Abstract
Matrix multiplication is fundamental to linear algebra and scientific computing. Although mainstream BLAS libraries are highly tuned for large dense GEMM, they perform poorly on irregular inputs. This paper proposes an input-aware tuning framework that accounts for both the application scenario and the computer architecture to deliver high-performance irregular matrix multiplication on ARMv8 and X86 CPUs.
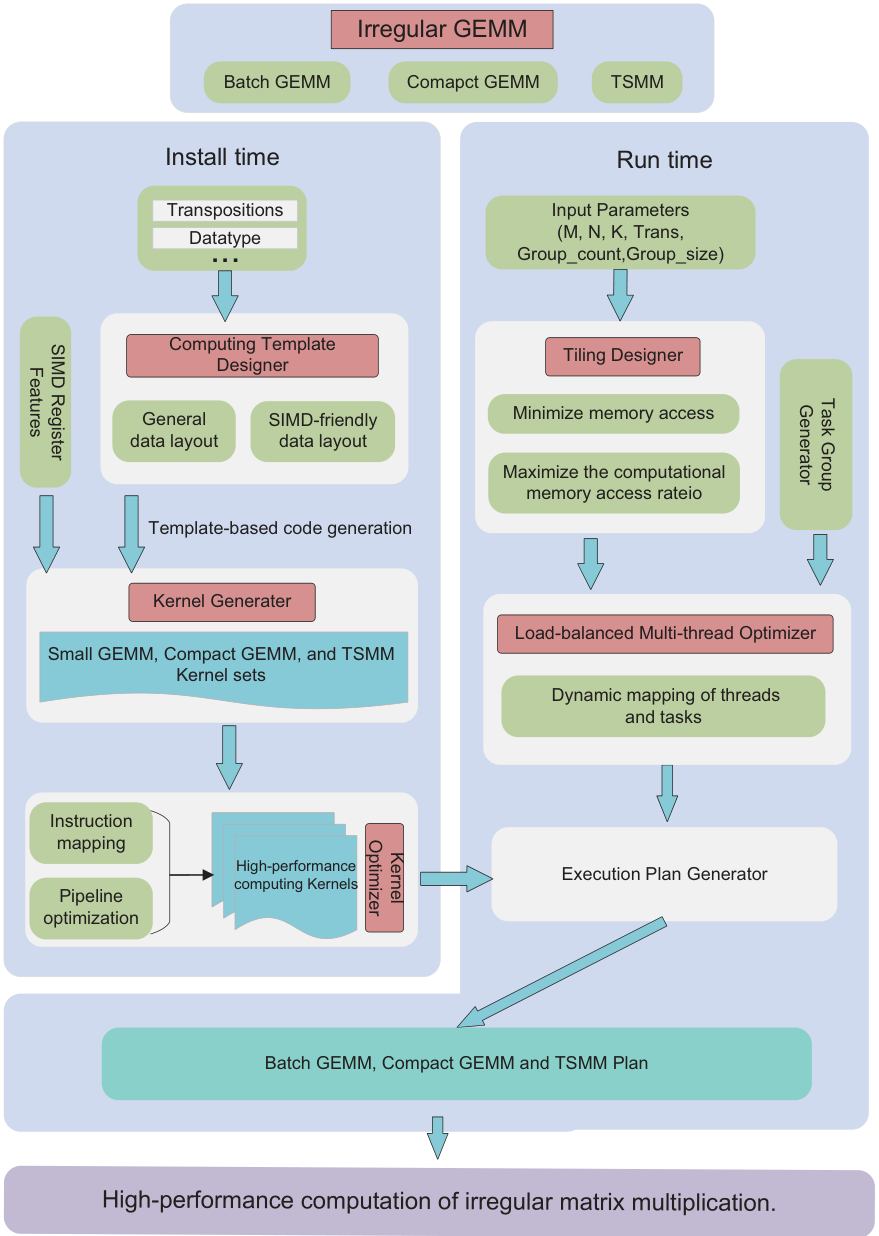
IrGEMM has two stages. The install-time stage uses a computational template to generate high-performance kernels for both general and SIMD-friendly data layouts. The run-time stage applies a tiling algorithm suited to irregular GEMM to select optimal kernels and link them into an execution plan, with load-balanced multi-threading to exploit modern multi-core CPUs. Experiments show significant improvements for irregular GEMM on both ARMv8 and X86 over other mainstream BLAS libraries.
Key Contributions
Scenario- & arch-aware framework
A performance-tuning framework that considers both the target application scenario and CPU architecture, with load-balanced multi-threaded scheduling — demonstrated across all three irregular GEMM types.
Template-based code generation
The first comprehensive code-generation method for irregular matmul: computational templates + instruction-mapping rules emit highly-optimized assembly kernels for both ARMv8 and X86.
Input-aware tiling
A dynamic-programming tiling algorithm that minimizes memory access and avoids tiny blocks, selecting optimal kernel combinations for consistent performance at any matrix scale.
The IrGEMM library
A high-performance library for ARMv8 and Intel Cascade Lake that surpasses MKL, ARMPL, BLIS, LIBXSMM, and OpenBLAS across Batch GEMM, Compact GEMM, and TSMM.
This journal paper unifies and extends the authors' conference works (IAAT, IATF/ICPP, AutoTSMM, LBBGEMM/HPCC): a DP-based tiling algorithm, generalization to all three irregular types on both ARMv8 and X86 AVX512, redesigned kernel templates & code-mapping for Cascade Lake, and a deeper experimental analysis.
Three Faces of Irregular GEMM
Many applications — metabolic networks, PDE simulations, finite-element tensor contractions, image processing, Transformer inference — don't fit the large-dense-GEMM mold. IrGEMM unifies three irregular patterns under one framework.
Batch GEMM
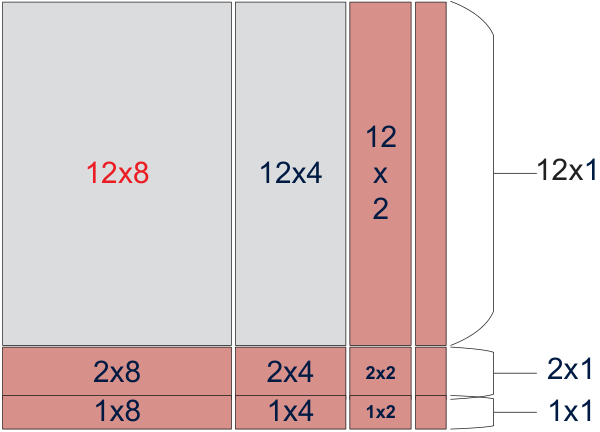
Many groups of small matrices (∛(MNK) ≤ 80); matrices share properties within a group but differ across groups. Needs load-balanced multi-thread scheduling.
Compact GEMM
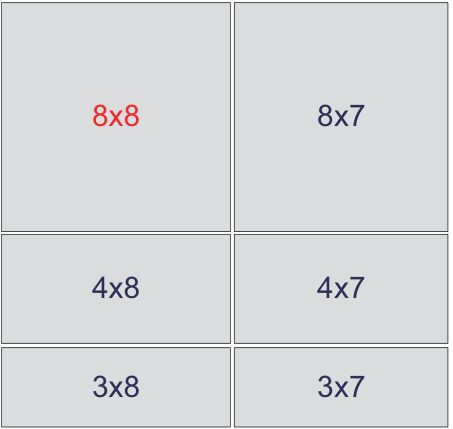
Many same-size small matrices in a SIMD-friendly data layout, so one vector instruction processes several matrices at once — filling the SIMD register width.
TSMM
Tall-and-skinny matrix multiply: one dimension far smaller than the others (short-fat A or tall-skinny B). Needs cache-blocking that adapts to the skinny shape, plus matrix reuse.
L2-based tiling is moot when matrices fit in cache; packing overhead dominates at small sizes; a few "main kernels" can't cover the many boundary sizes that irregular GEMM hits; and there's no input-aware planner. Each type adds its own twist — load imbalance (Batch), SIMD underuse (Compact), wasted cache & coupled pack/compute (TSMM).
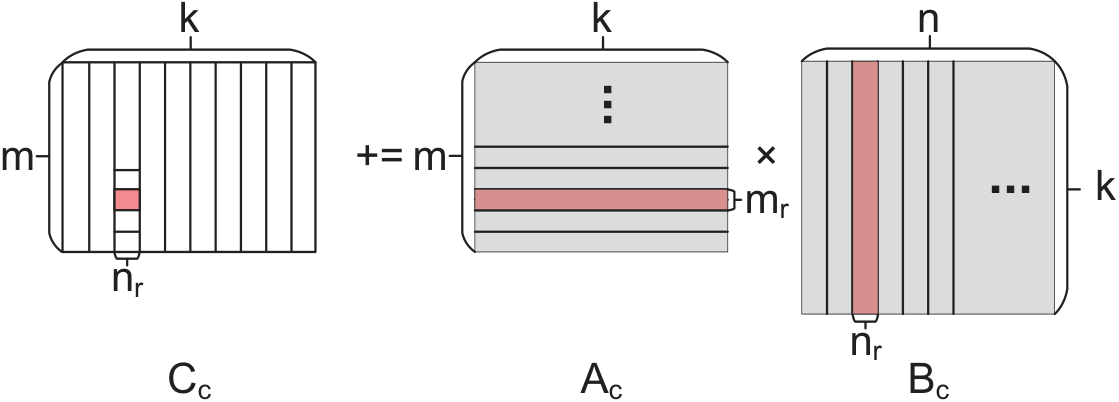
Template-based Code Generation
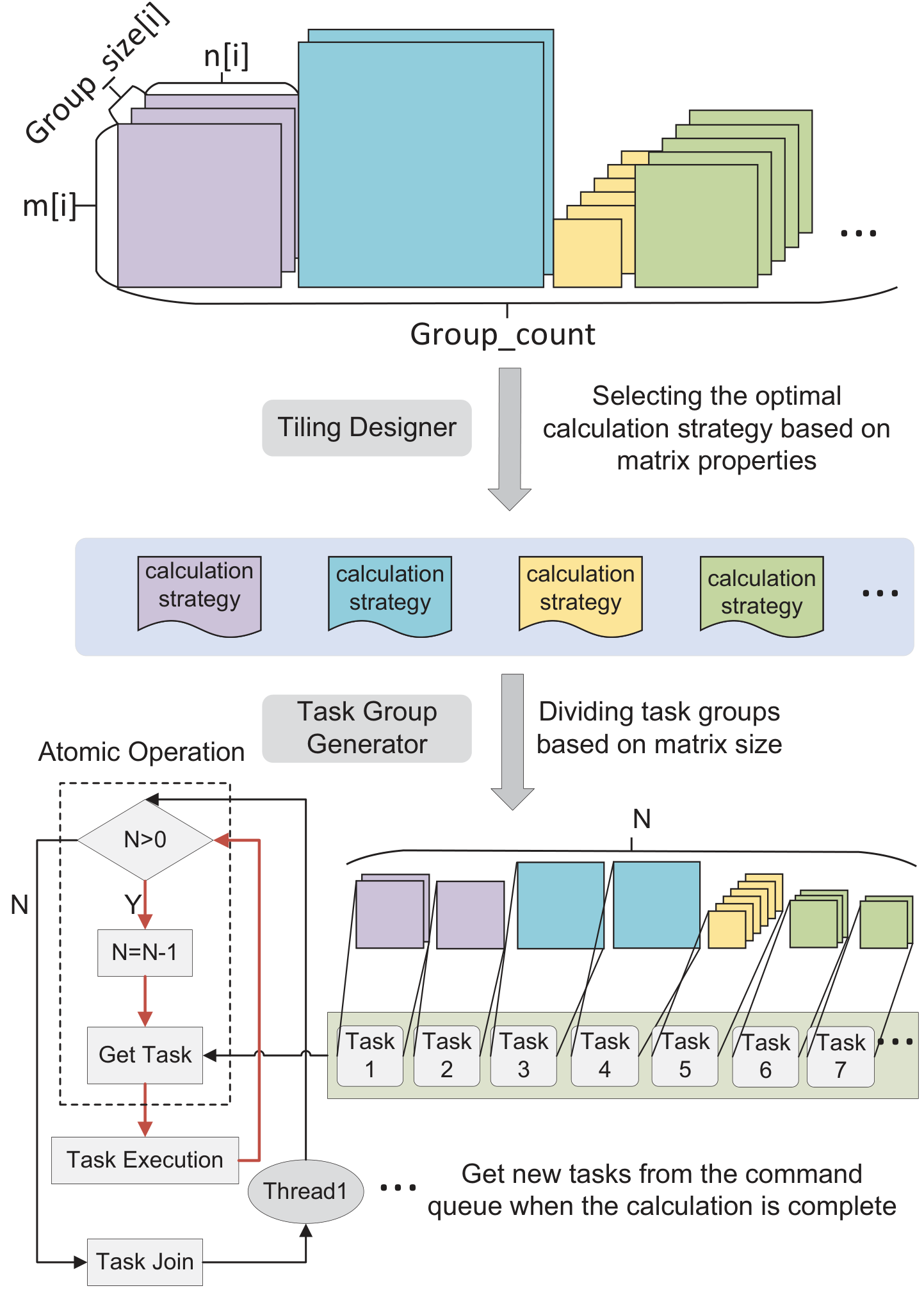
IrGEMM extracts the typical compute patterns of each irregular type into templates, generates "ping-pong" kernels from them, then maps to architecture-specific assembly — so porting to a new CPU only means swapping the multiply/load instructions.
