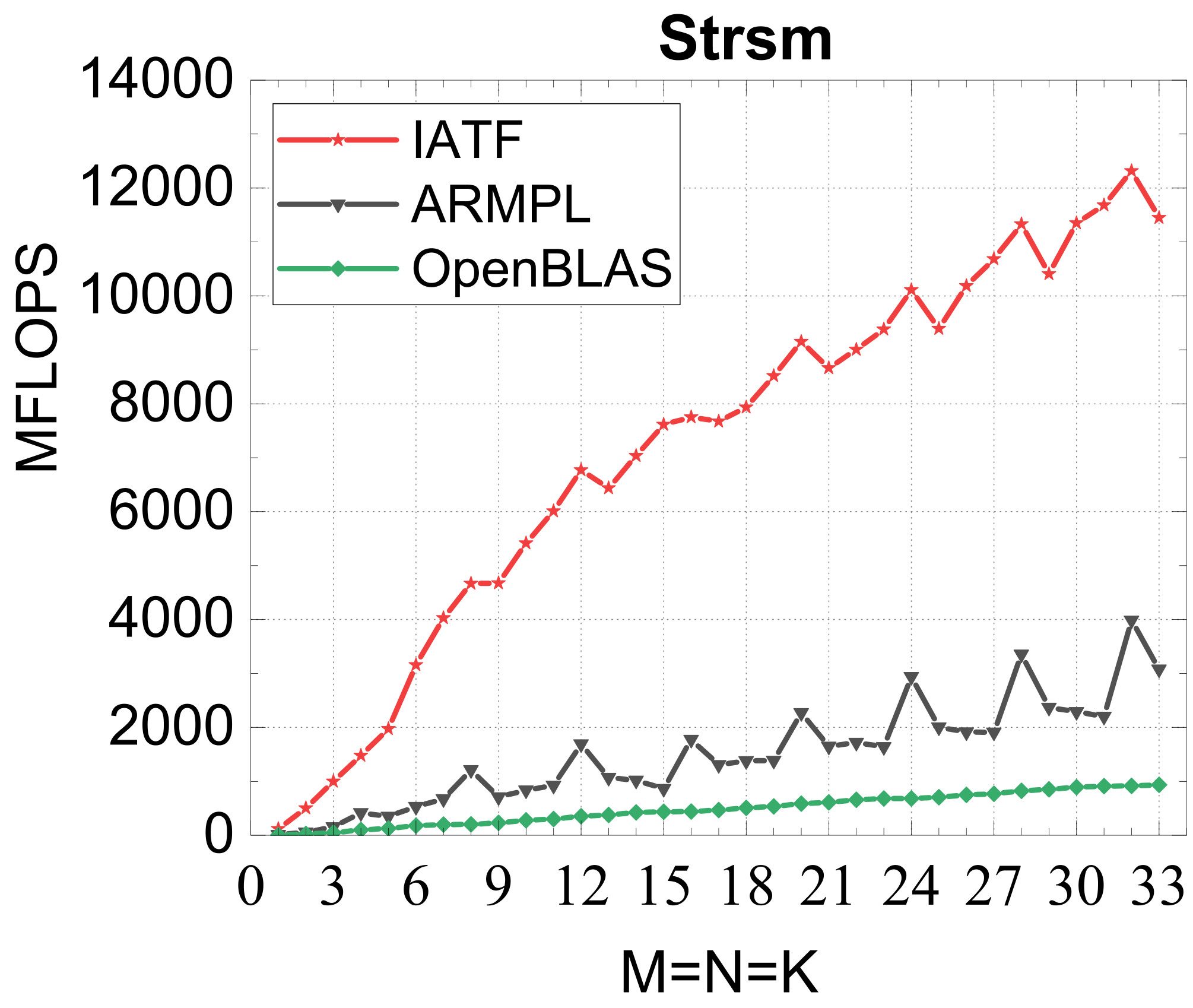
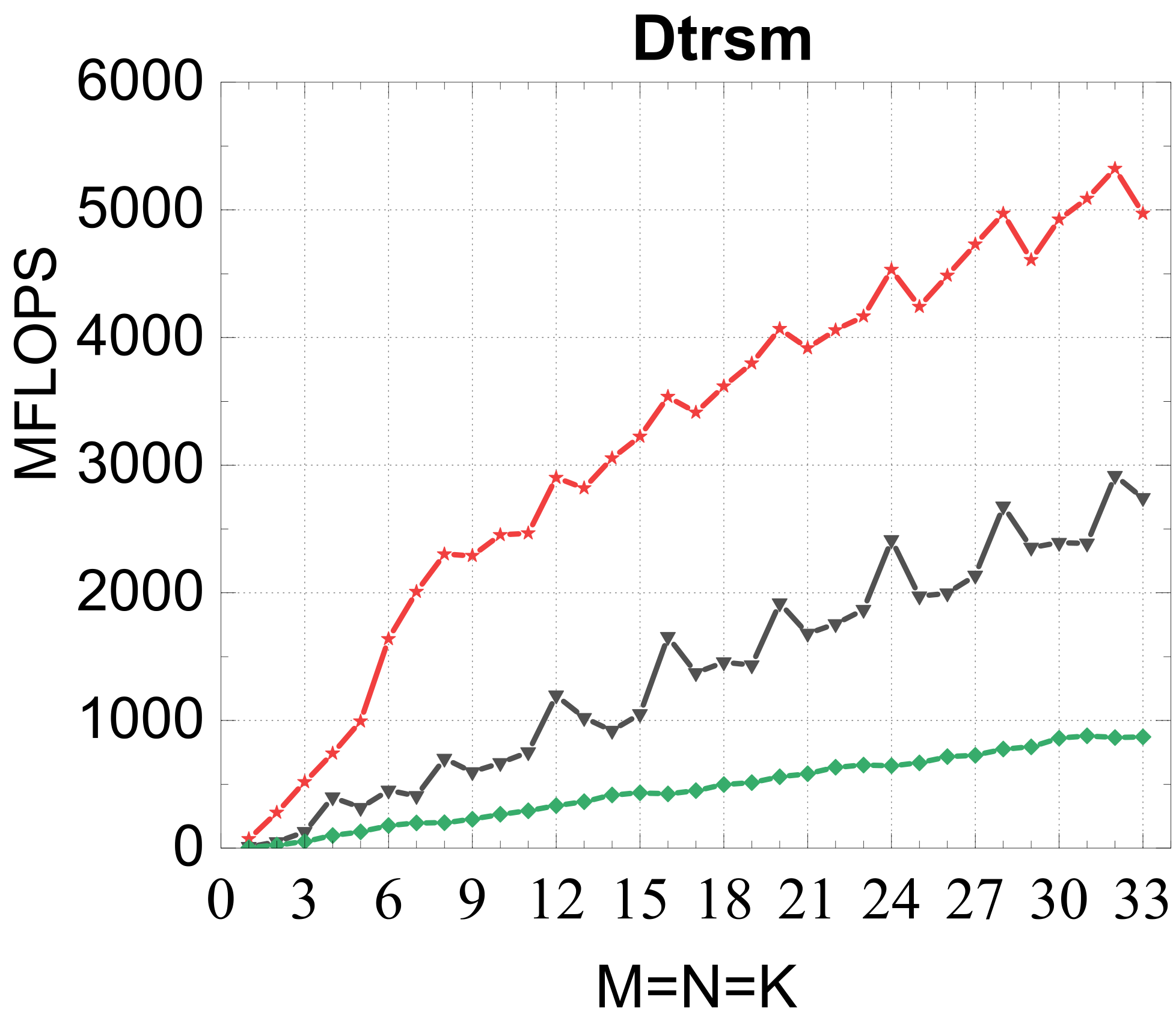
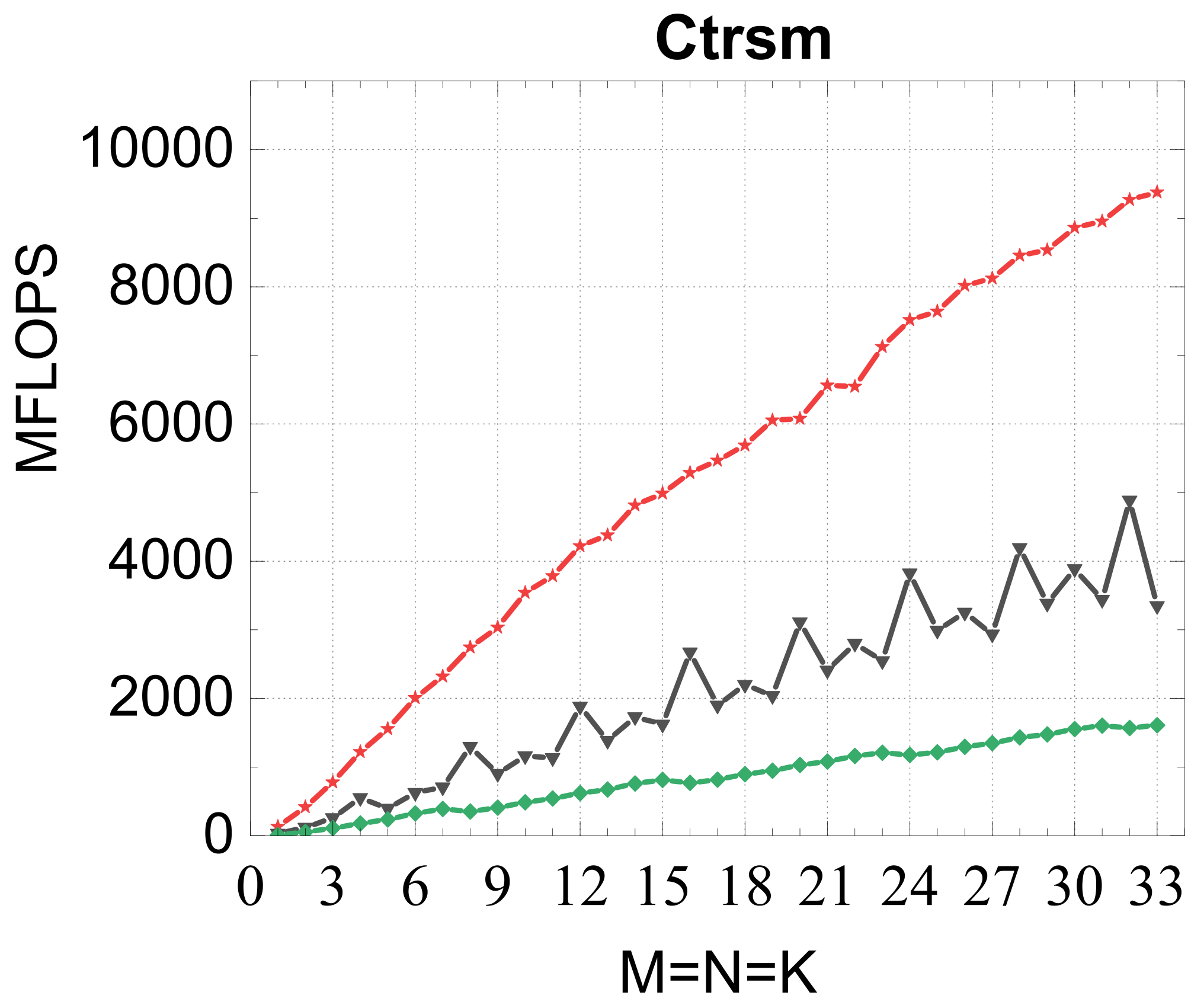
