Abstract
Modern HPC increasingly decomposes one large linear-algebra problem into many small ones solved independently. While dense GEMM is near-peak, batch operations on small matrices are not — and small-GEMM kernel optimization and load-balanced scheduling on ARM remain under-studied. We present LBBGEMM, a load-balanced batch GEMM framework for large groups of variable-size small GEMM on ARMv8.
At install time, LBBGEMM analyzes each transpose mode to build high-performance small-GEMM kernels without data packing, cutting memory-access overhead, with careful instruction scheduling and selection. At run time, a tiling designer plus a pre-grouped dynamic scheduling algorithm split the work into task groups that are dynamically mapped to threads as command queues — greatly improving multi-thread speedup over mainstream BLAS libraries.
Key Contributions
Auto-tuned small GEMM
An auto-tuning algorithm that delivers optimal performance for any input matrix property — designing no-packing kernels and optimizing every possible boundary size per transpose mode.
Load-balanced scheduling
A pre-grouped, dynamic thread↔task mapping that turns uneven matrix groups into balanced command queues — dramatically improving multi-core speedup.
The LBBGEMM library
A complete batch-GEMM library on ARMv8 (Kunpeng 920) that beats ARMPL and BLIS on single-core and, especially, on multi-thread scaling.
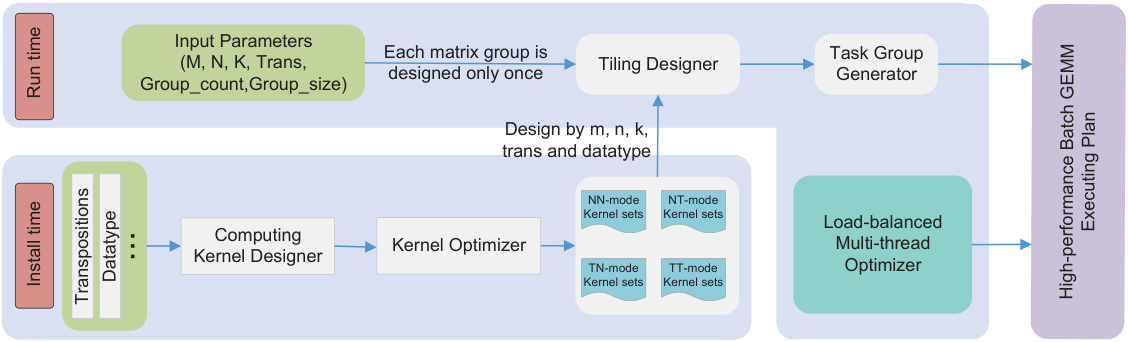
Fast Small-GEMM Kernels, No Packing
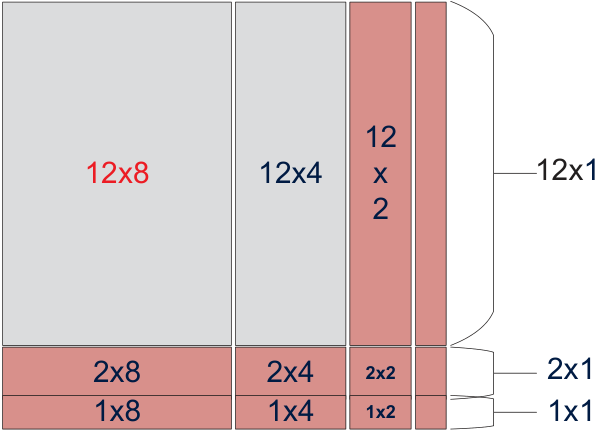
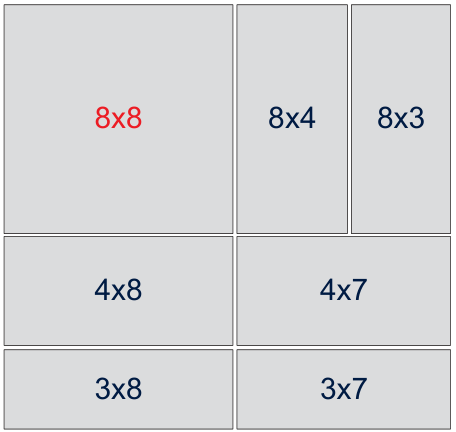
For small matrices, data-packing overhead is large relative to the work. LBBGEMM designs no-packing kernels for each transpose mode, maximizing the compute-to-memory-access ratio and generating every boundary size so the run-time can always pick an efficient fit.
Pre-grouped Dynamic Scheduling
Assigning whole matrix groups to threads causes load imbalance (groups differ in size and count); assigning single matrices causes huge scheduling overhead. LBBGEMM strikes the balance with task groups sized to the L1 cache.
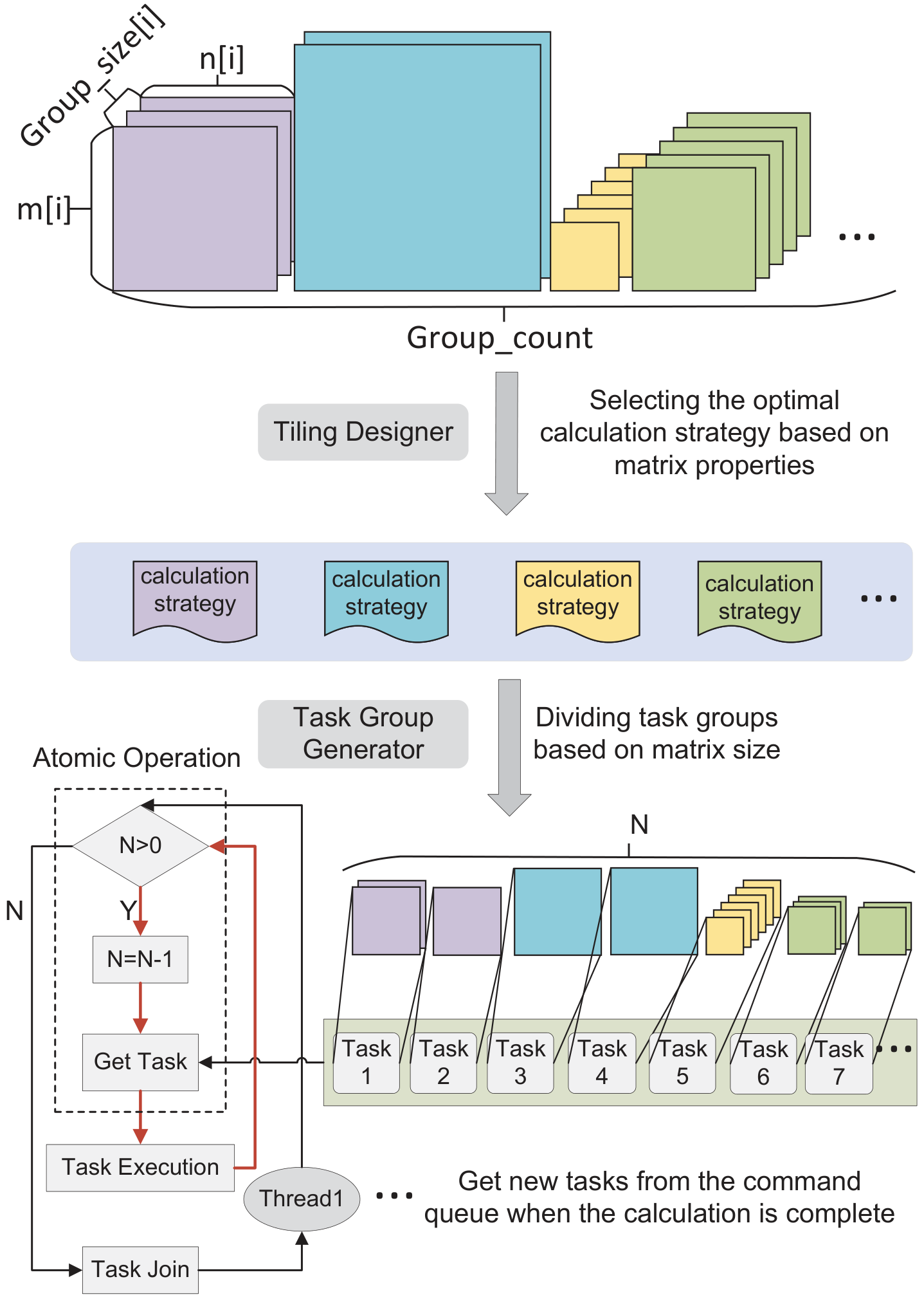
Even with equal compute, larger matrices reach higher efficiency than tiny ones — so equal-work groups still finish at different times. The dynamic thread↔task mapping (atomic counter over the command queue) absorbs this, beating static scheduling and lifting the 48-thread scaling ratio far above ARMPL/BLIS.