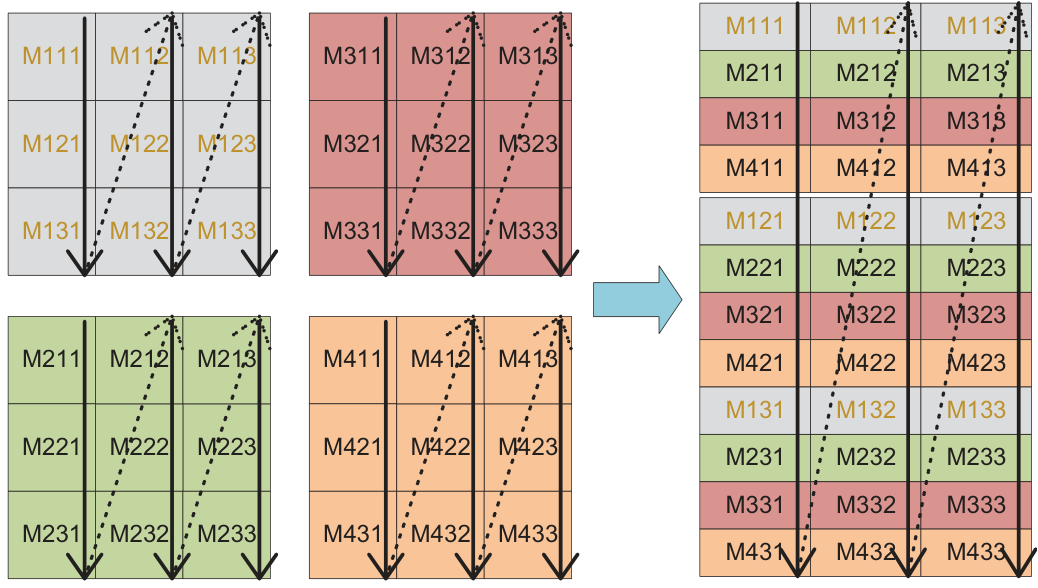
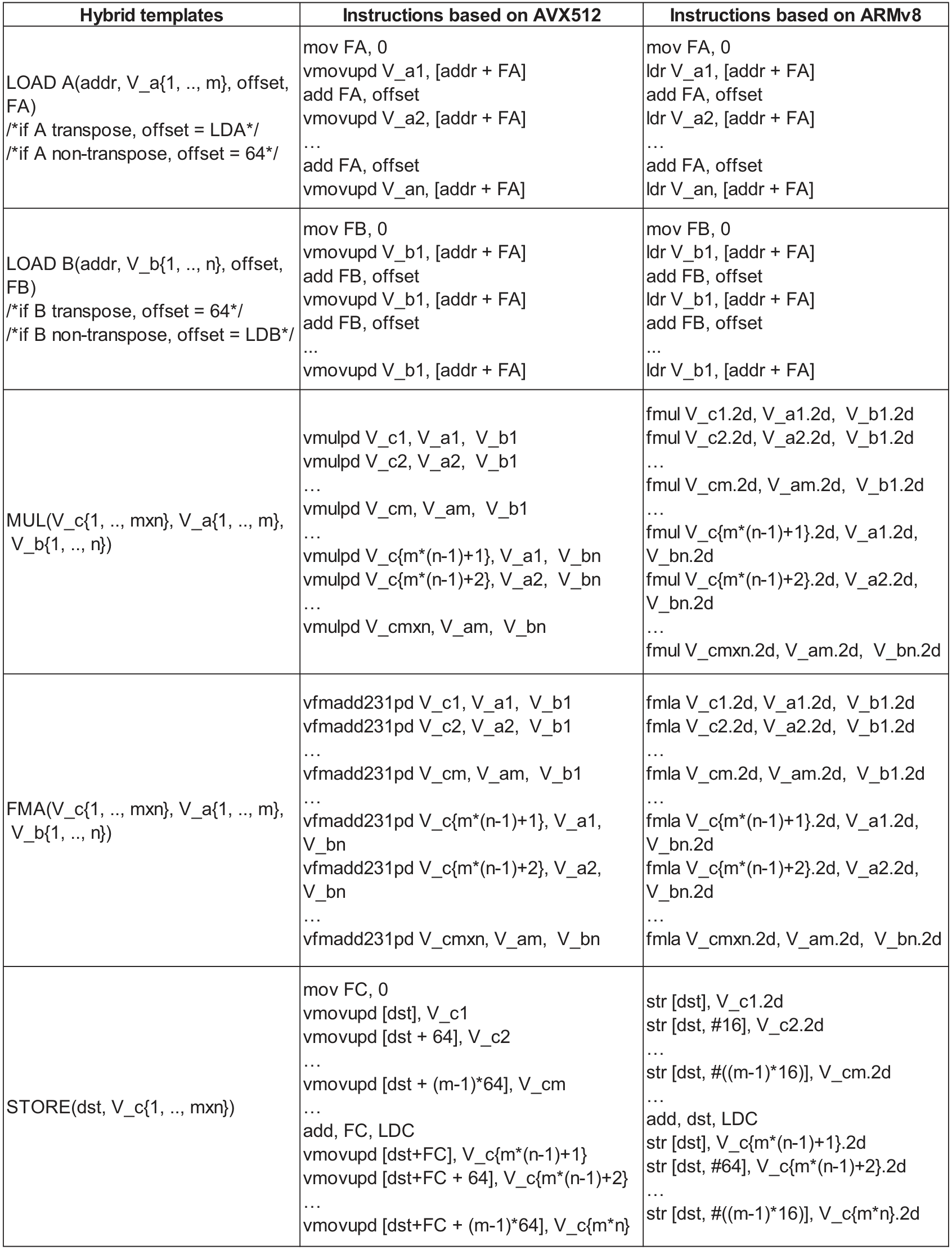
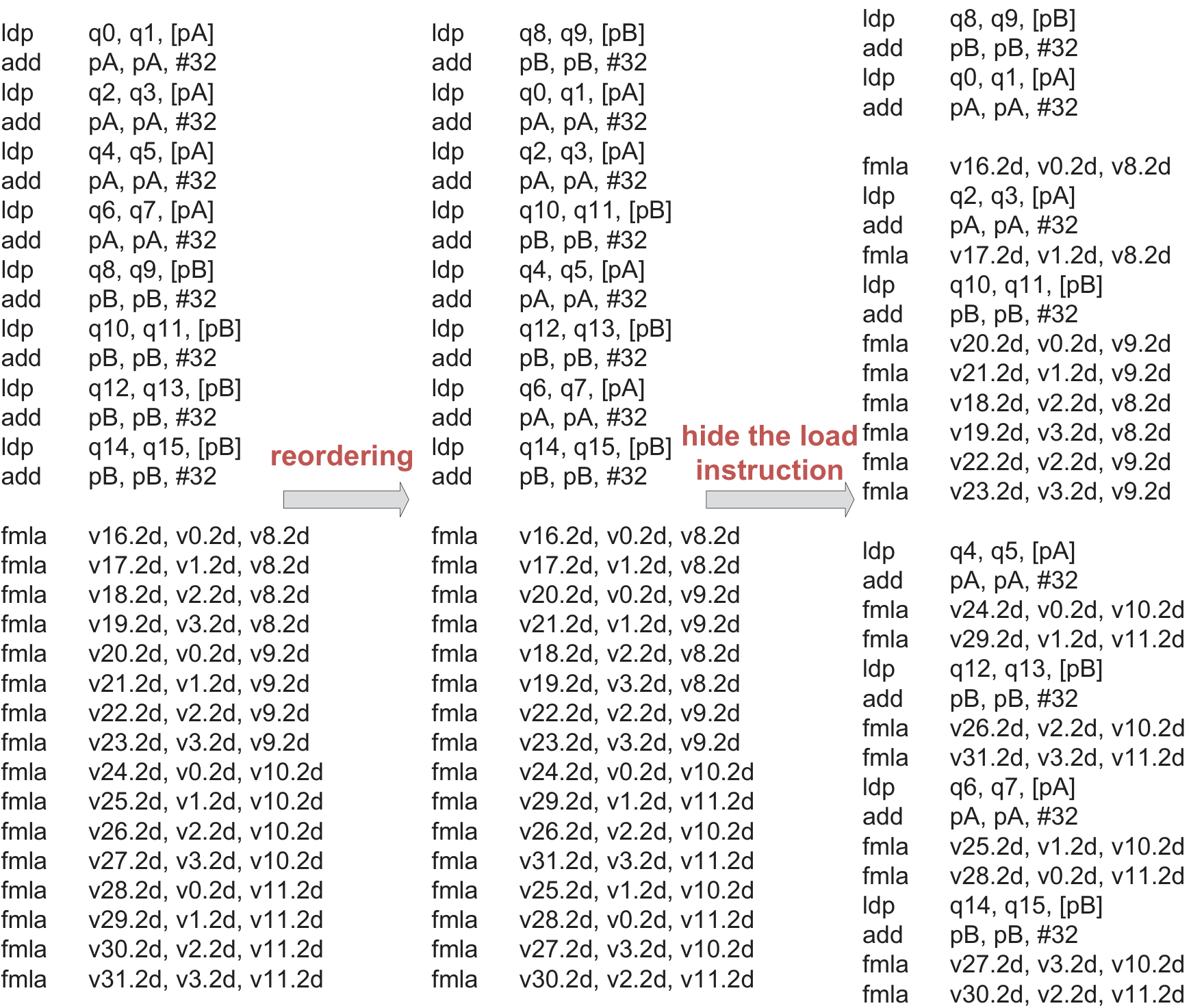
Input-aware Tiling & Scheduling
A dynamic-programming tiling algorithm picks the kernel combination that minimizes memory access and avoids tiny blocks; for Batch GEMM, a load-balanced scheduler maps task groups to threads.
Performance on ARMv8 & X86
Evaluated on Kunpeng 920 (ARMv8.2, 48 cores) and Intel Xeon Gold 6240 (Cascade Lake, 18 cores) against MKL, ARMPL, BLIS, LIBXSMM, and OpenBLAS.