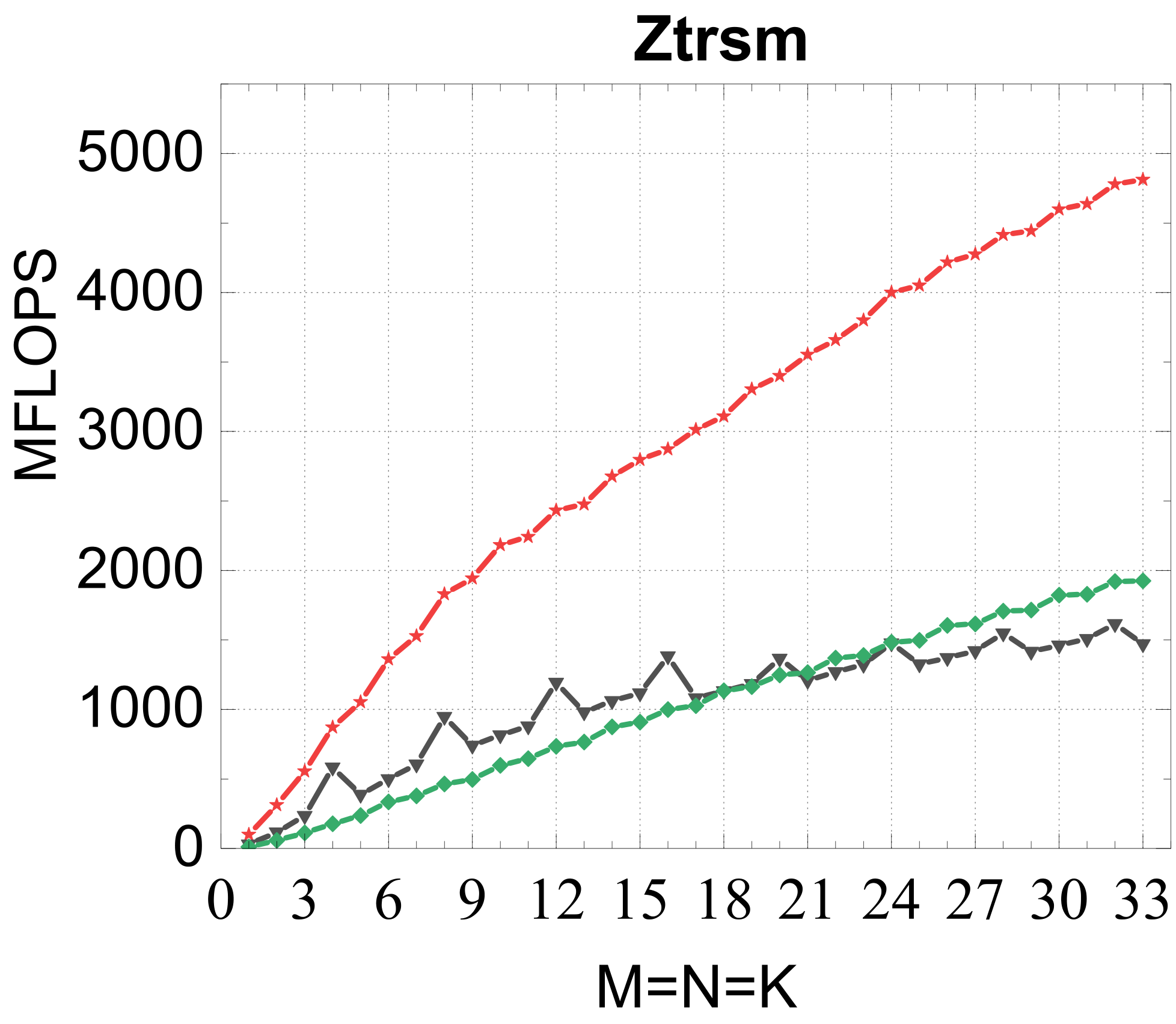
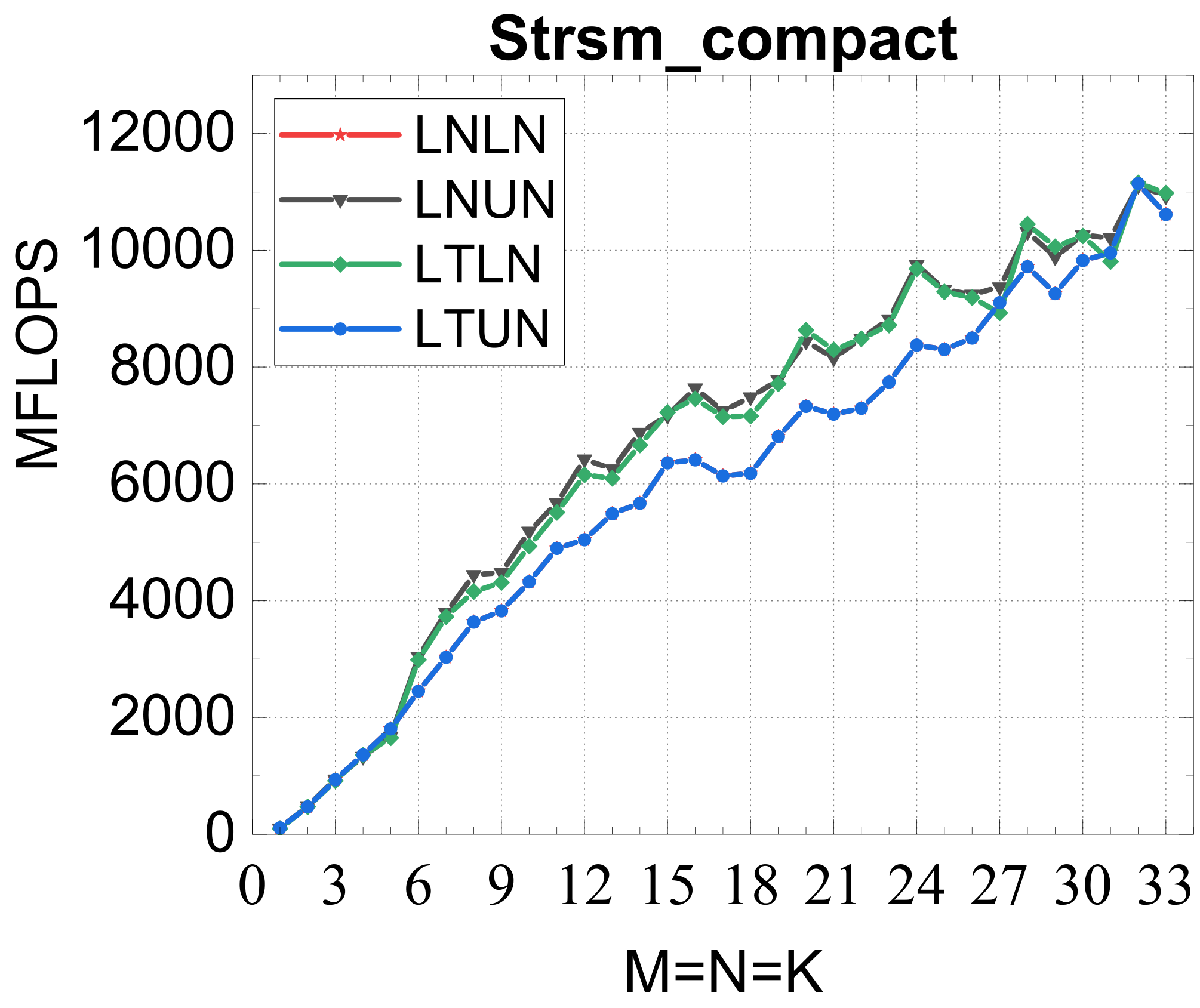
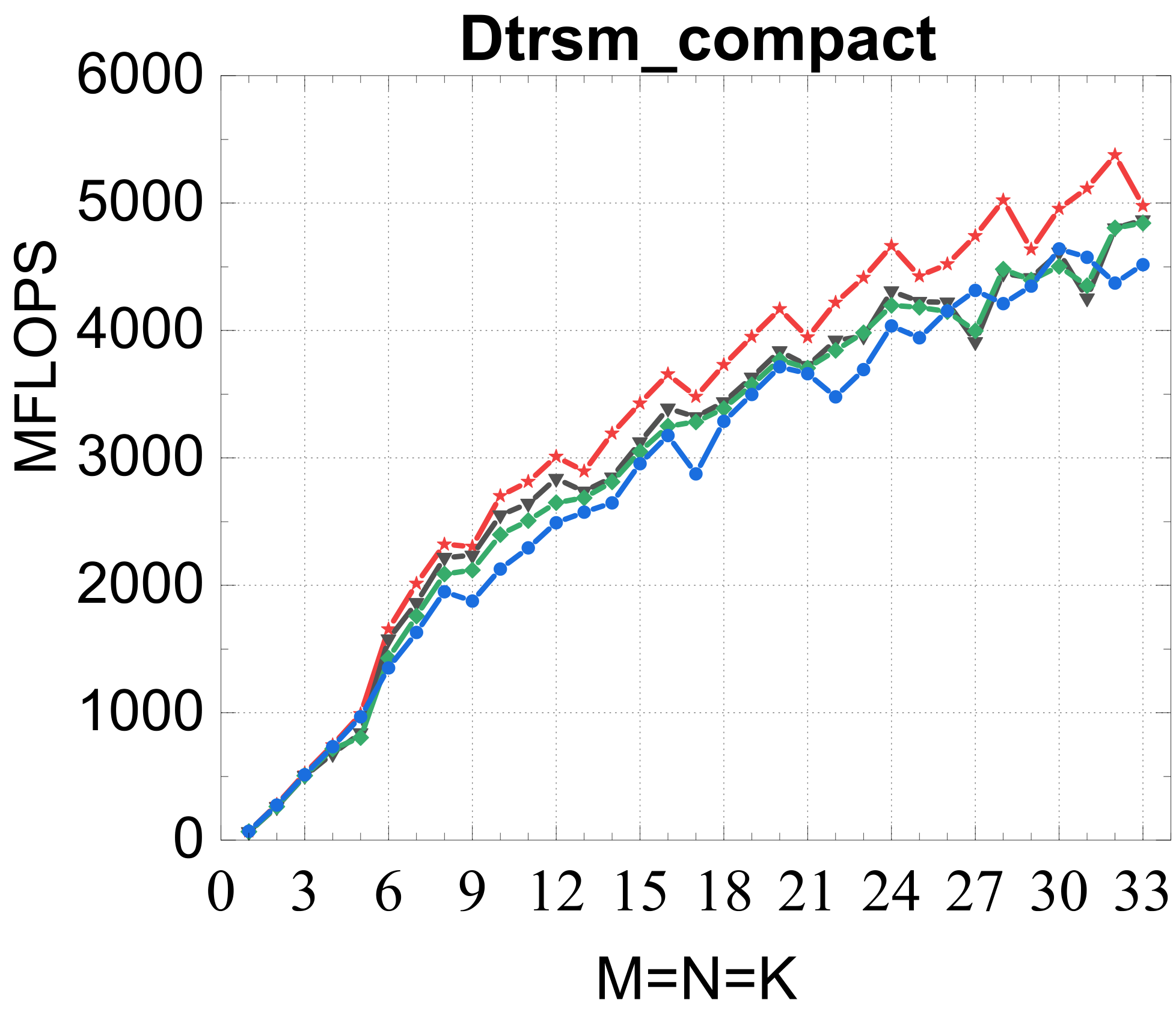
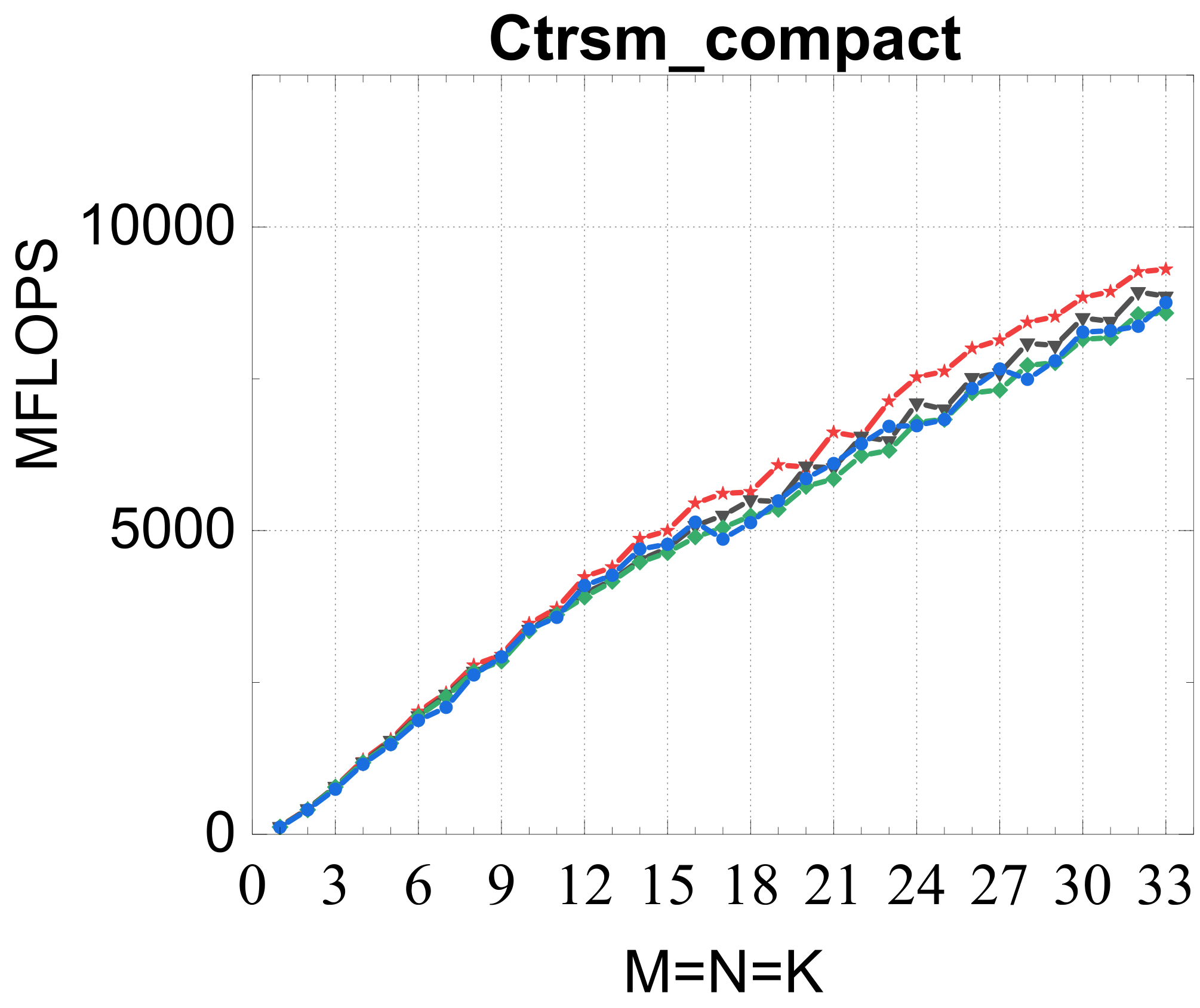