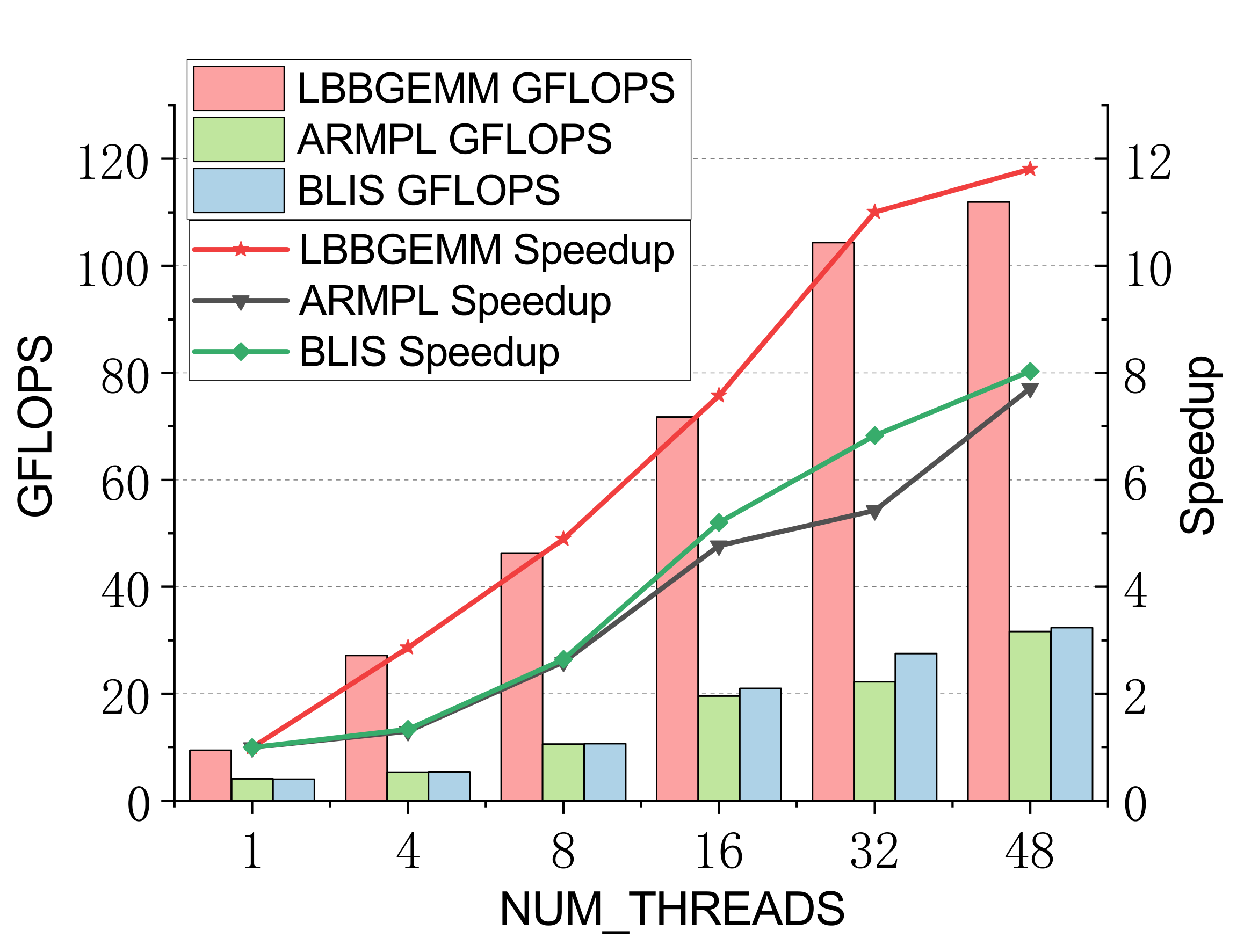
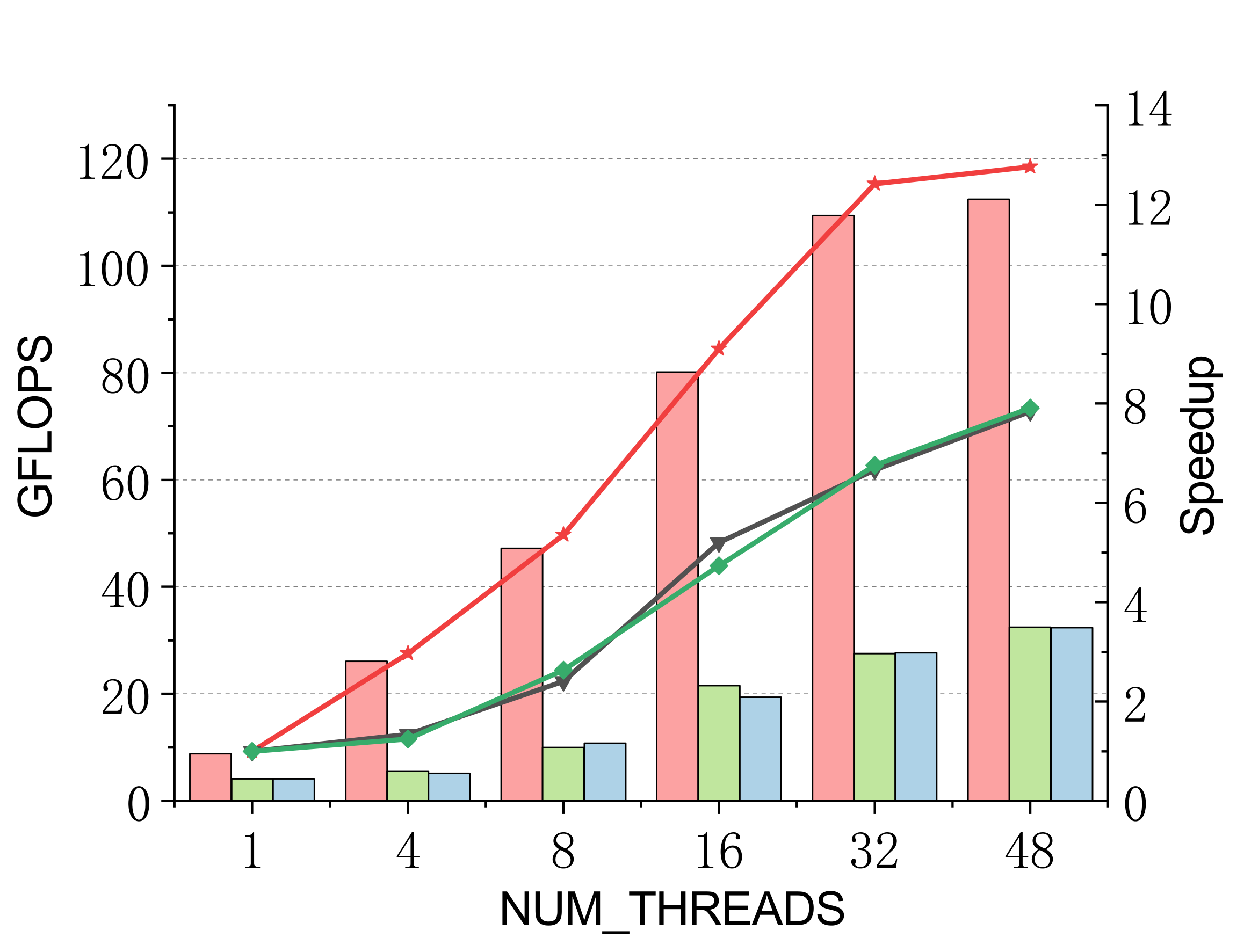
Performance on Kunpeng 920
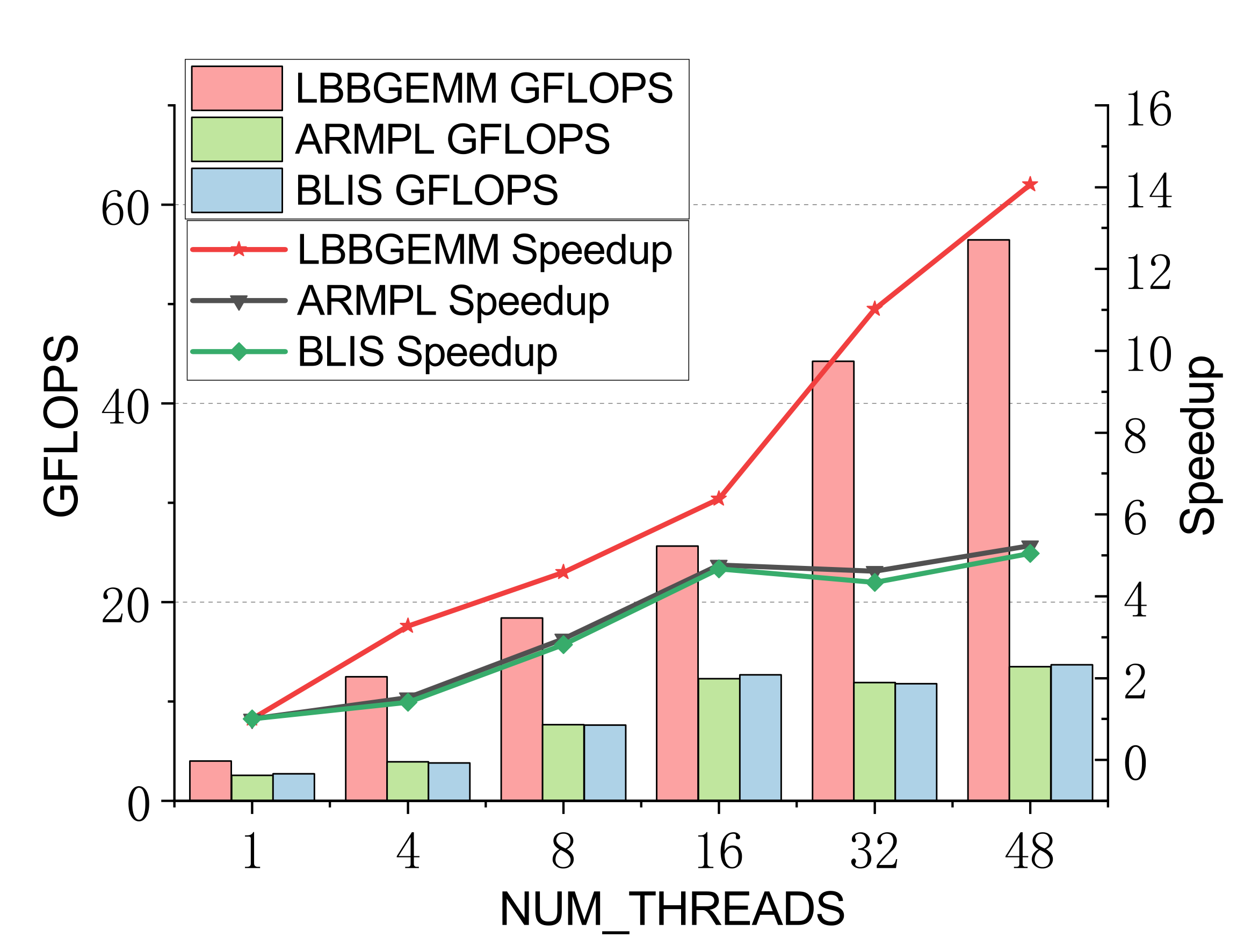