Batch GEMM — multi-threaded
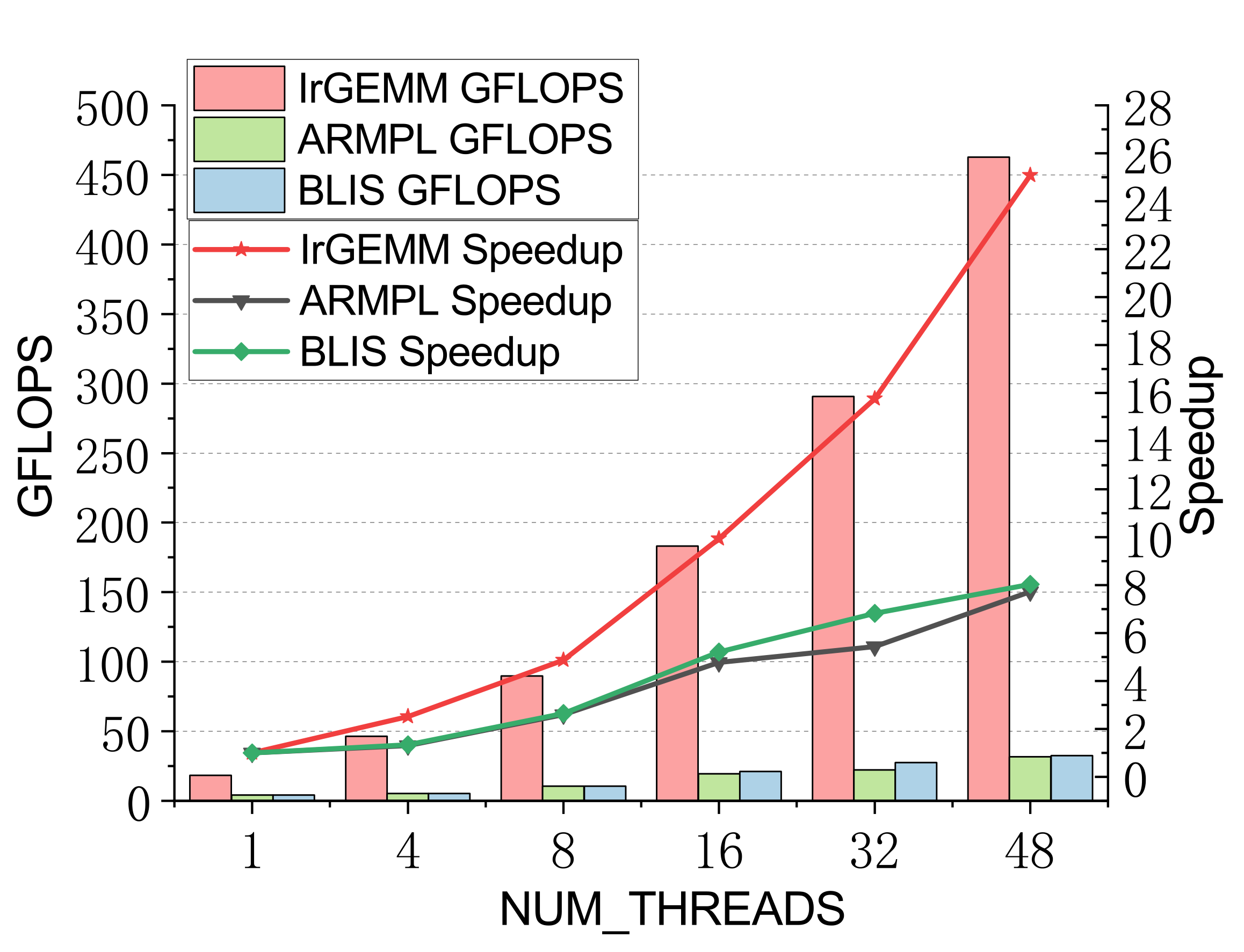
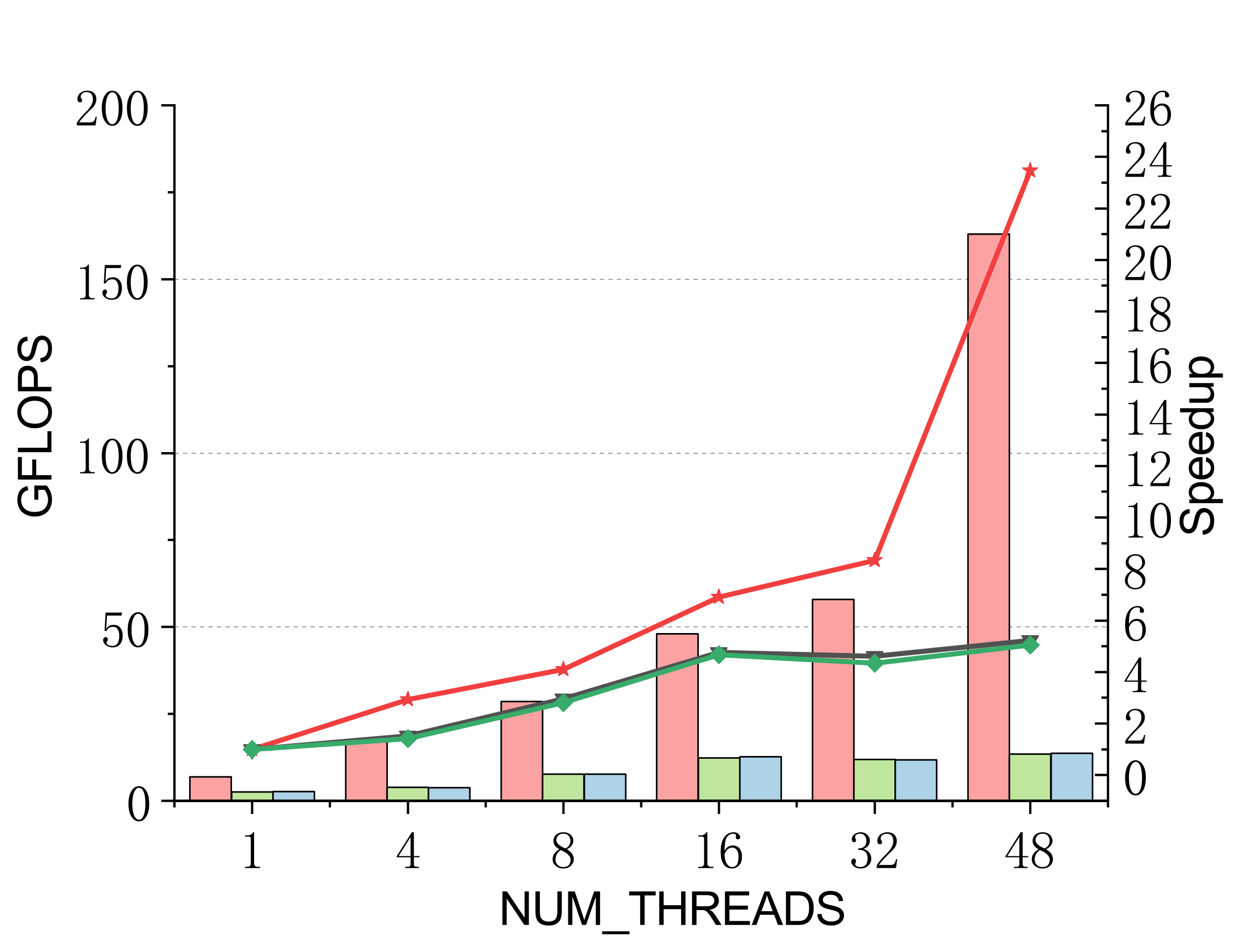
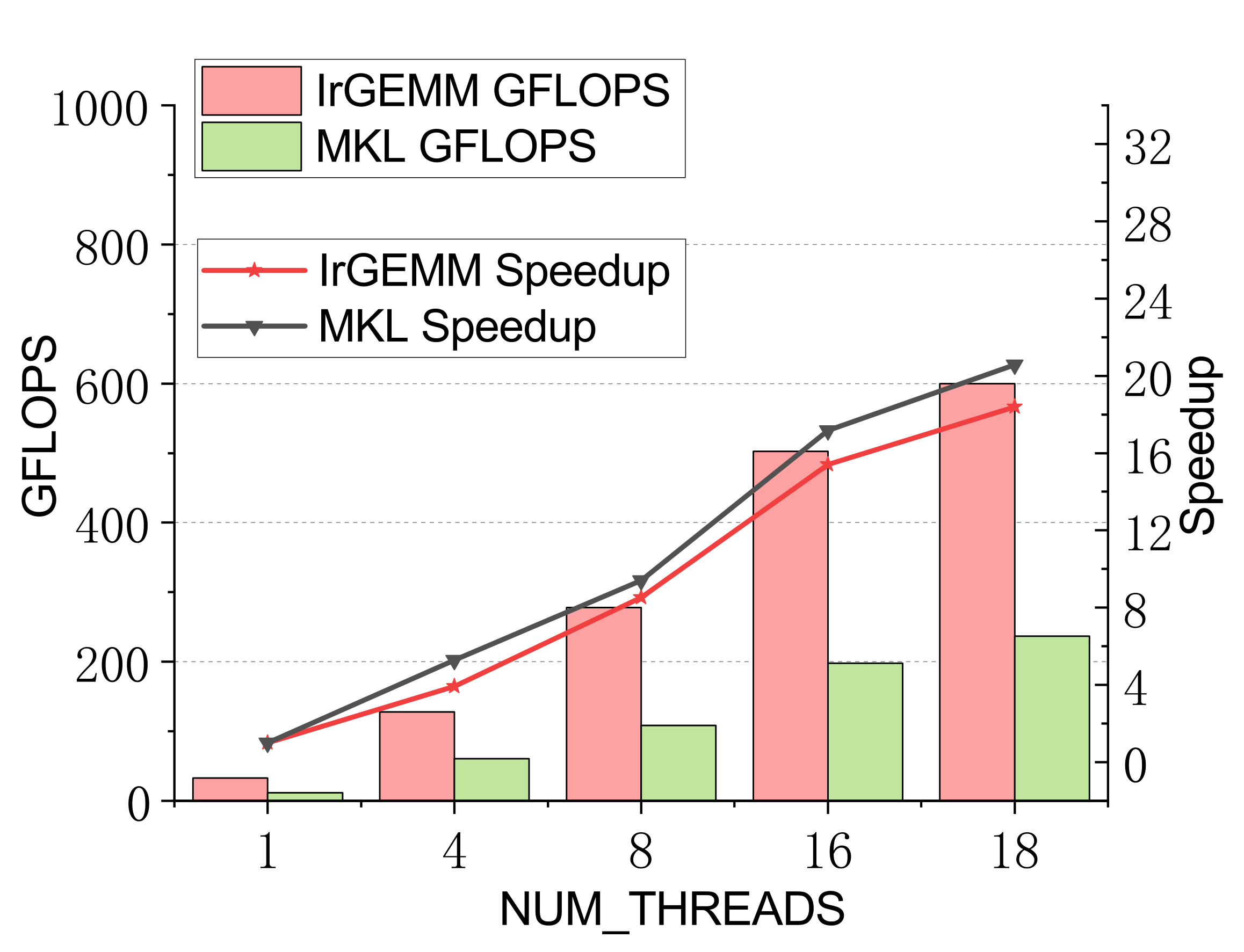
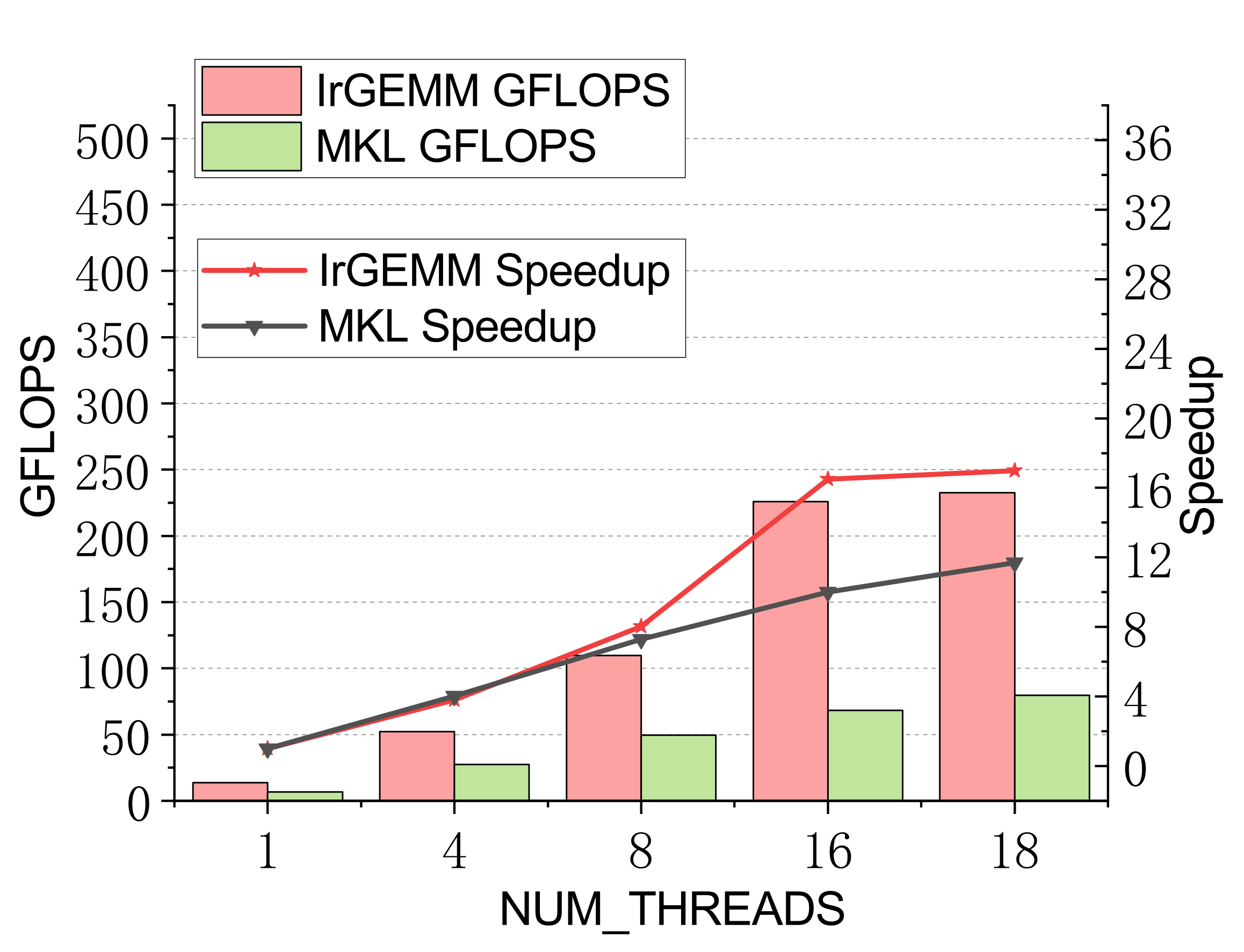
Compact GEMM (NN mode)
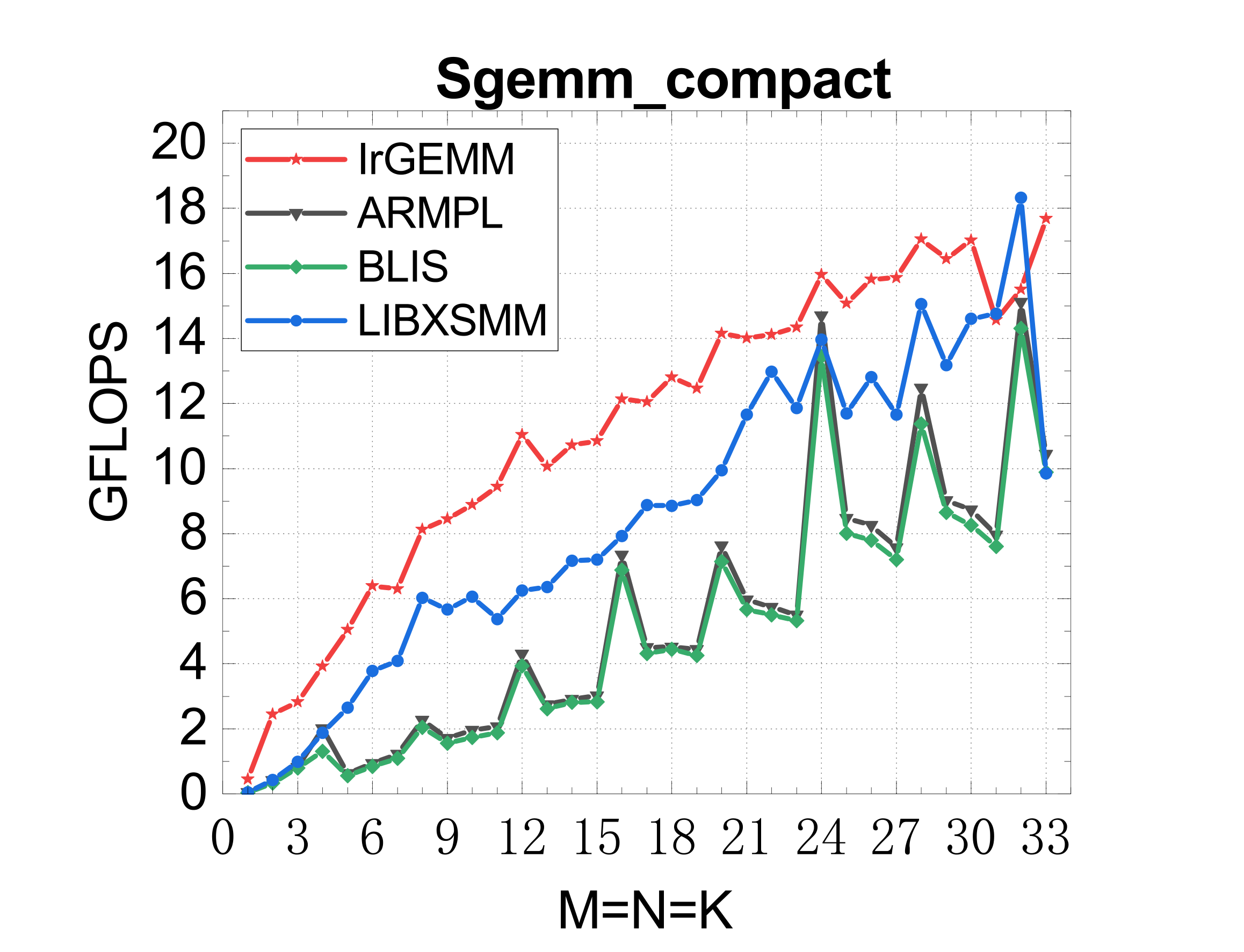
