Abstract
Collective communication is becoming increasingly important in supercomputer workloads with the rise of AI jobs. Yet existing libraries — NCCL, RCCL, and Cray-MPICH — exhibit performance and scalability limitations on modern GPU supercomputers. We introduce the Performant Collective Communication Library (PCCL), targeted at distributed deep learning, with highly optimized implementations of all-gather, reduce-scatter, and all-reduce.
PCCL uses hierarchical algorithms and ML-guided adaptive dispatching to scale efficiently to thousands of GPUs. On 2048 GCDs of Frontier it achieves up to 168× (reduce-scatter), 33× (all-gather), and 10× (all-reduce) over RCCL; up to 5.7× on Perlmutter. These gains translate directly to end-to-end training: up to 4.9× over RCCL in DeepSpeed ZeRO-3, and up to 2.4× in PyTorch DDP.
Key Contributions
Diagnose the libraries
A systematic analysis of Cray-MPICH, NCCL, and RCCL limitations for all-gather and reduce-scatter in DL workloads on Perlmutter and Frontier — pinpointing NIC under-utilization, CPU-side reductions, and missing log-latency algorithms.
Build PCCL
Optimized hierarchical implementations of all-gather, reduce-scatter, and all-reduce that fully use system NICs and GPU compute, scaling to large messages and GPU counts.