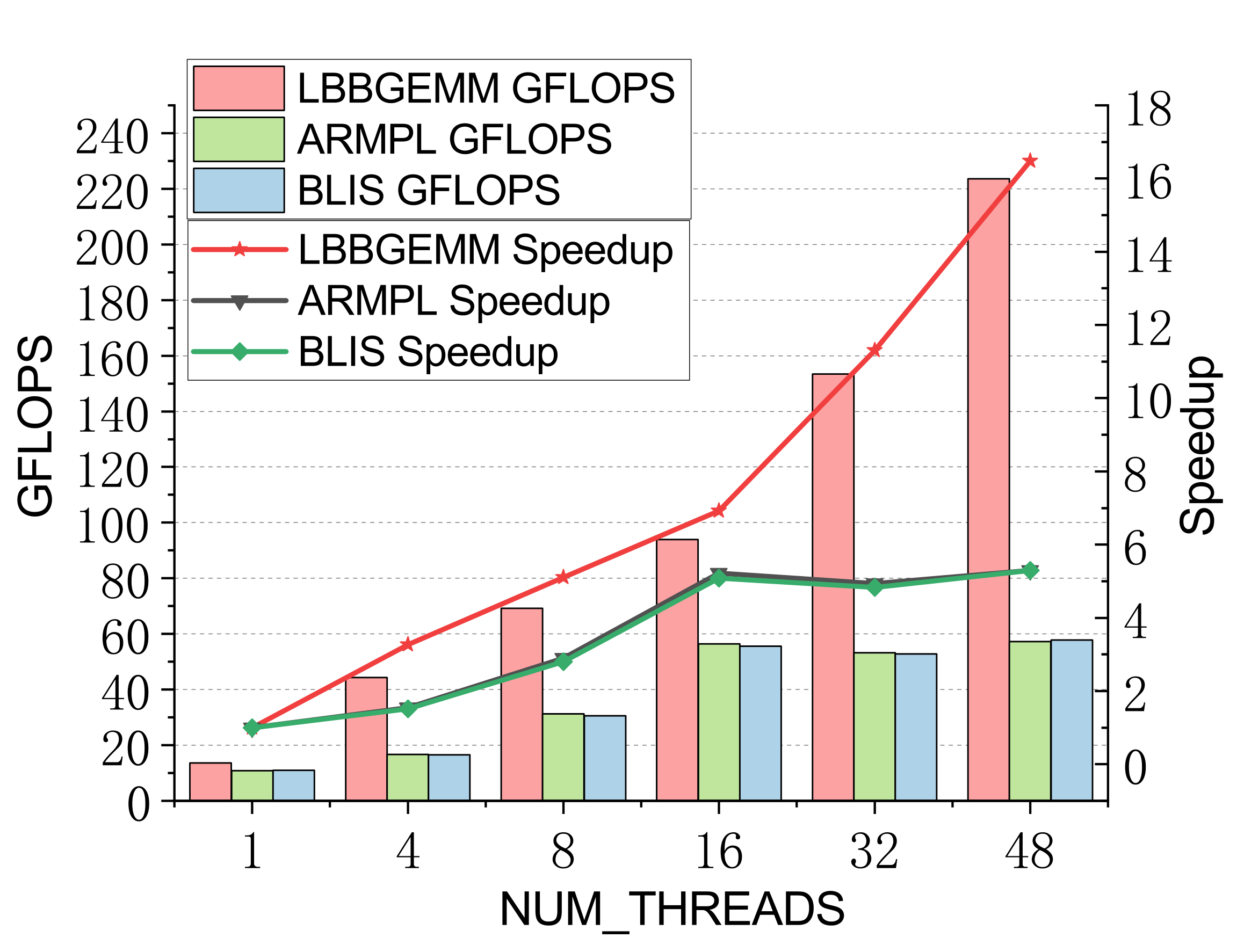
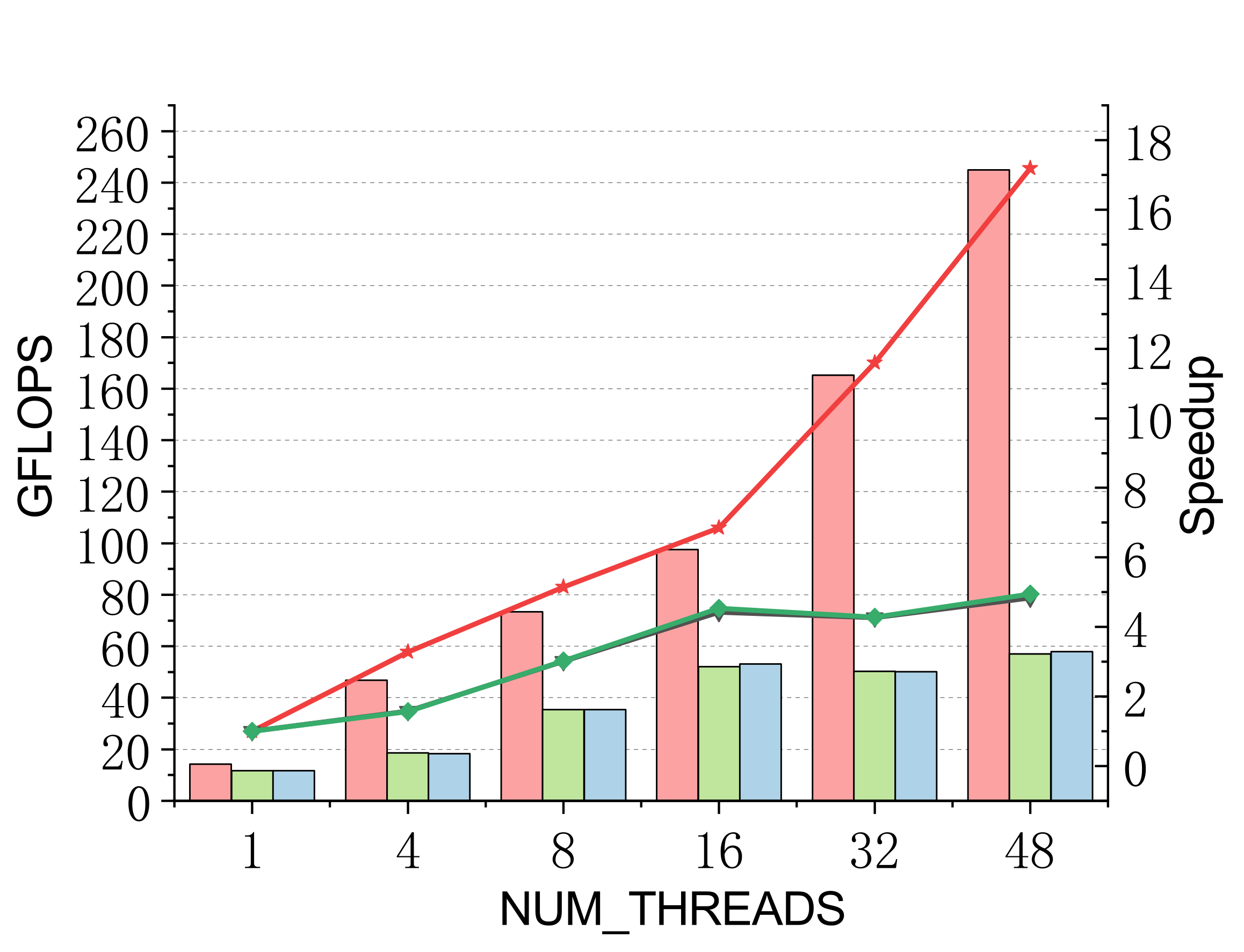
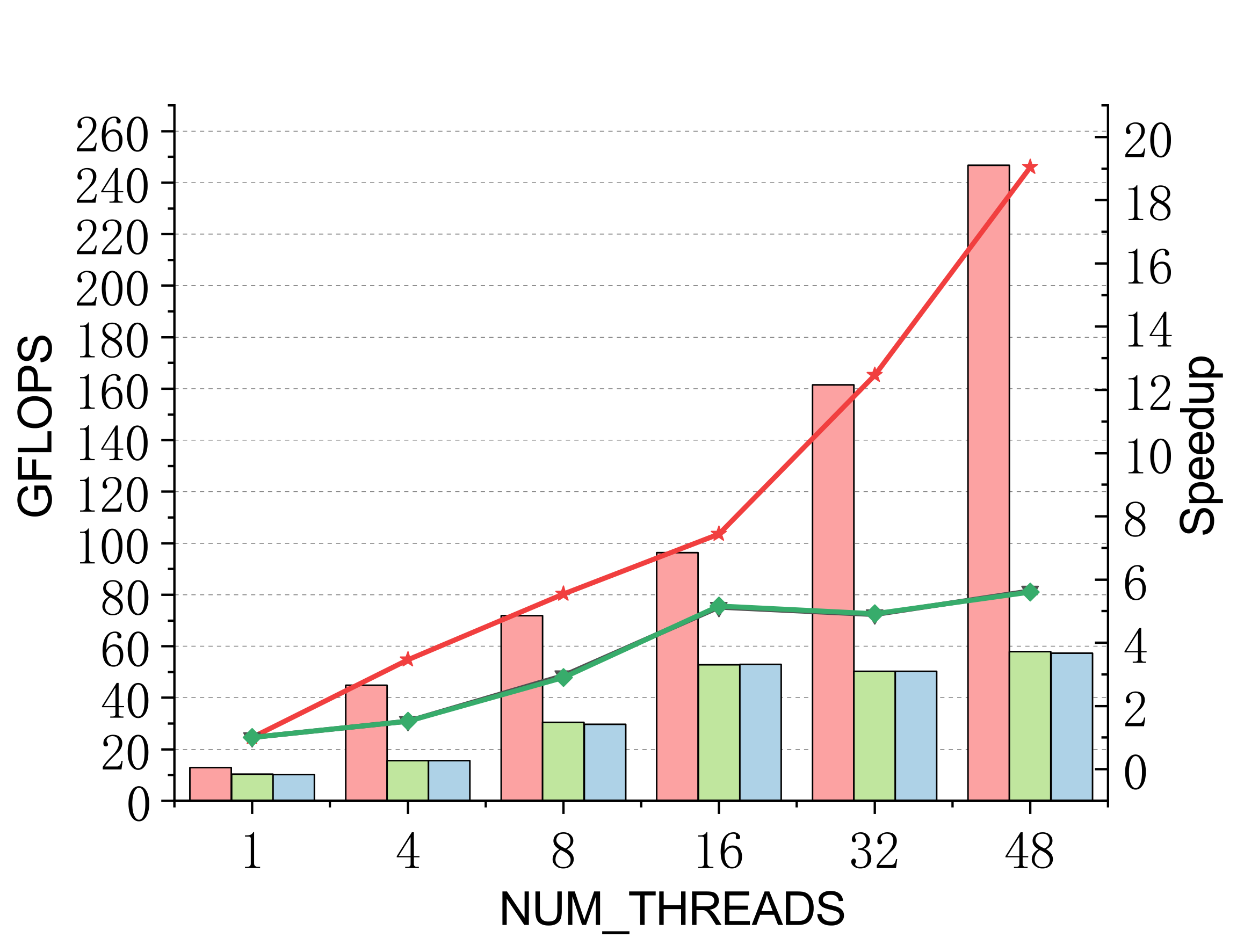