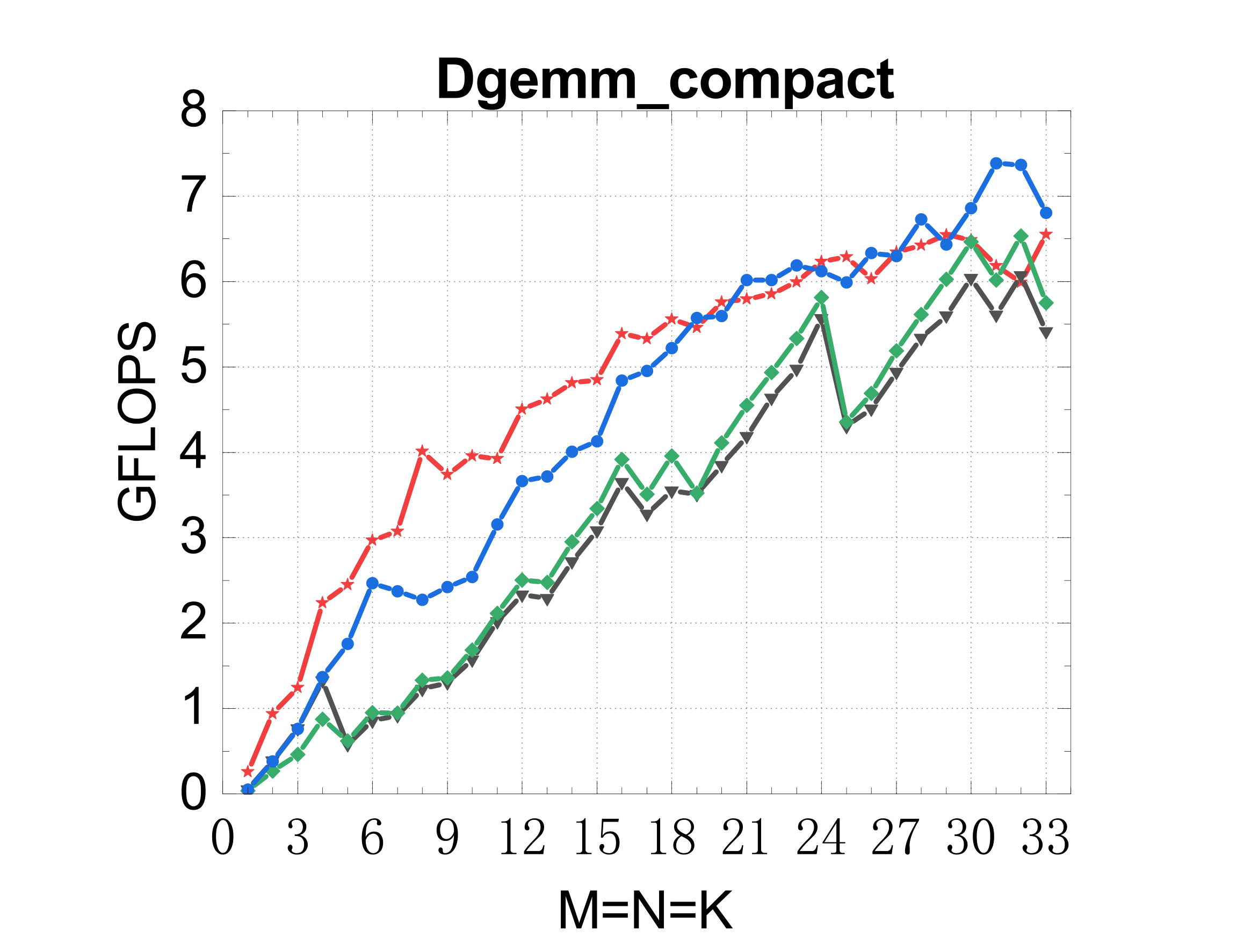
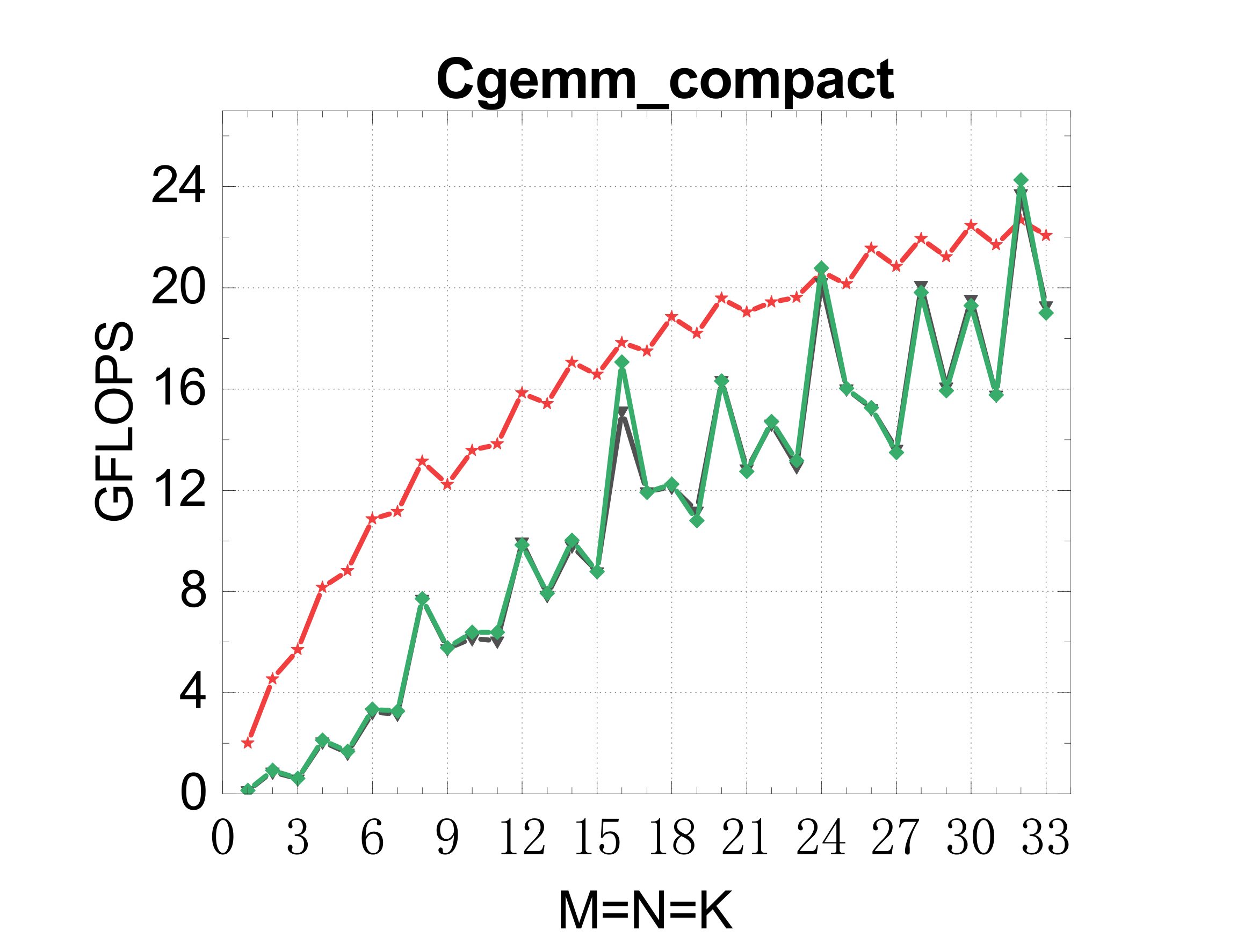
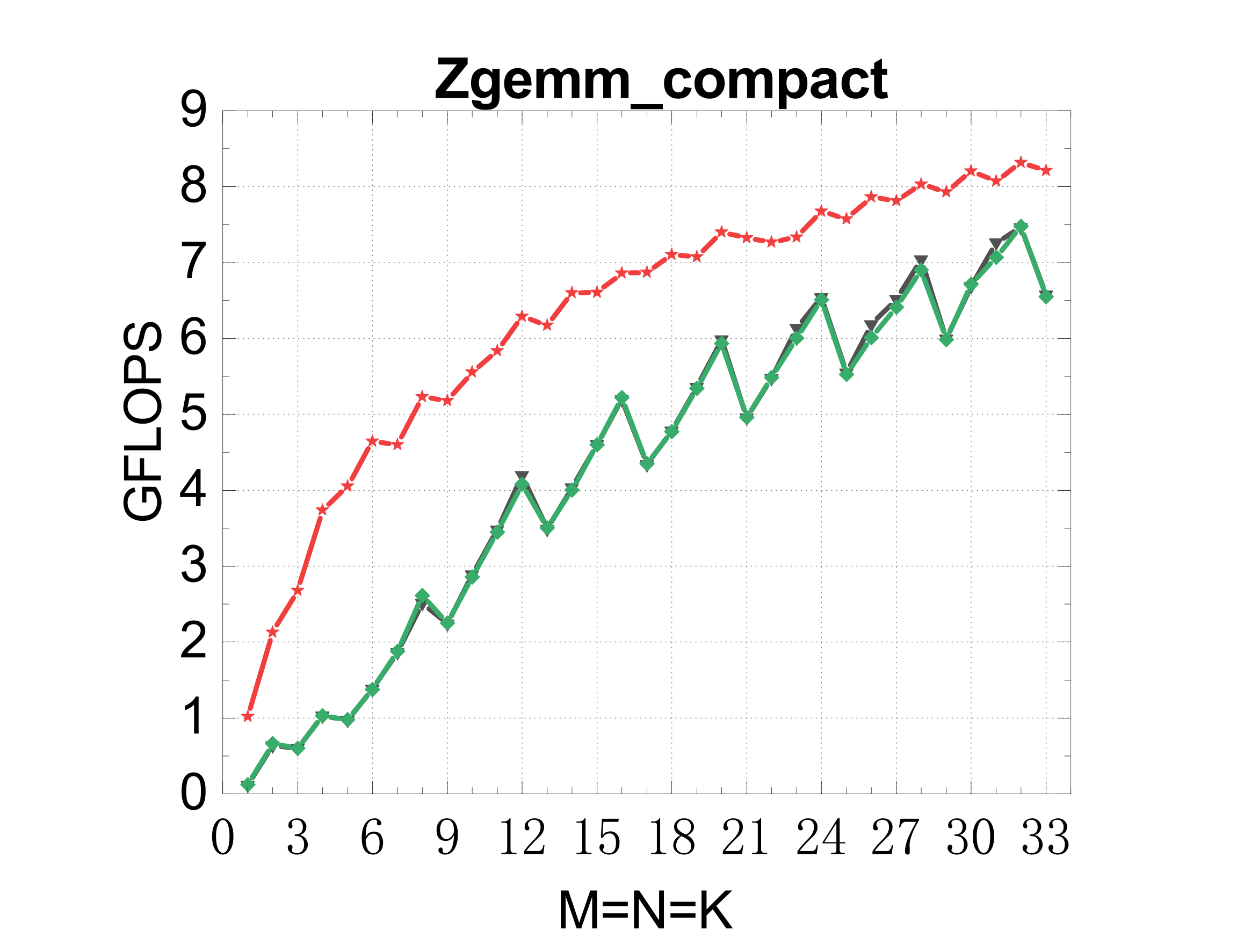
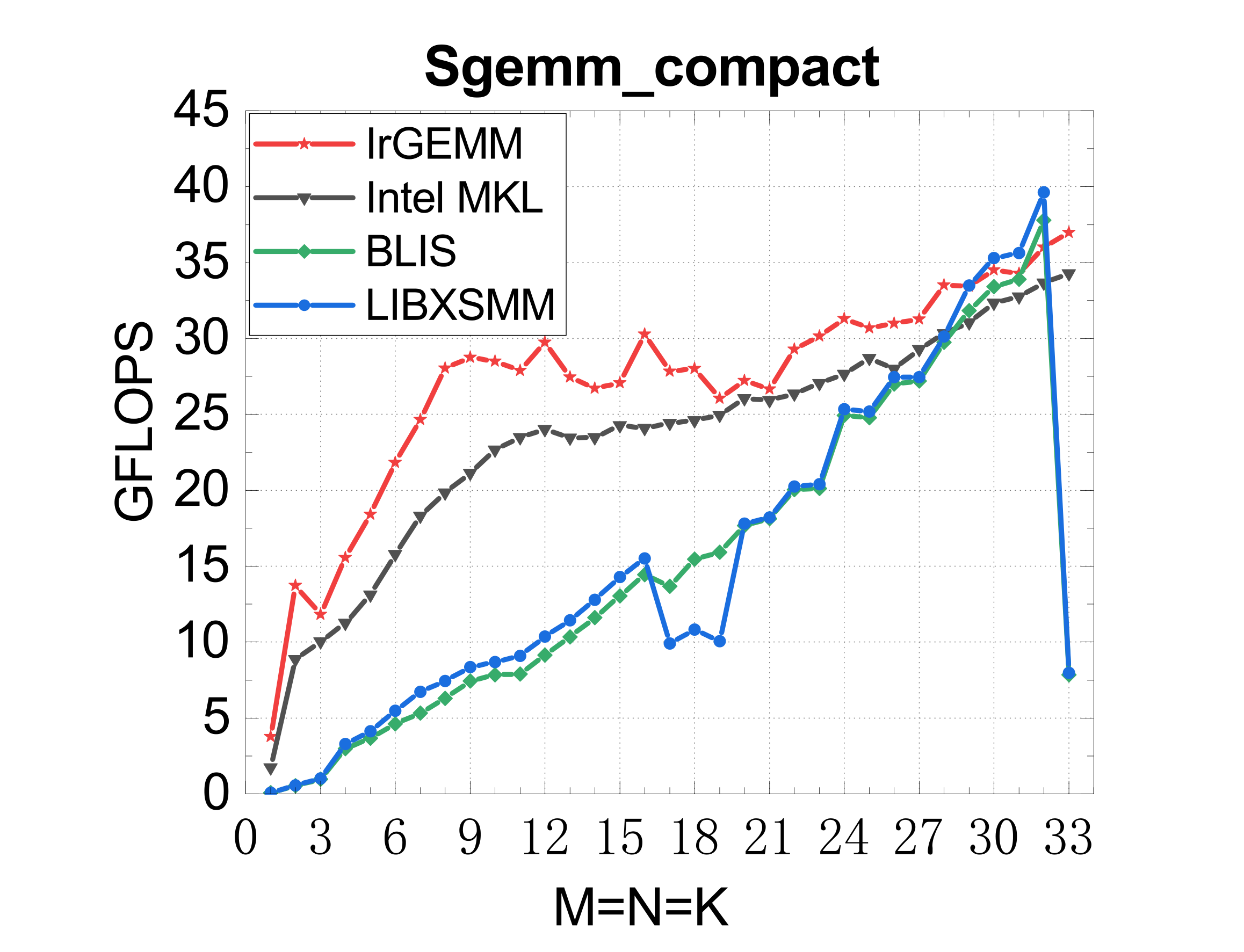
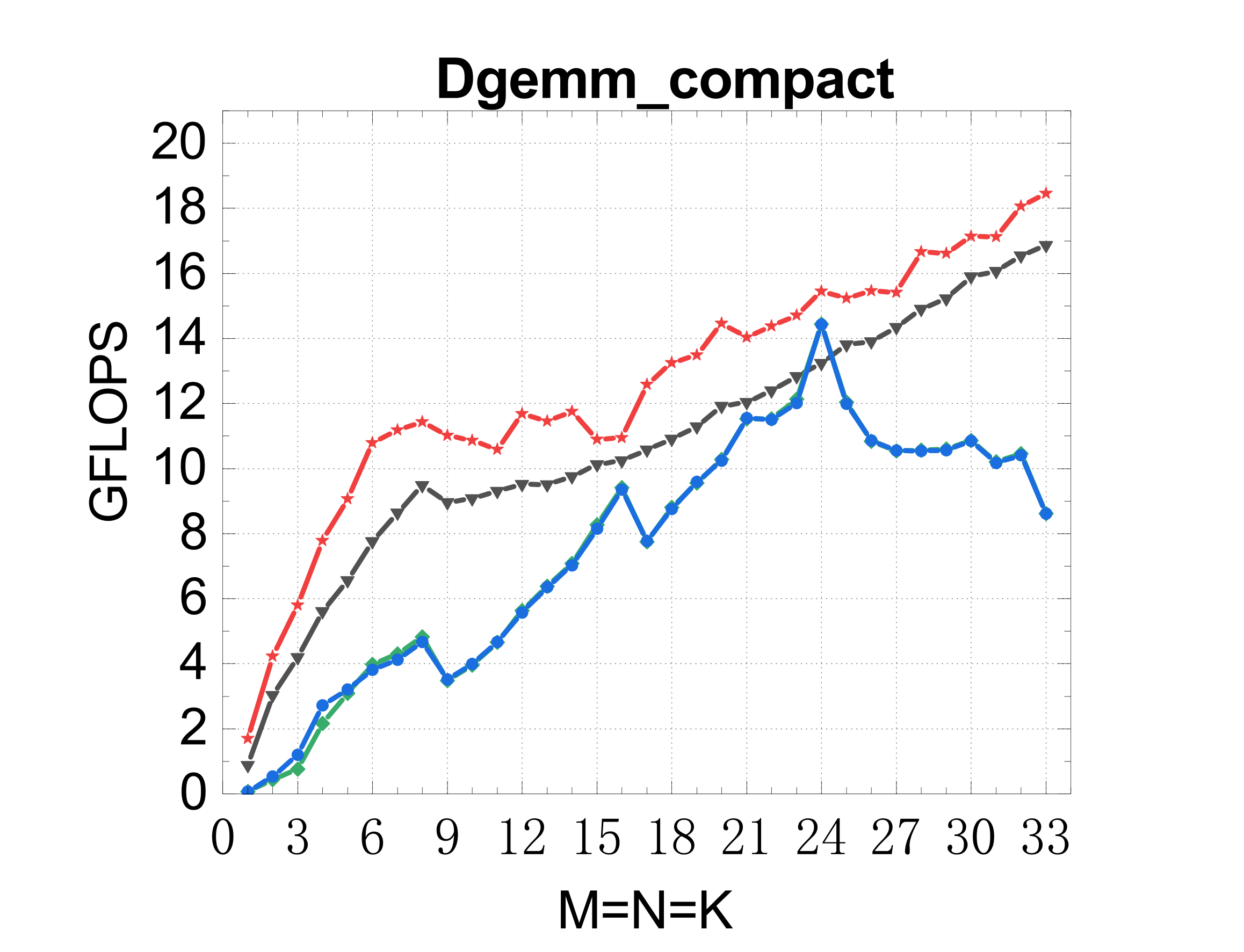
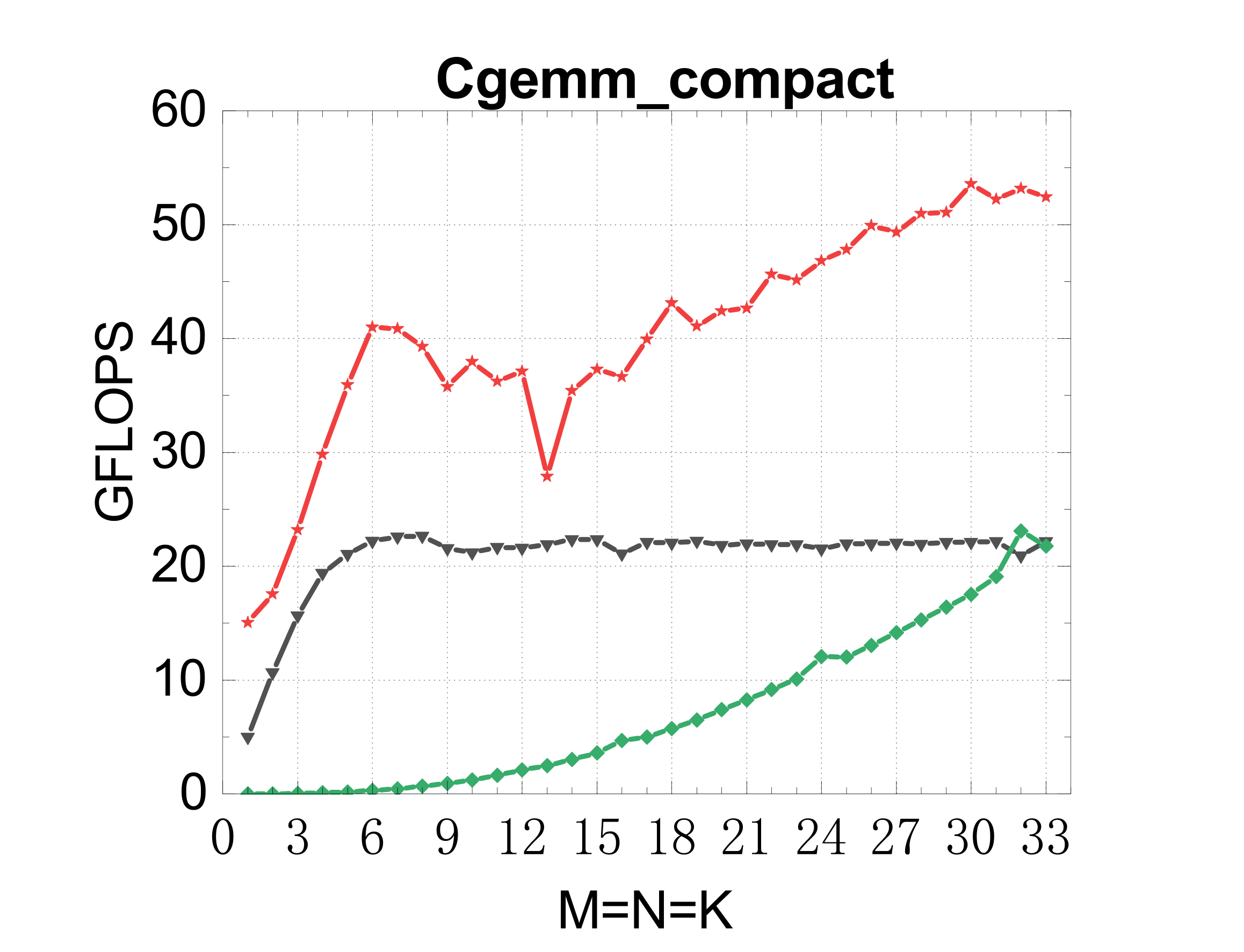
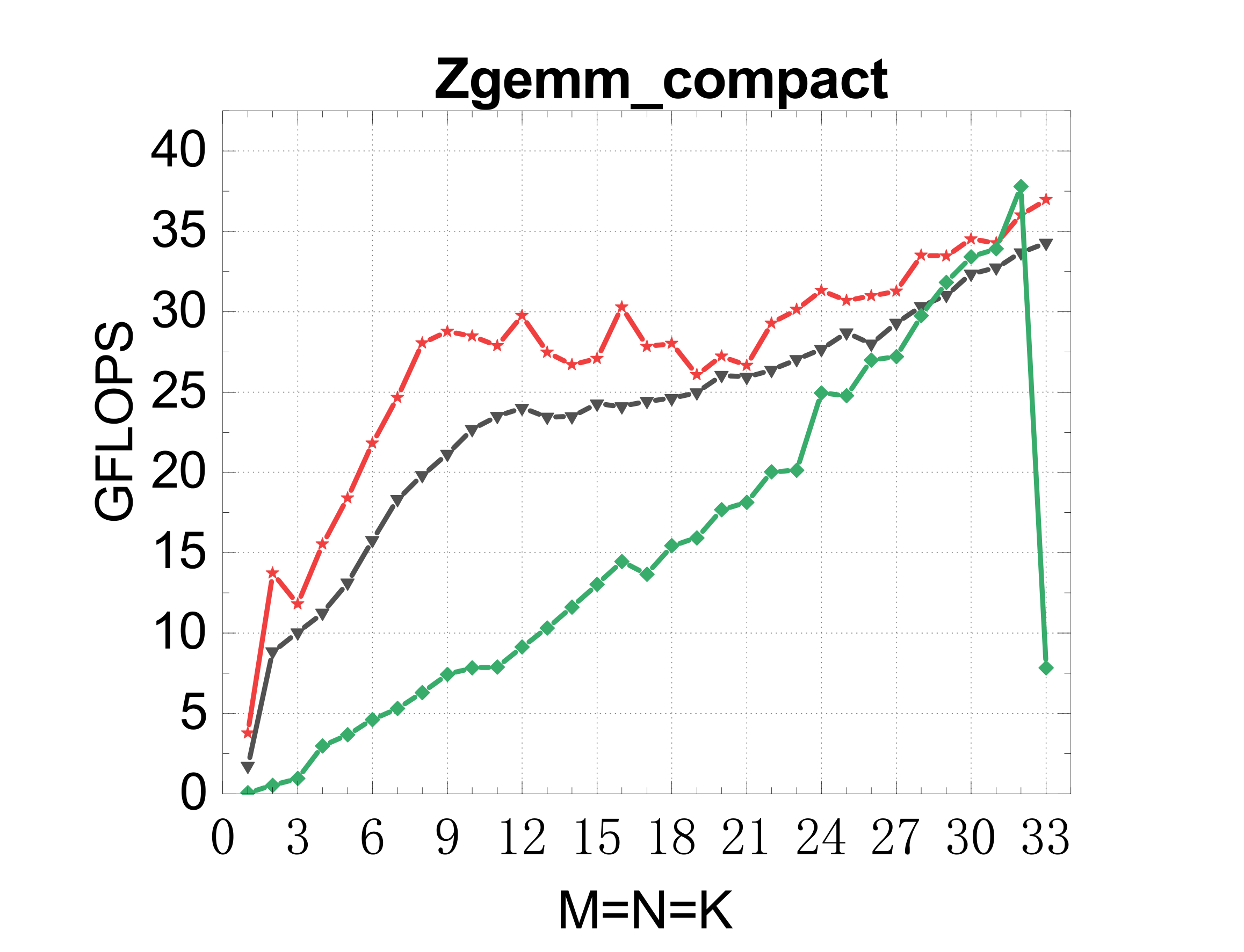