Massive speedups
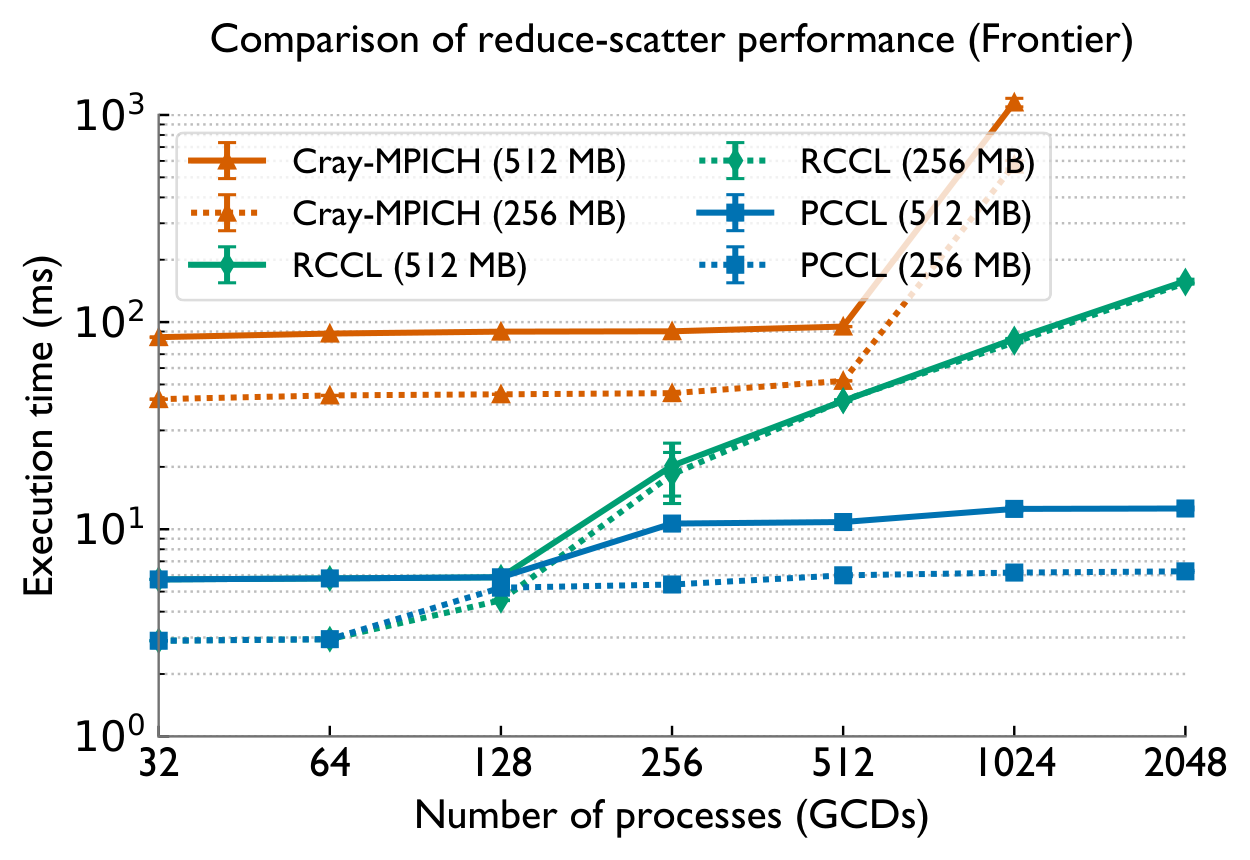
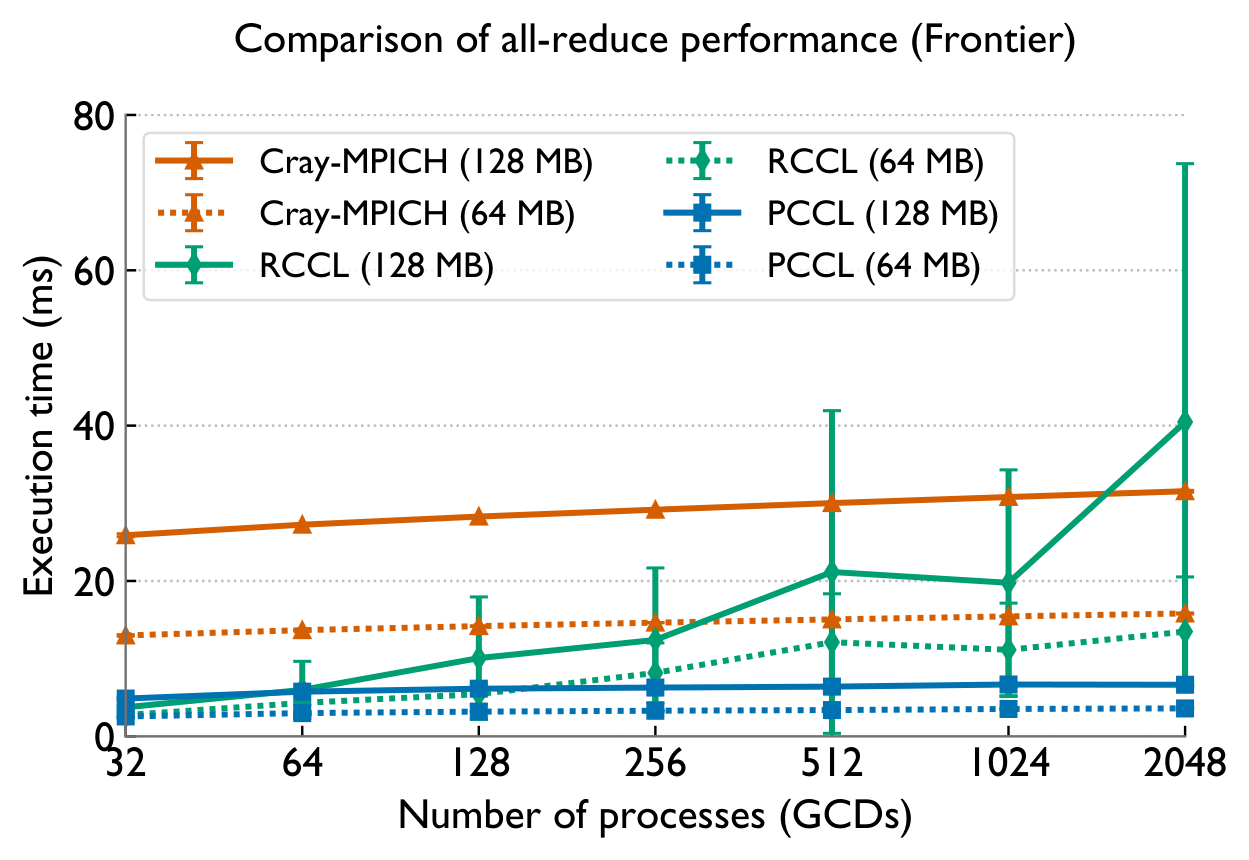
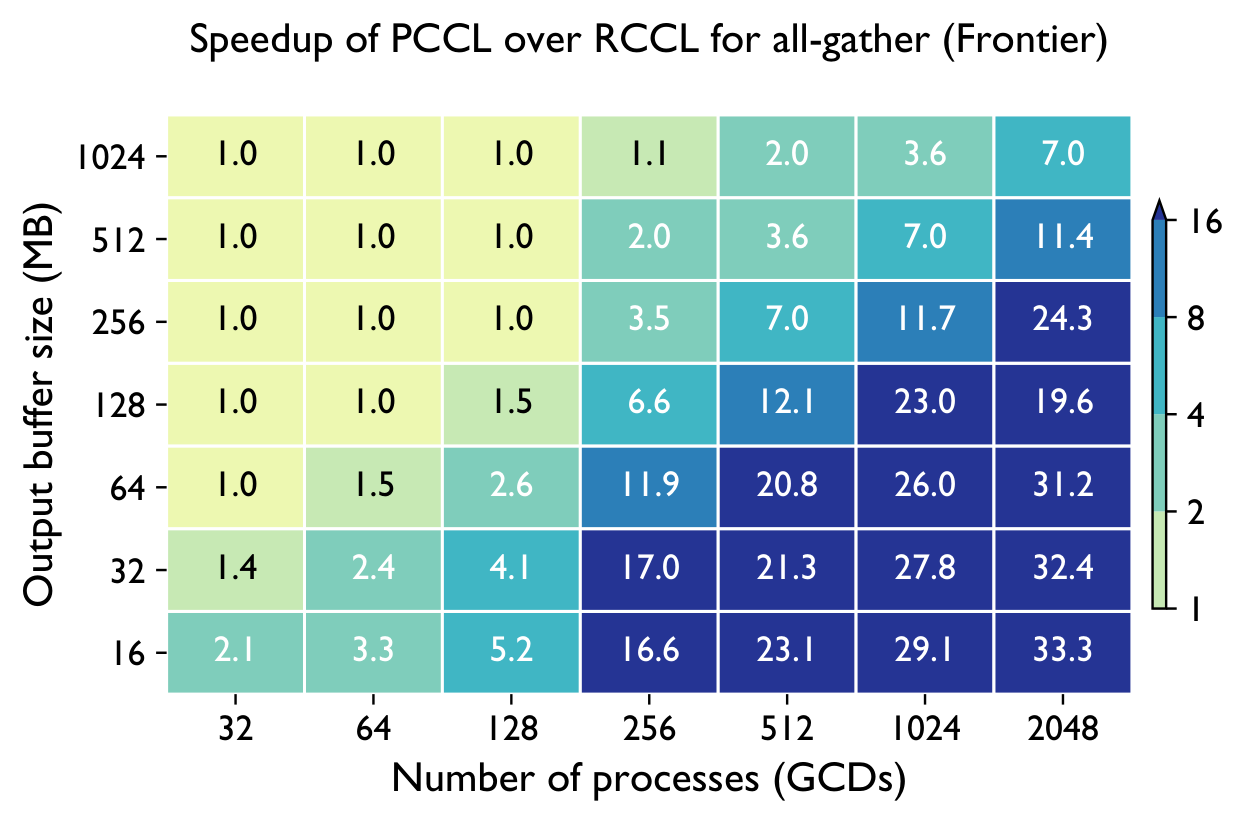
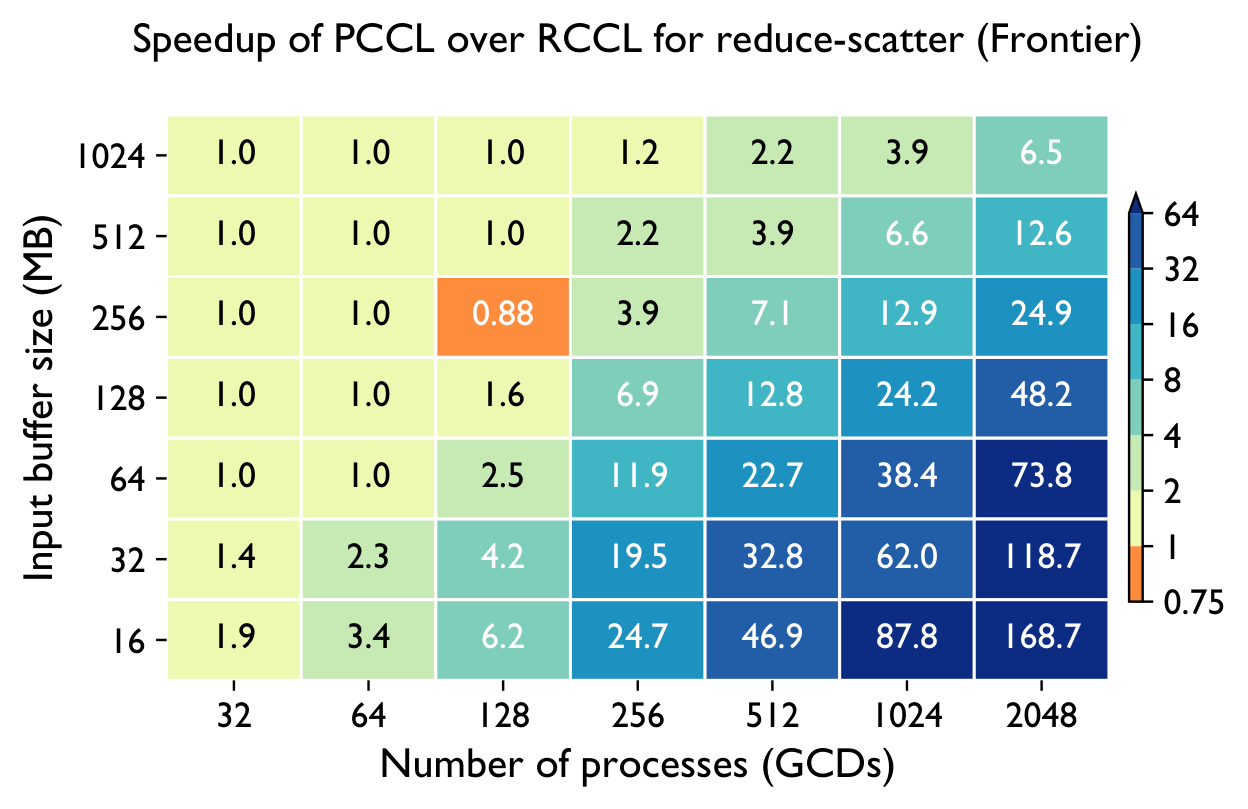
Up to 168× (reduce-scatter), 33× (all-gather), 10× (all-reduce) over RCCL on 2048 GCDs of Frontier; up to 5.7× on Perlmutter.
End-to-end validation
Multi-billion-parameter LLM training: up to 4.9× over RCCL in DeepSpeed ZeRO-3 and up to 2.4× in PyTorch DDP.