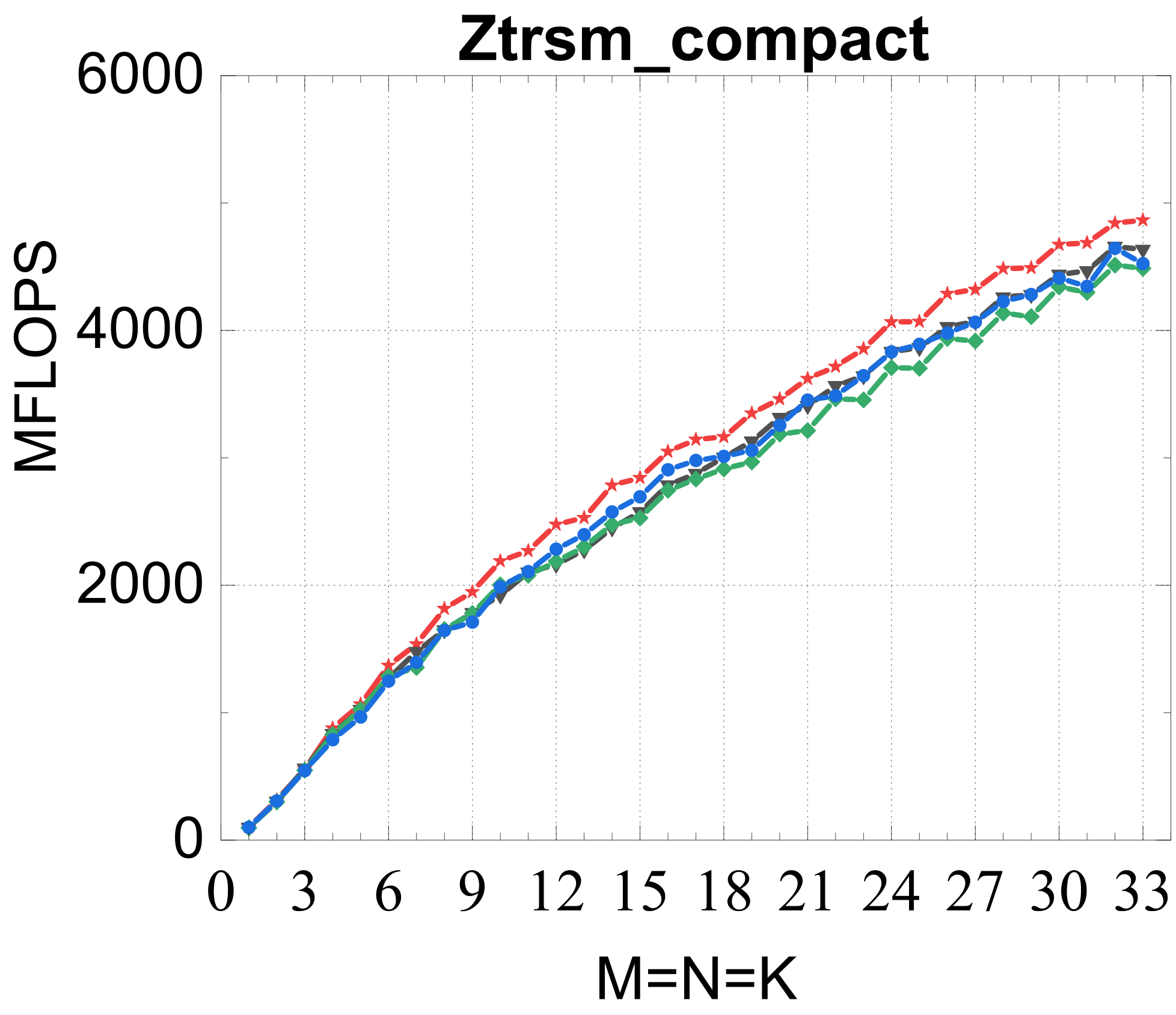
Reference vs. Intel MKL (% of peak)
Bottom line
Traditional large-GEMM optimizations leave most of the performance on the table for batches of fixed-size small matrices. IATF's SIMD-friendly layout, template-generated edge-aware kernels, smart packing, and input-aware run-time planning deliver up to 21× (GEMM) and 28× (TRSM) over OpenBLAS on ARMv8 — and hold their own against Intel MKL's compact BLAS as a fraction of peak.
BibTeX
@inproceedings{wei2022iatf,
title = {IATF: An Input-Aware Tuning Framework for Compact
BLAS Based on ARMv8 CPUs},
author = {Wei, Cunyang and Jia, Haipeng and Zhang, Yunquan
and Xu, Liusha and Qi, Ji},
booktitle = {Proceedings of the 51st International Conference on
Parallel Processing (ICPP '22)},
year = {2022},
doi = {10.1145/3545008.3545032}
}