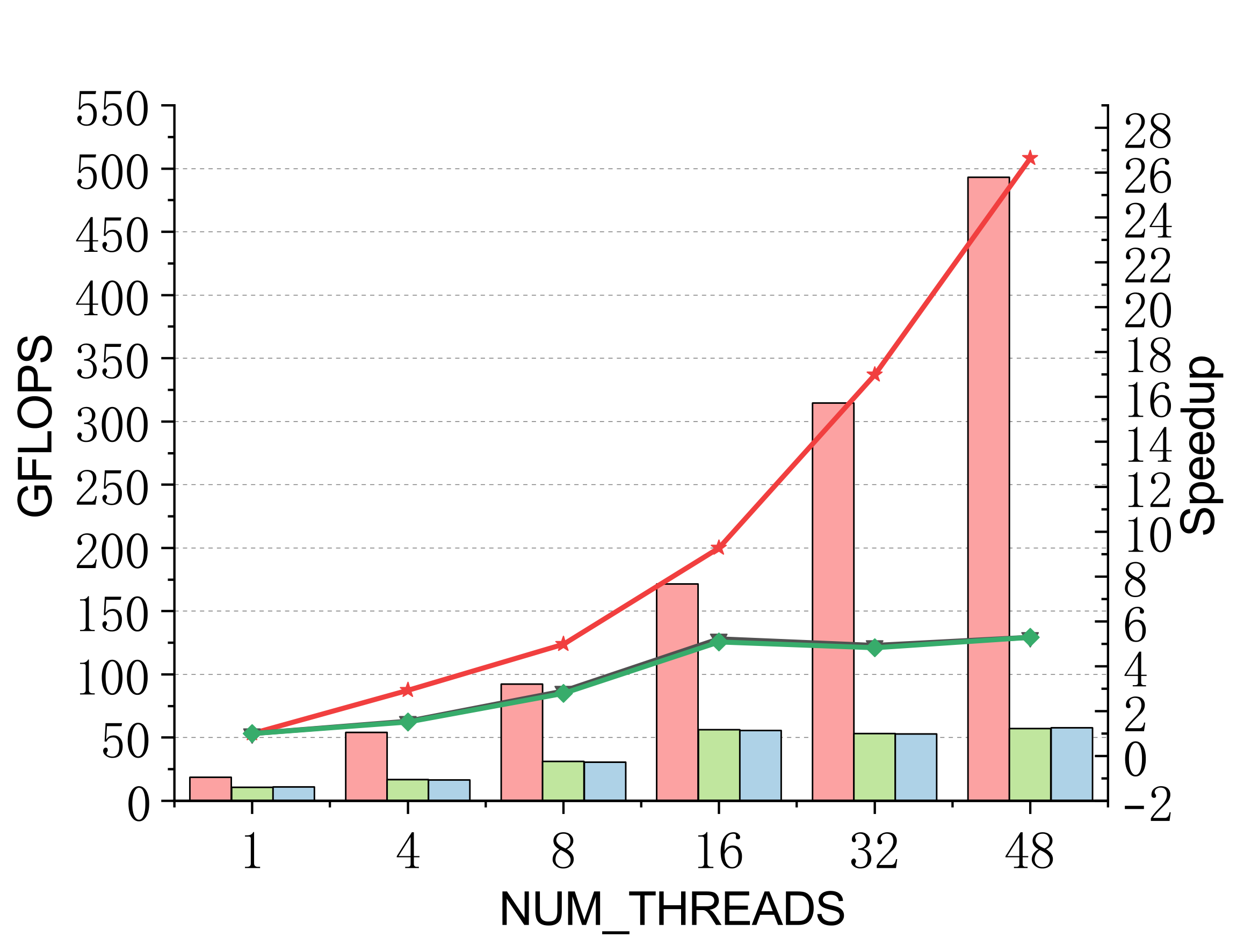
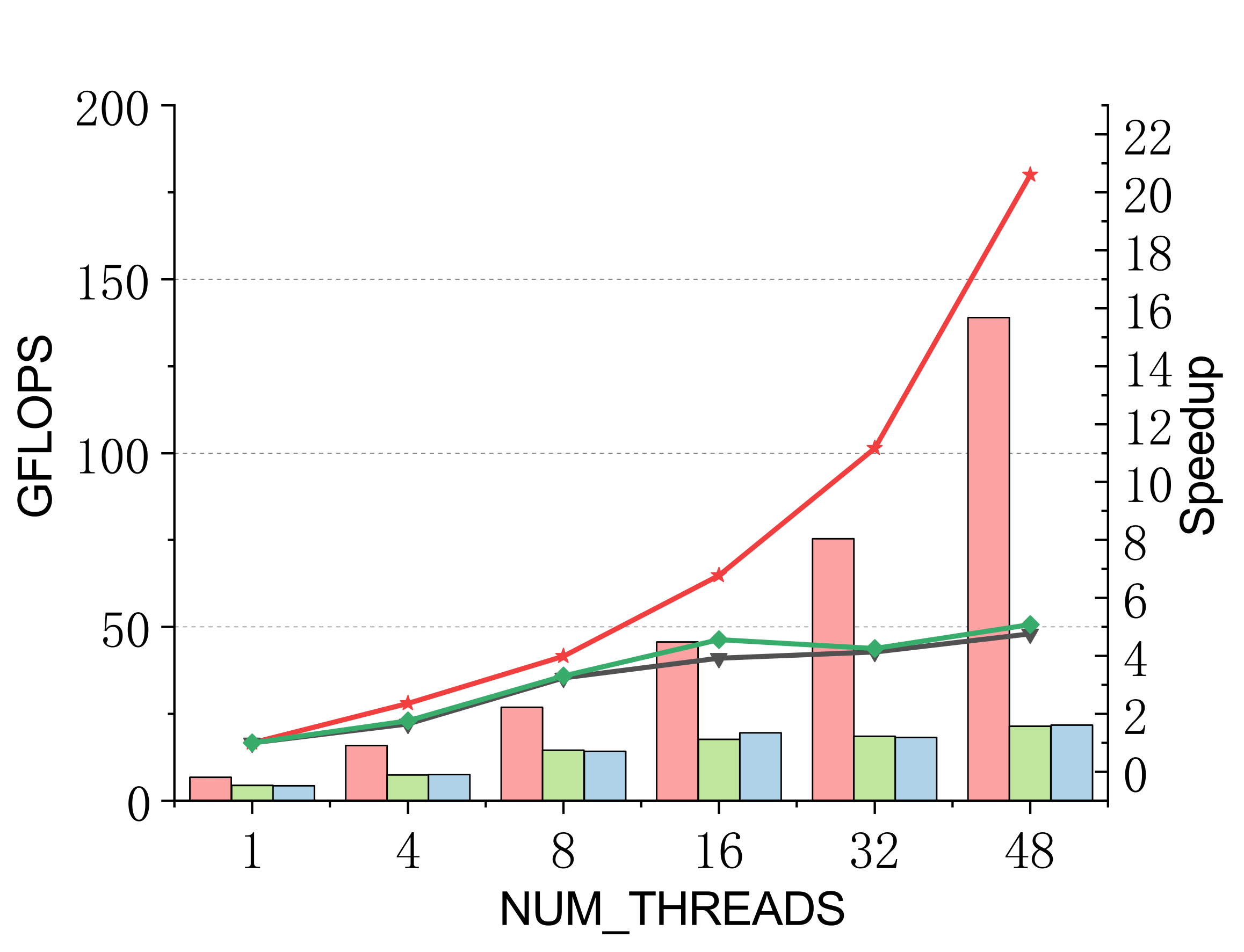
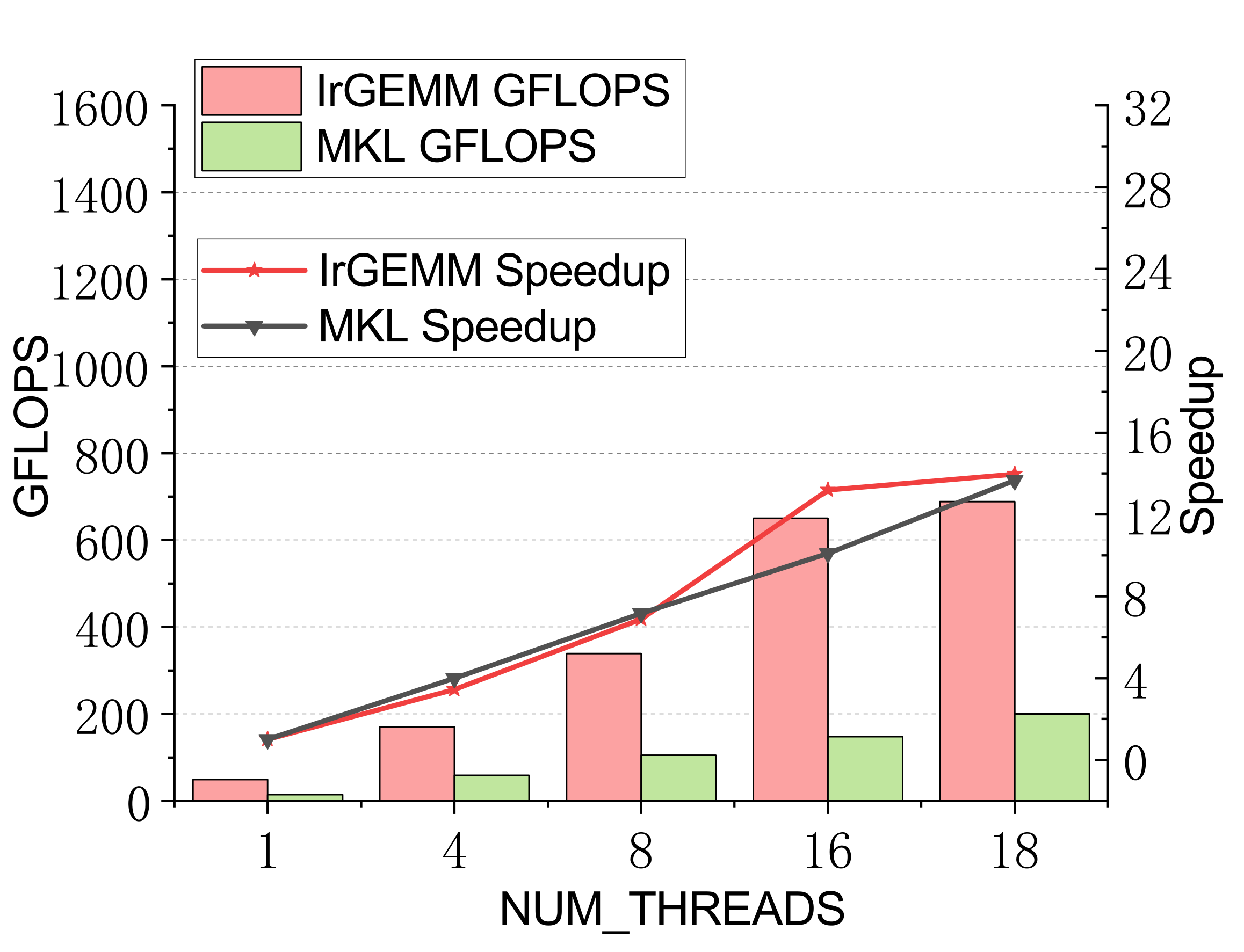
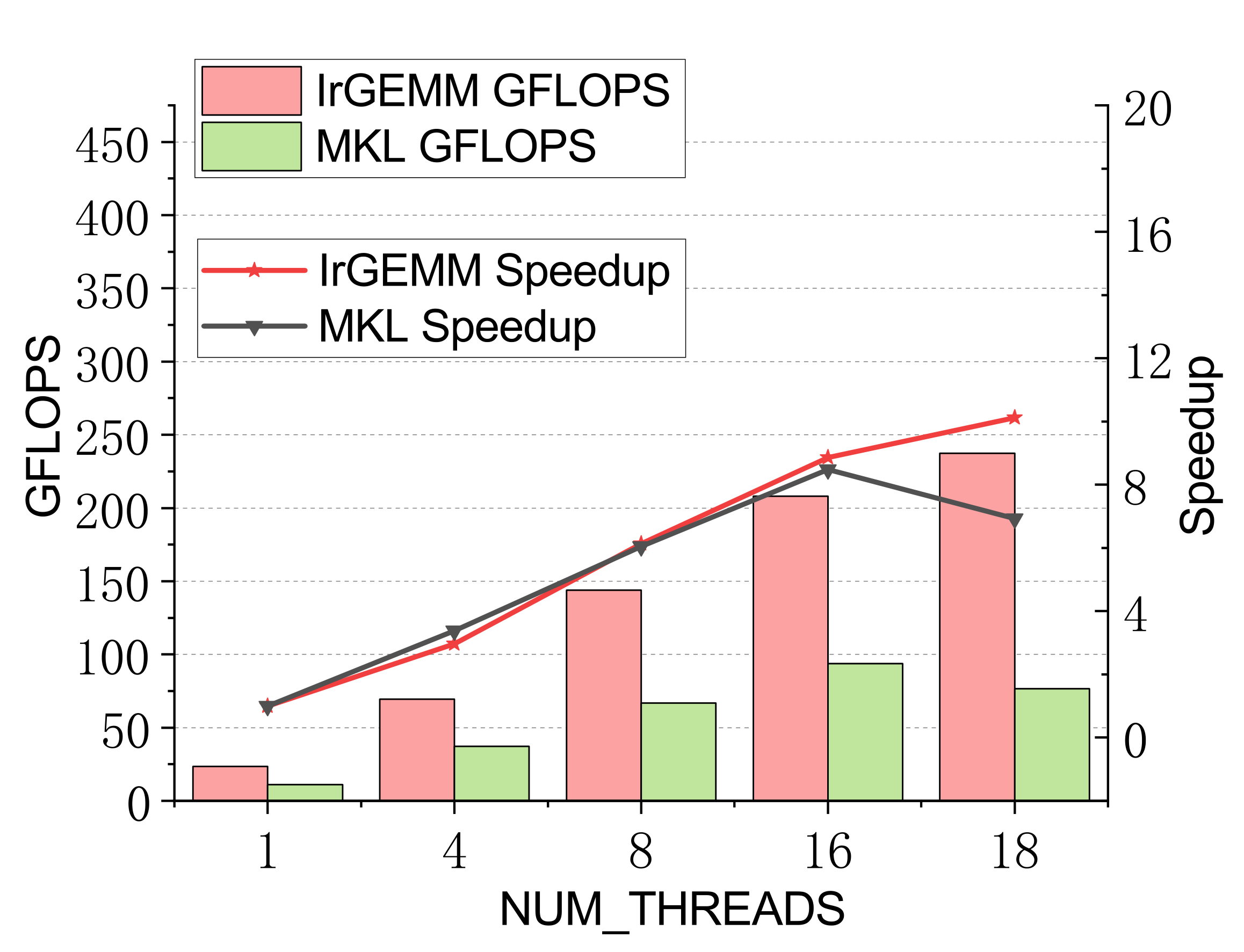
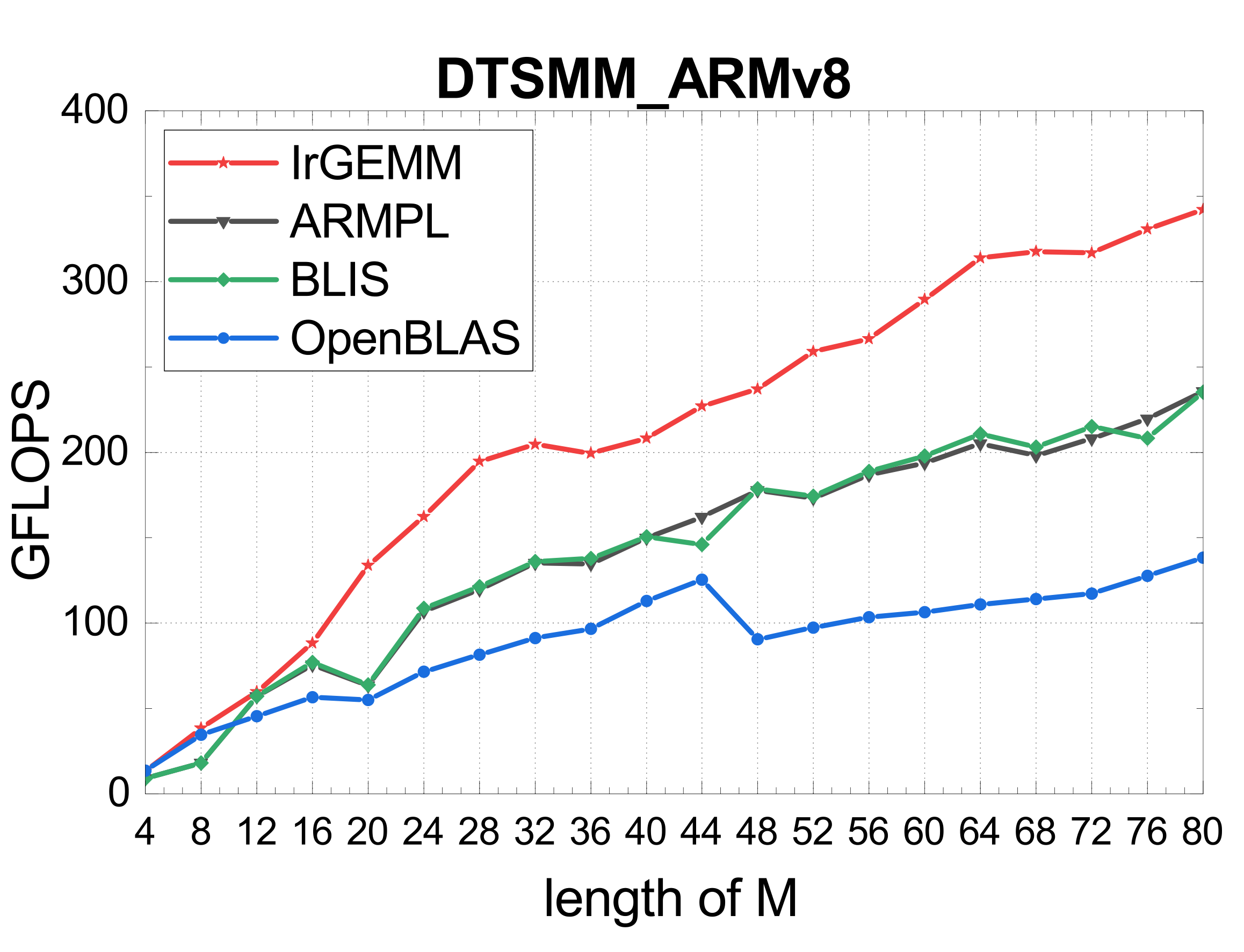
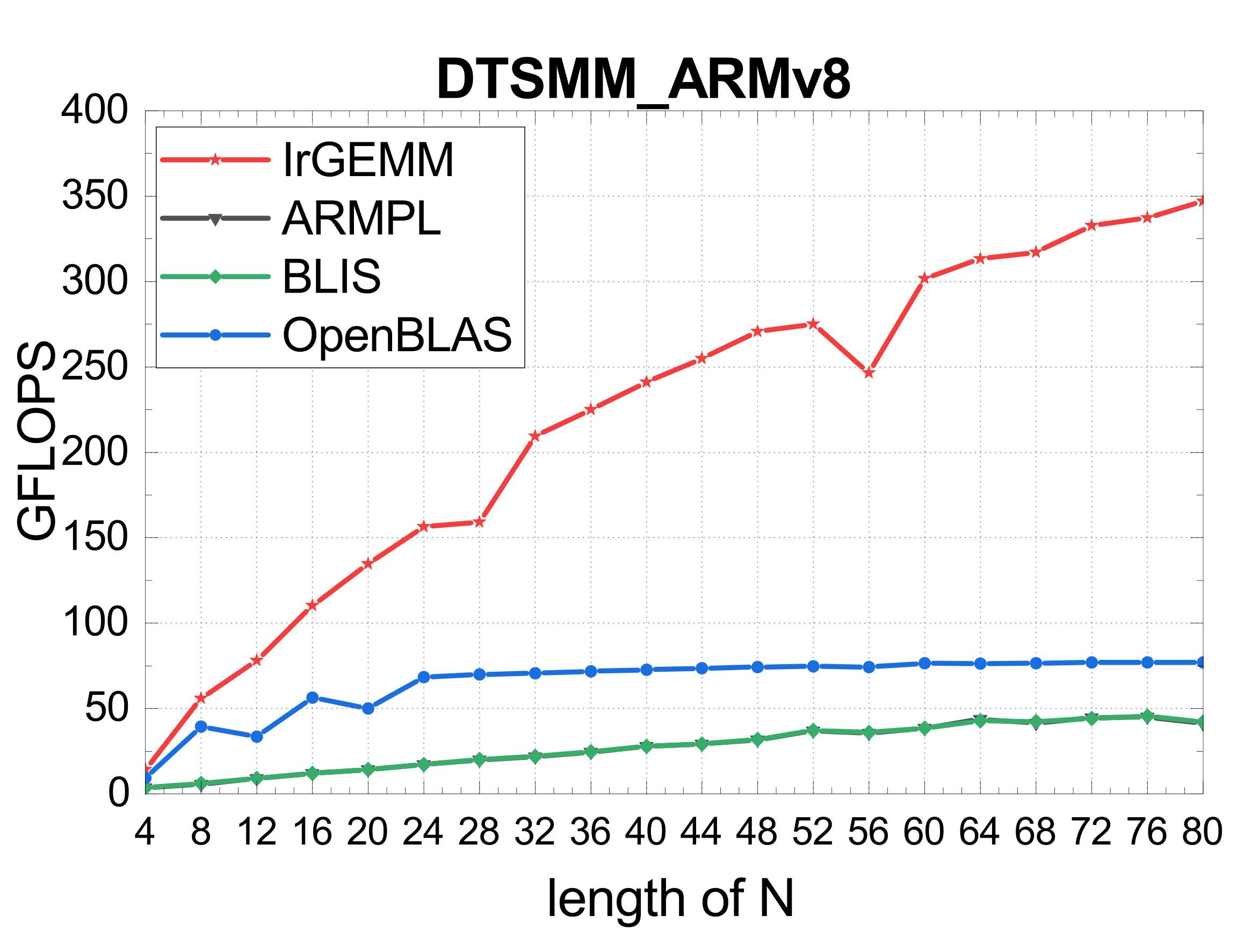
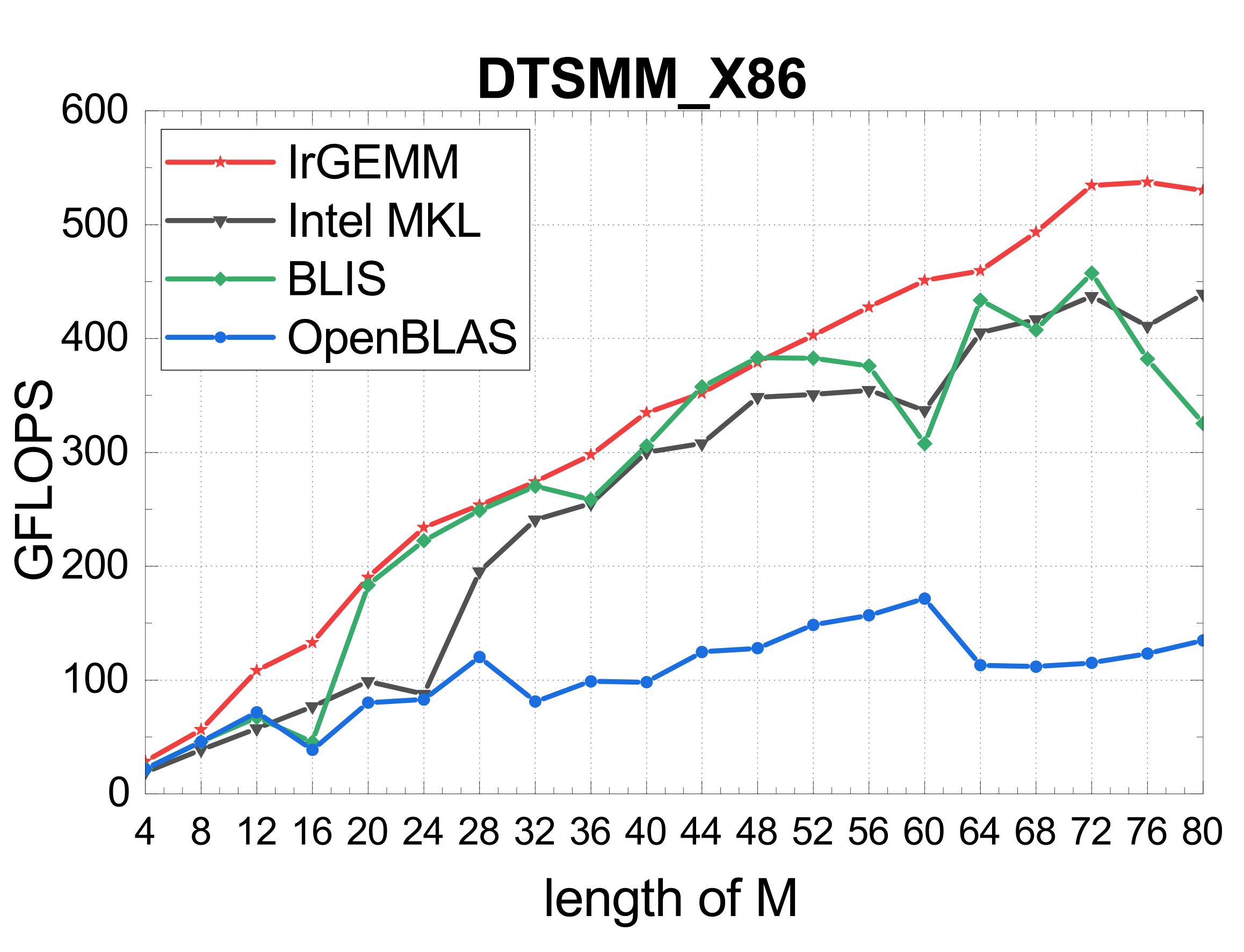