Why Collectives, Why Large Messages
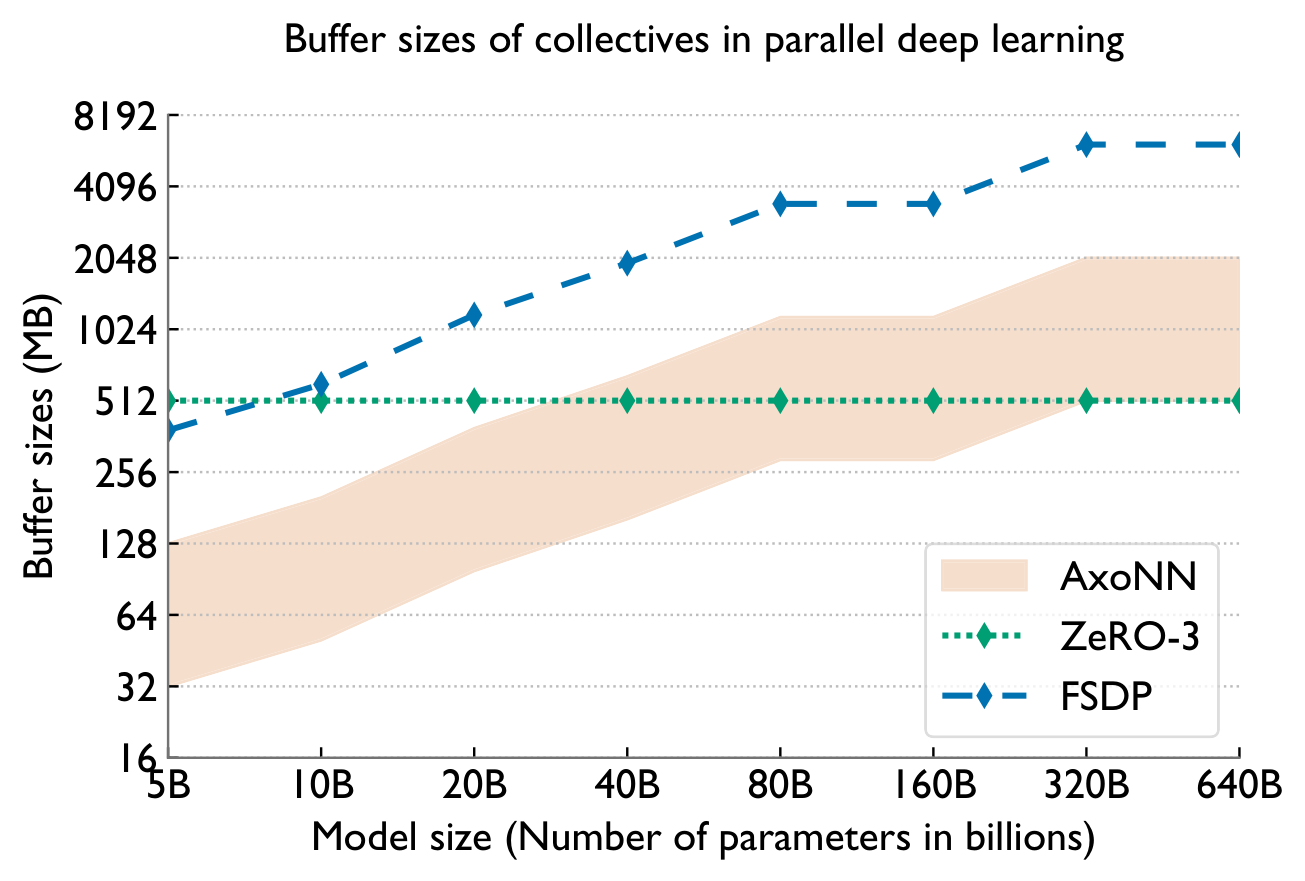
Modern distributed training is dominated by three collectives. Their message sizes are far larger than traditional HPC — tens to hundreds of MB, sometimes >1 GB — exactly the regime where existing libraries struggle.
Sharded Data Parallelism
Parameters and gradients are sharded across GPUs (FSDP, ZeRO-3, AxoNN). All-gather reconstructs full parameters; reduce-scatter reduces and distributes gradients.