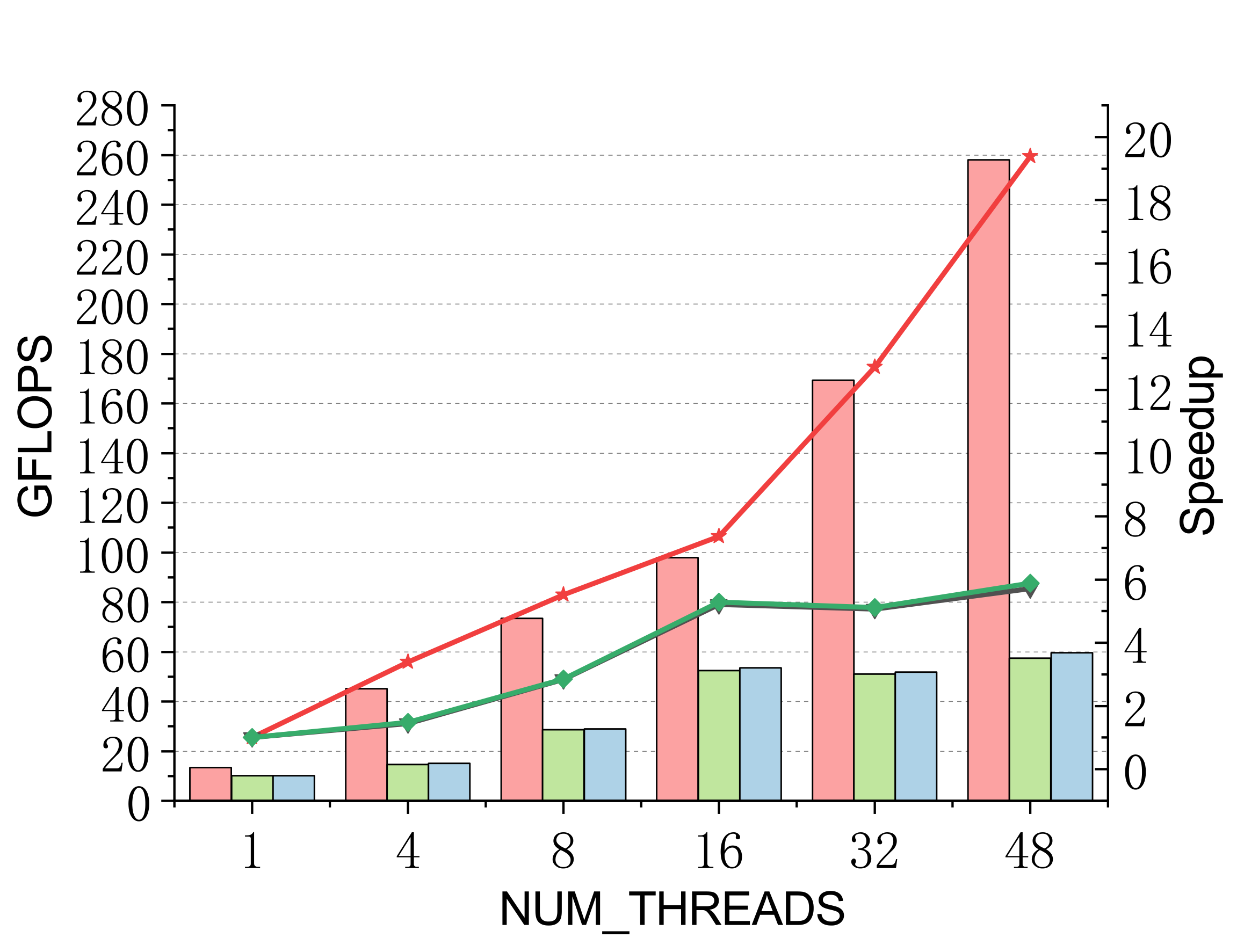
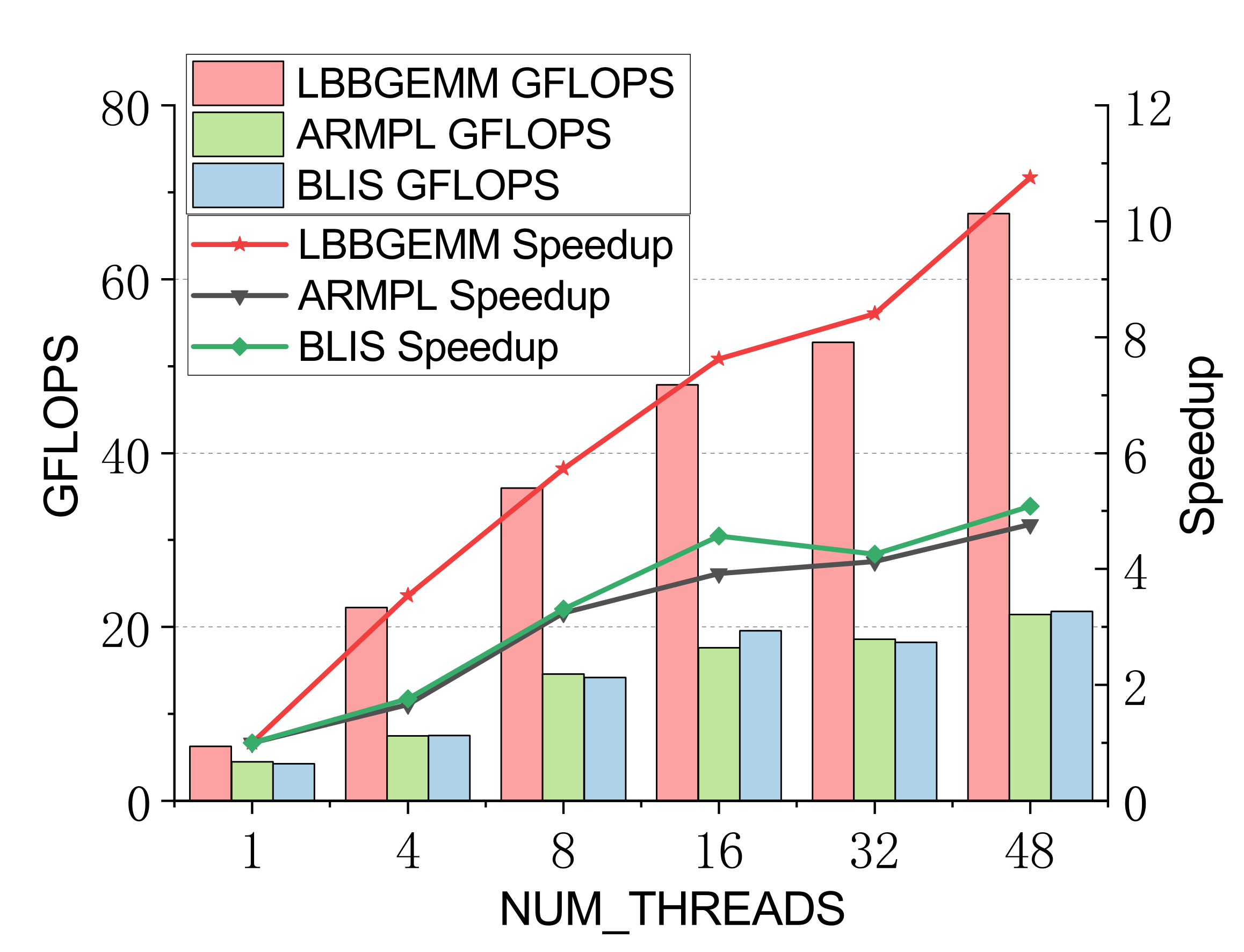
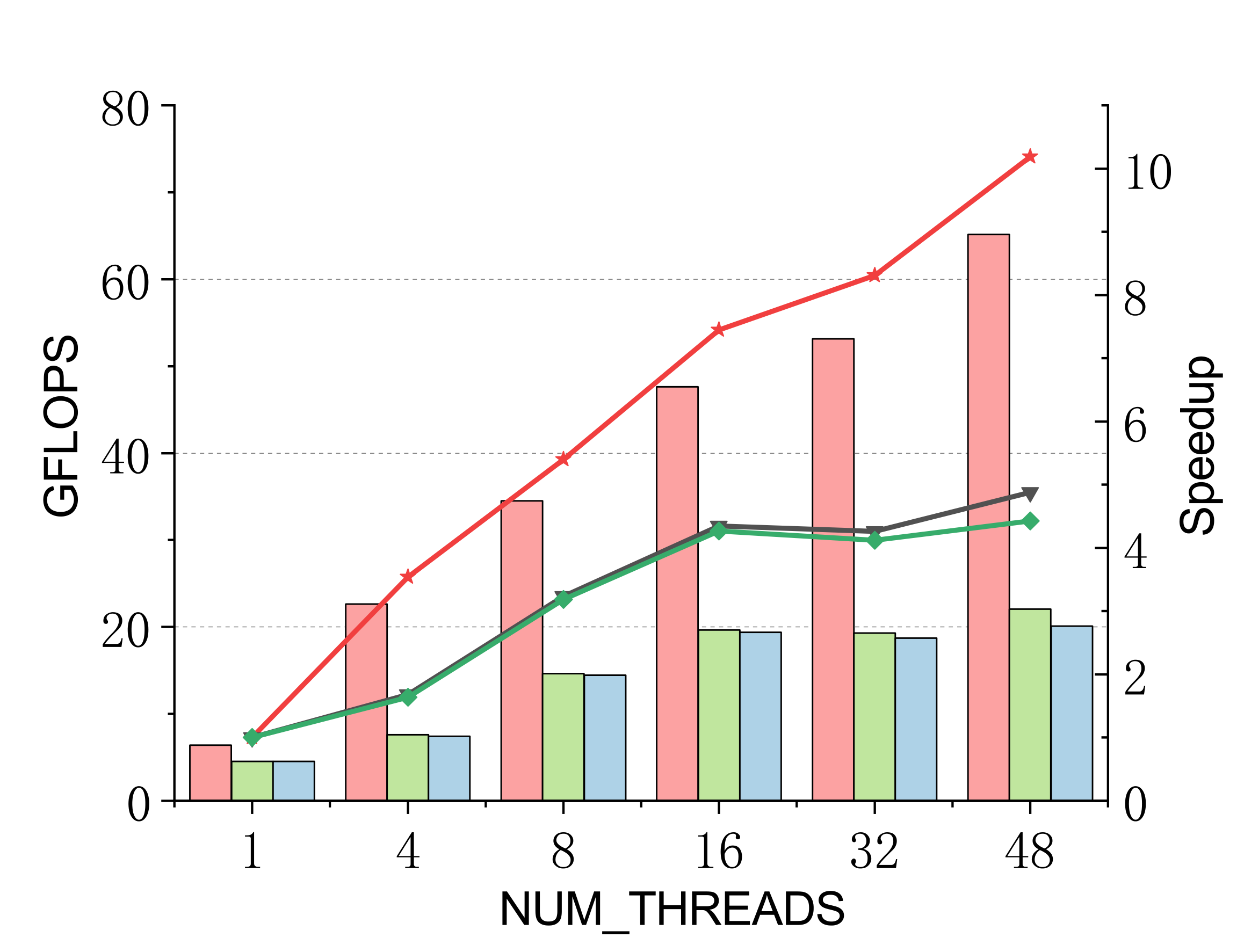