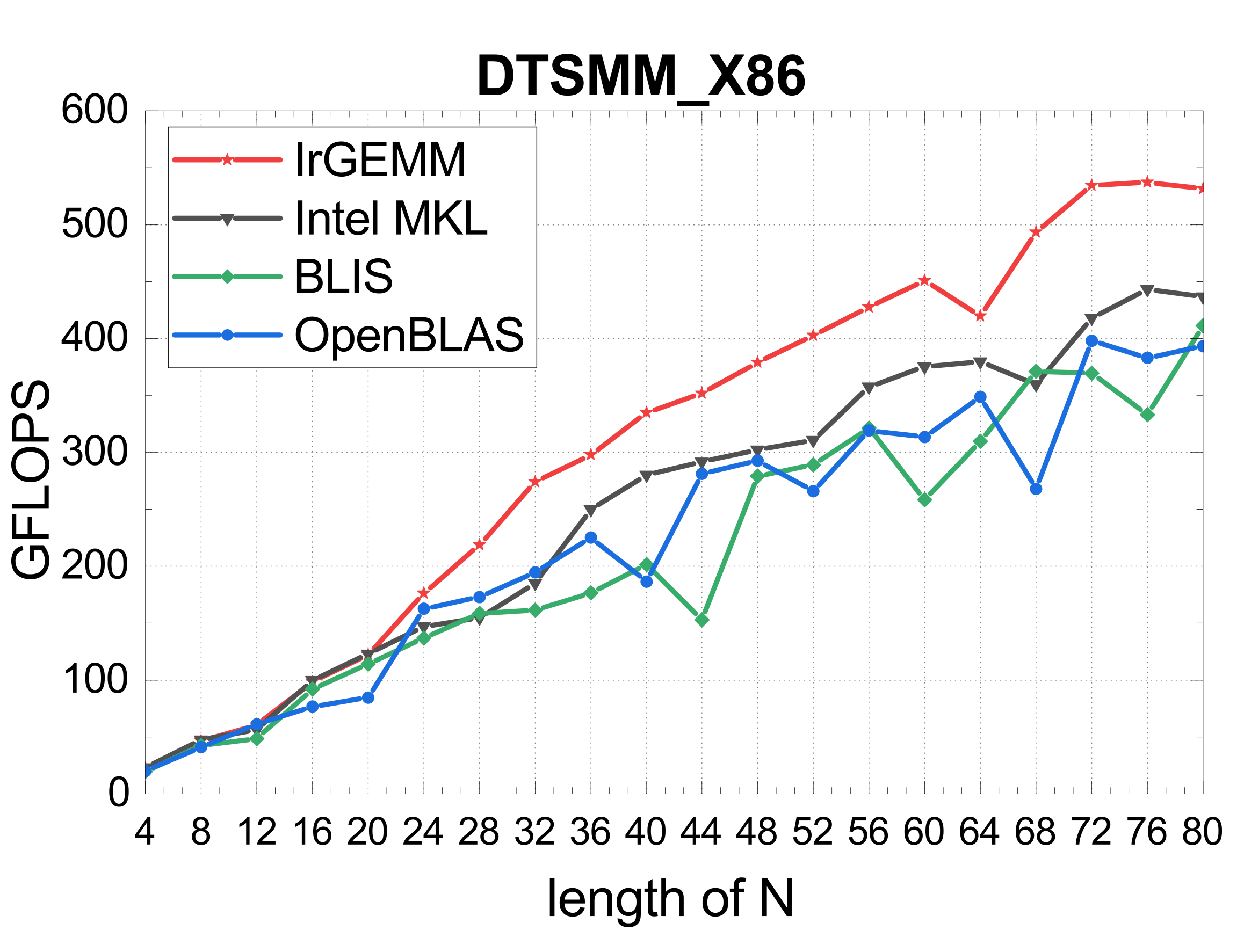
TSMM (multi-threaded)
Bottom line
Irregular GEMM is limited by both the architecture and its diverse application scenarios. IrGEMM unifies Batch GEMM, Compact GEMM, and TSMM under one input-aware framework — template-based code generation for ARMv8 and X86, a DP-based input-aware tiling algorithm, and load-balanced multi-threading — surpassing MKL, ARMPL, BLIS, LIBXSMM, and OpenBLAS across all three irregular types on both architectures.
BibTeX
@article{wei_irgemm,
title = {IrGEMM: An Input-Aware Tuning Framework for Irregular
GEMM on ARM and X86 CPUs},
author = {Wei, Cunyang and Jia, Haipeng and Zhang, Yunquan and
Yao, Jianyu and Li, Chendi and Cao, Wenxuan},
journal = {IEEE Transactions on Parallel and Distributed Systems
(TPDS)},
note = {ICT, Chinese Academy of Sciences}
}