Distributed Data Parallelism
Parameters are replicated; all-reduce synchronizes gradients each iteration. A 1B-param FP32 model exchanges 4 GB of gradients per step.
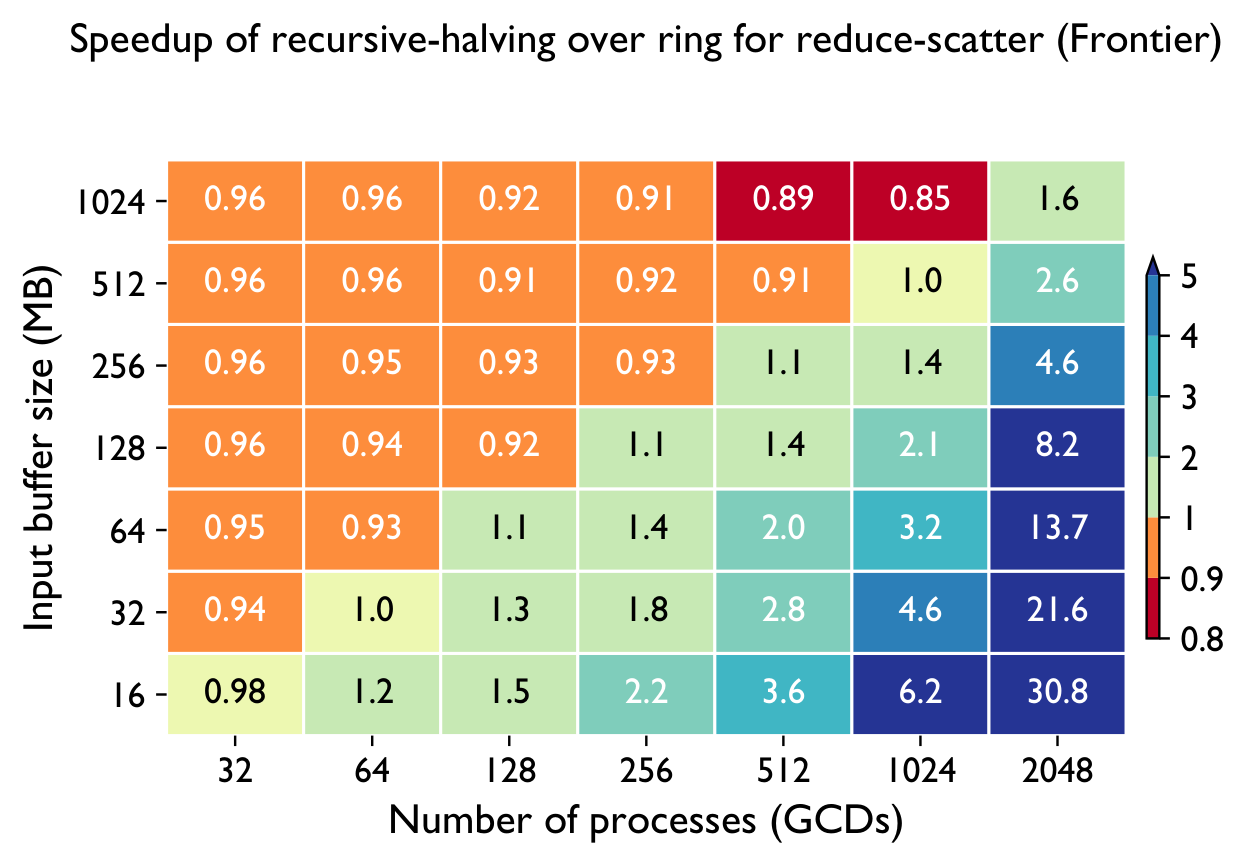
The algorithmic toolbox
Ring is simple and bandwidth-efficient but its latency grows linearly with process count. Recursive halving/doubling needs only log₂(p) steps — far better at scale.