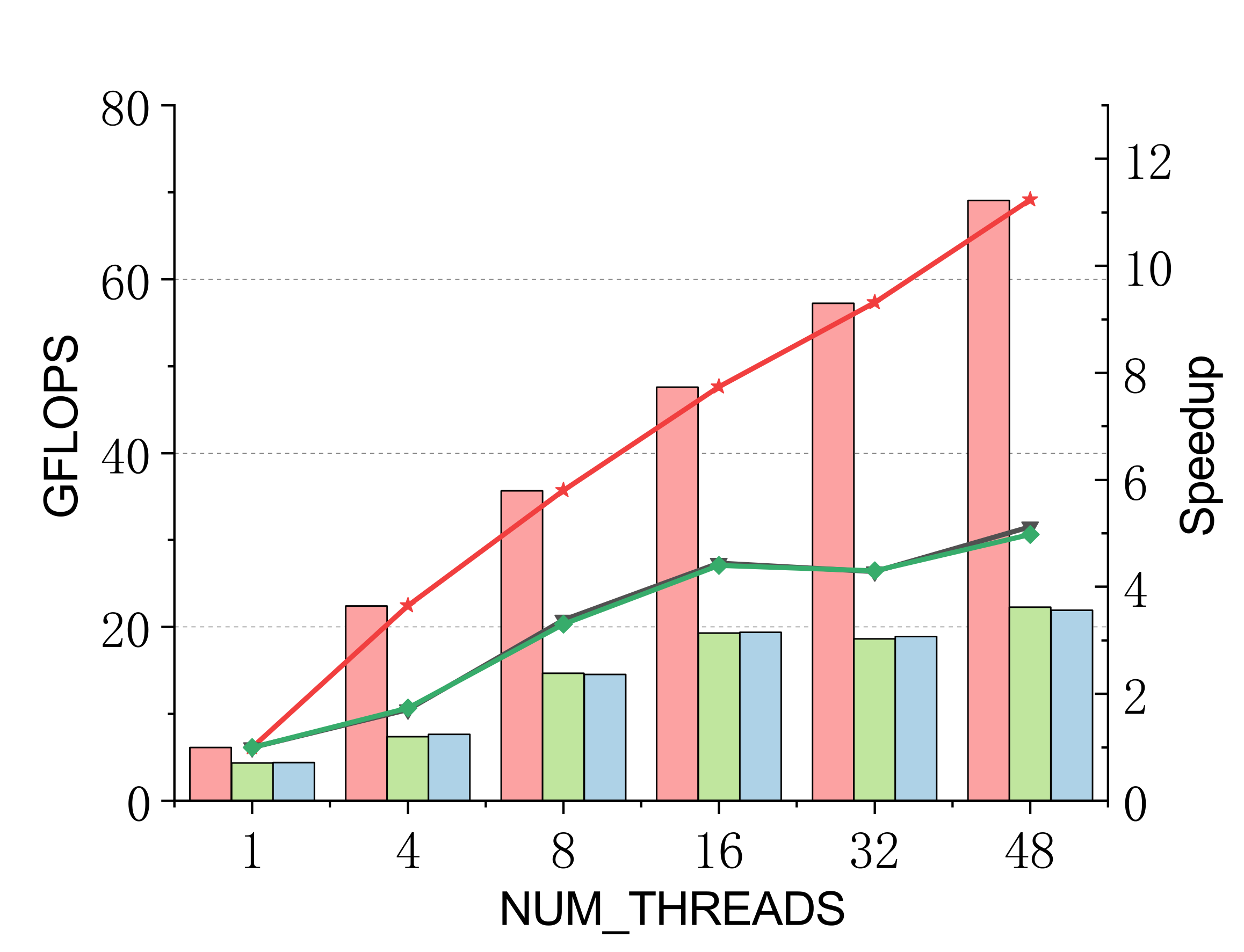
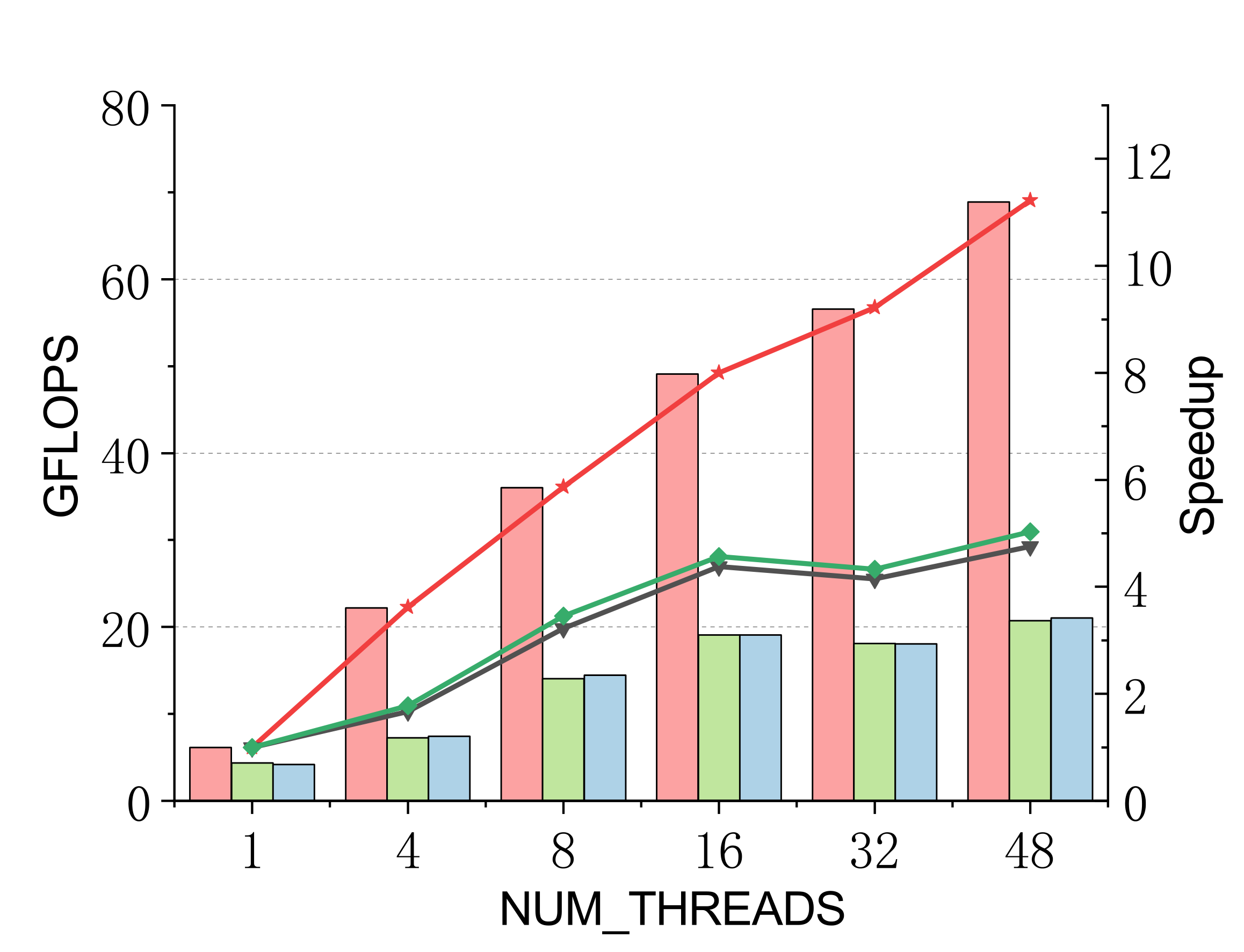
Evaluated on a 96-core Kunpeng 920 (ARMv8.2) vs. ARMPL and BLIS batch-GEMM interfaces. Batch: group_count=4, group_size={10000,1000,100,100}, m=n=k={10,20,30,40}; threads 1/4/8/16/32/48.
Double-precision (representative)
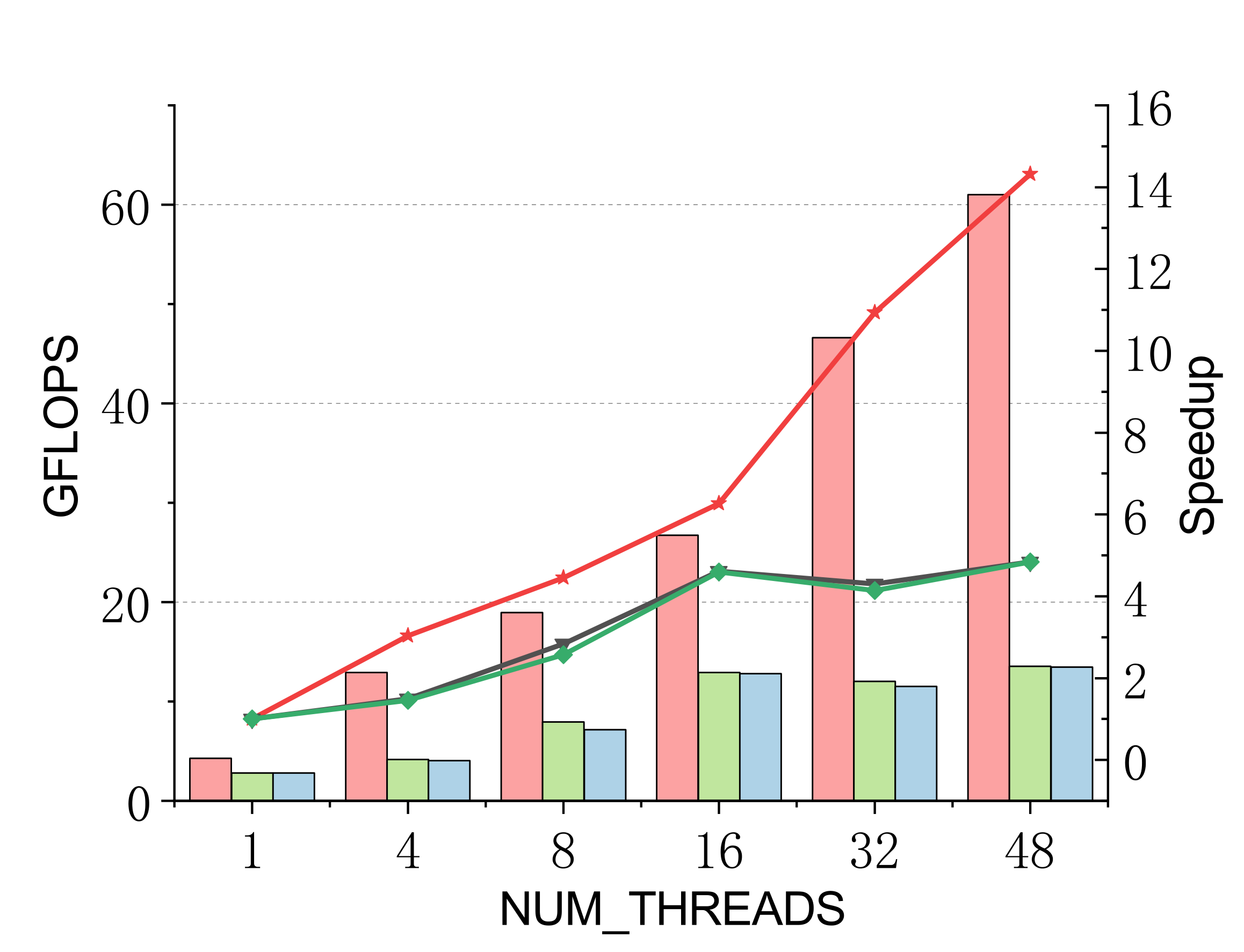
Single-precision
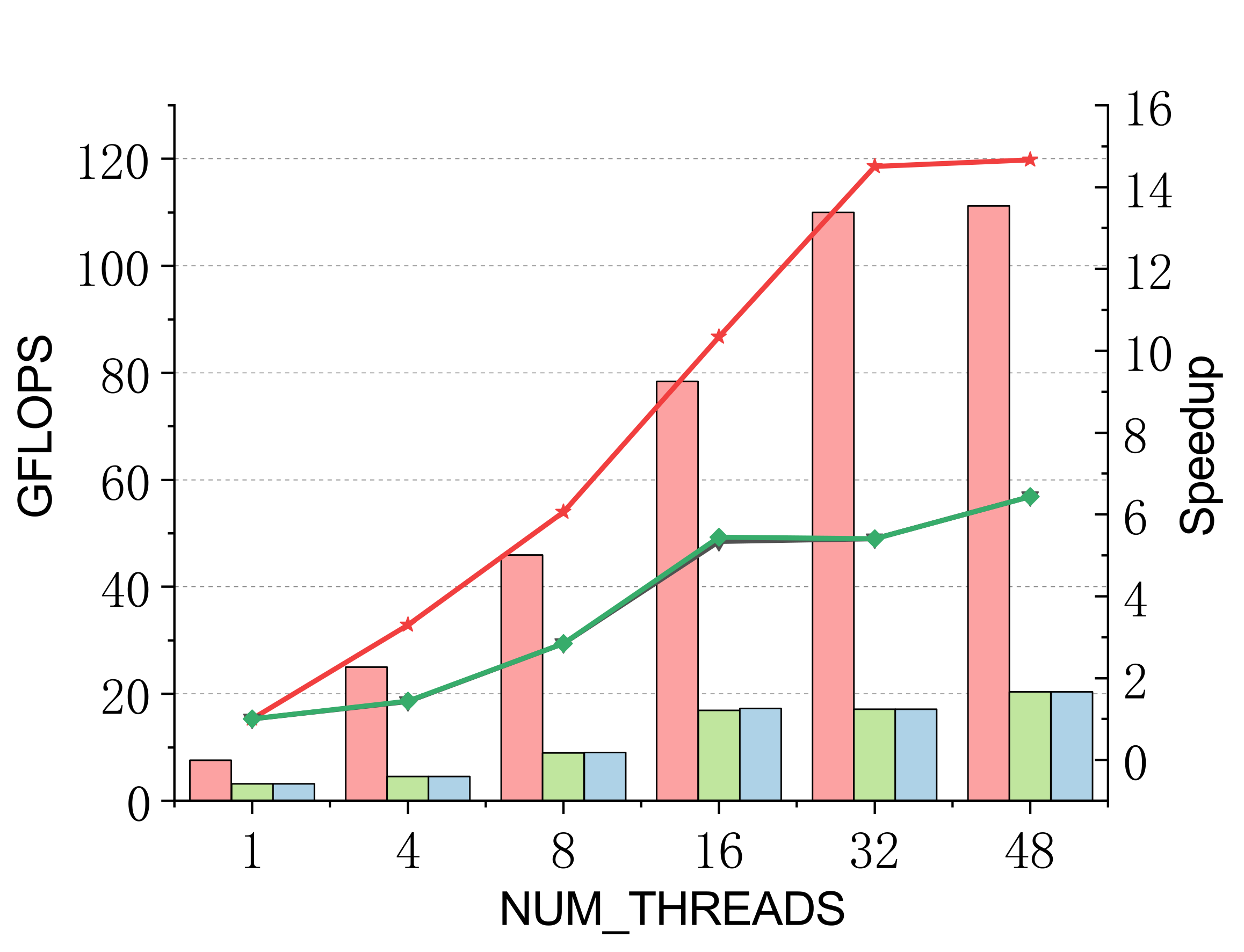
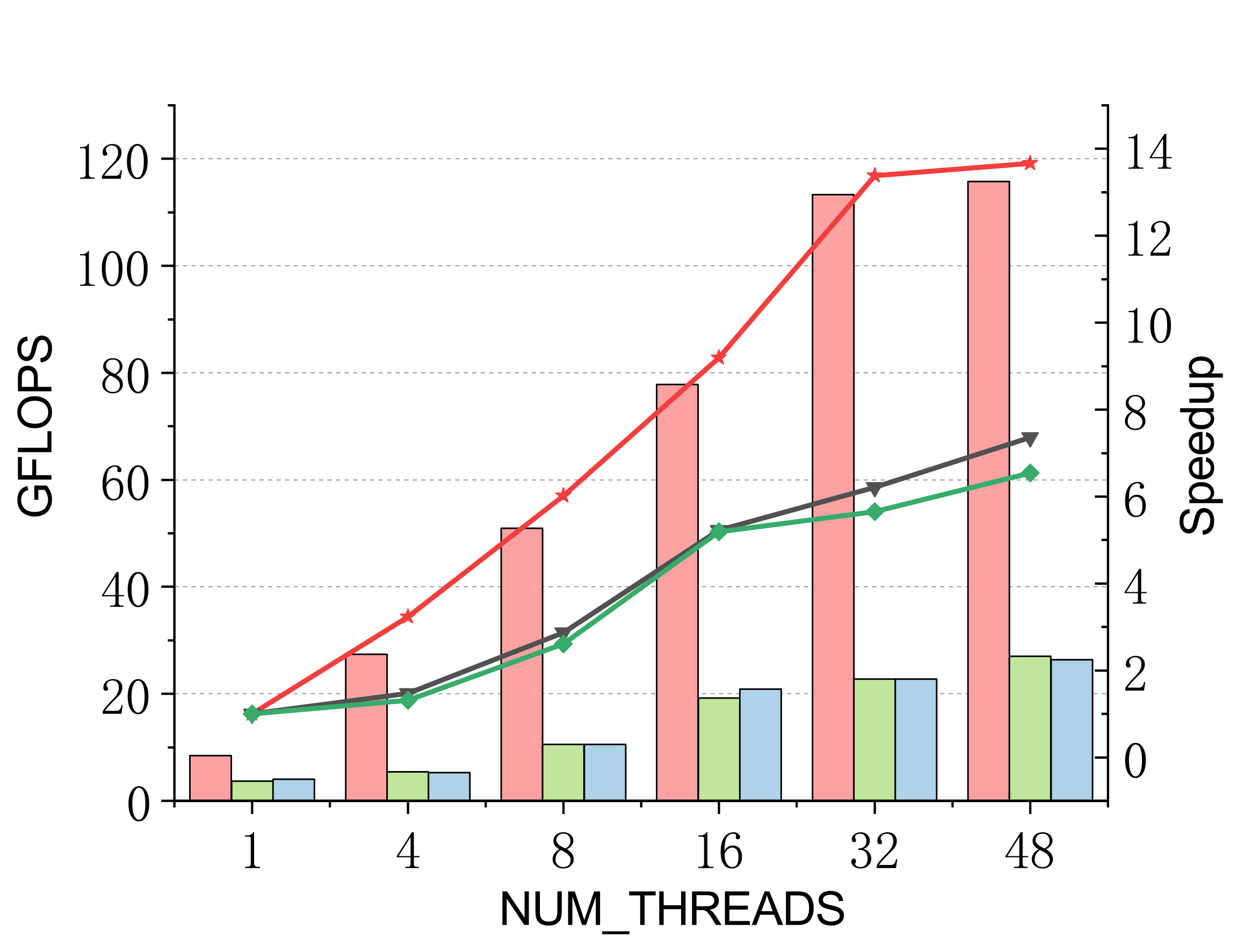
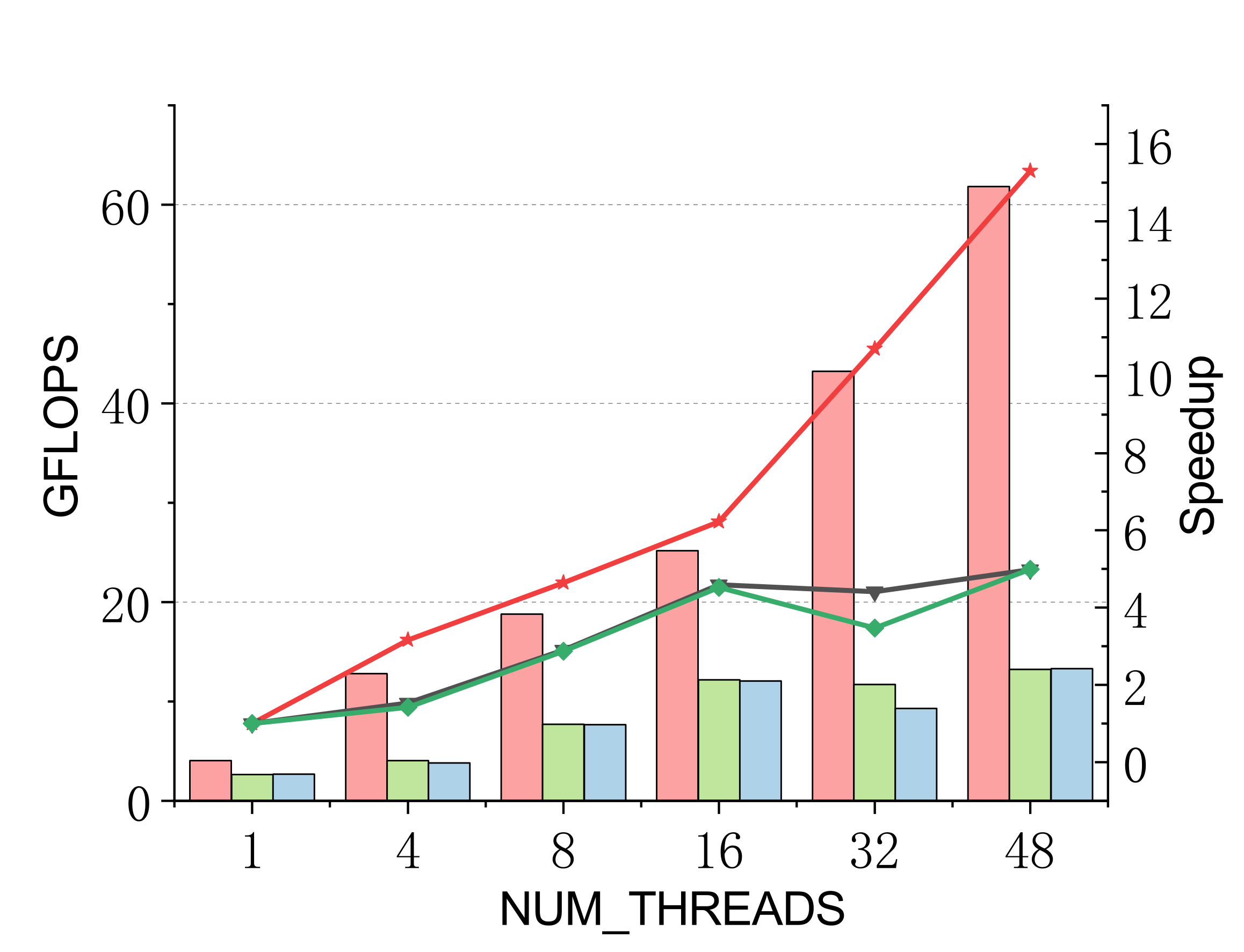
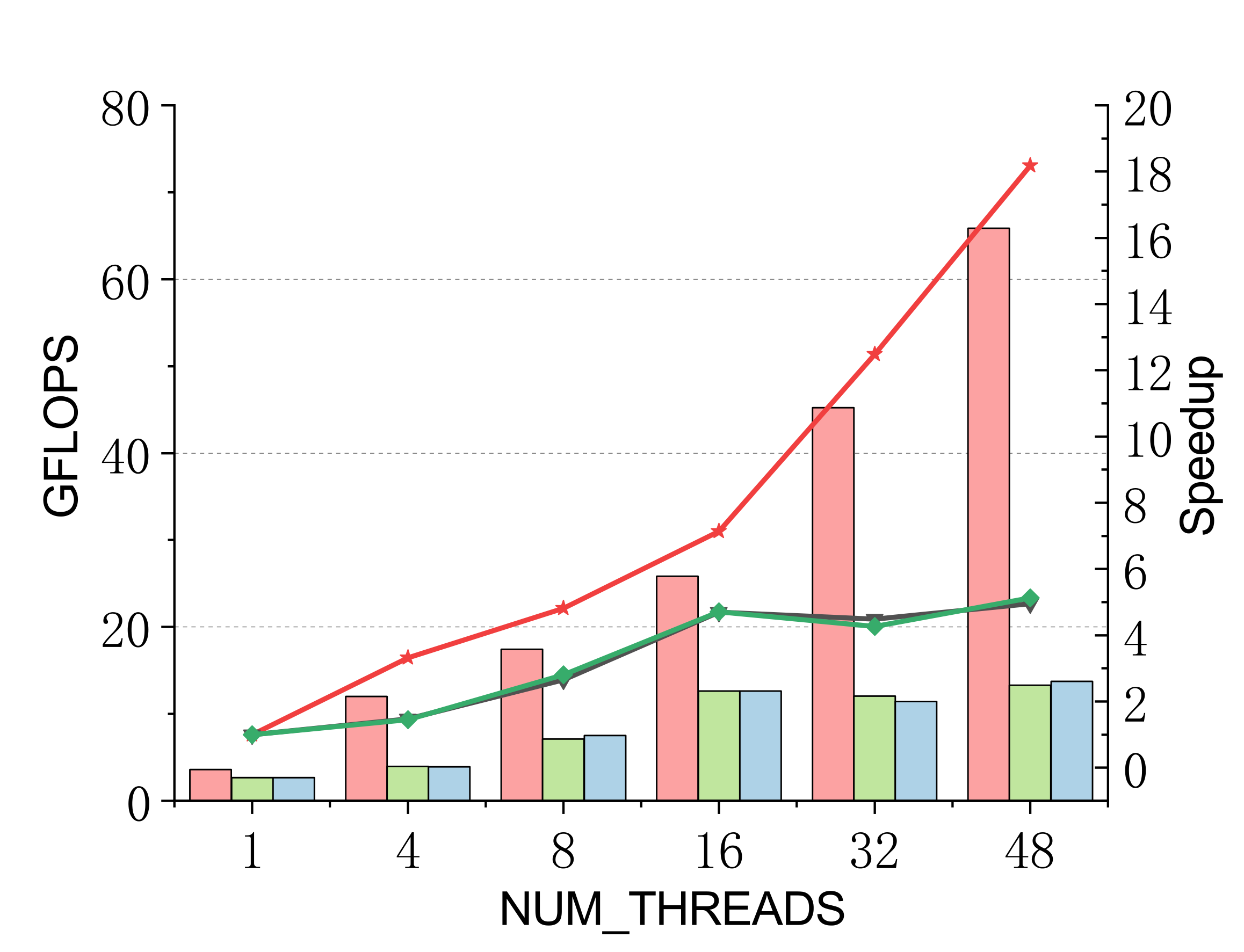
Complex (single & double)
Bottom line
Efficient batch GEMM needs both fast small-GEMM kernels and load-balanced scheduling. LBBGEMM combines no-packing, boundary-complete small-GEMM kernels with a pre-grouped dynamic thread↔task scheduler, beating ARMPL and BLIS by up to 2.4× single-core and up to 4.2× at 48 threads — with a multi-thread scaling ratio (up to 18.2×) far exceeding the ~5× of the baselines.
BibTeX
@inproceedings{wei_lbbgemm,
title = {LBBGEMM: A Load-balanced Batch GEMM Framework on
ARM CPUs},
author = {Wei, Cunyang and Jia, Haipeng and Zhang, Yunquan
and Li, Kun and Wang, Luhan},
booktitle = {IEEE International Conference on High Performance
Computing and Communications (HPCC)},
note = {ICT, Chinese Academy of Sciences}
}