What's Wrong With Today's Libraries
We benchmarked all three libraries with best practices (NUMA-aware NIC binding, GPU Direct RDMA, no eager messaging) and found distinct, fixable bottlenecks.
Cray-MPICH wastes NICs and the GPU
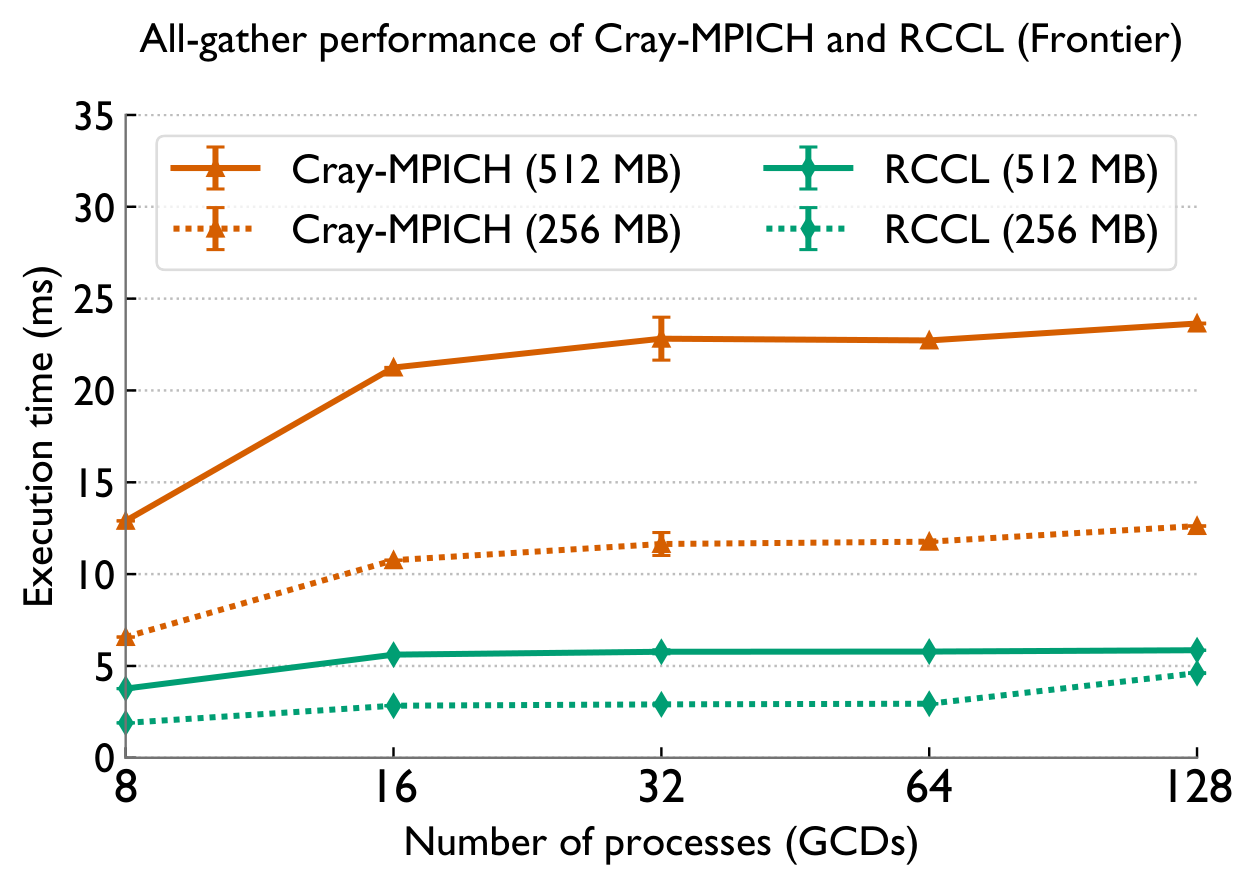
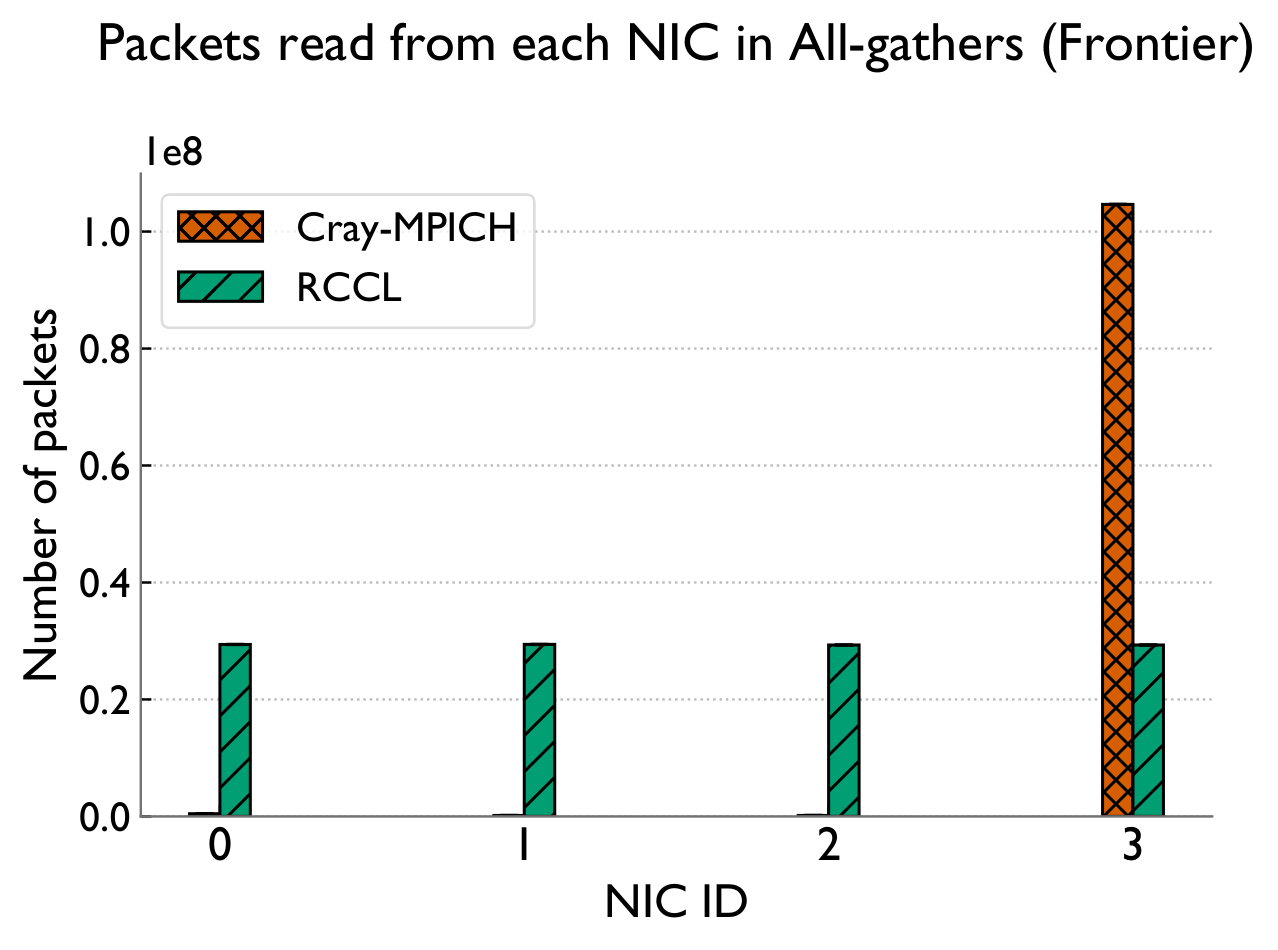
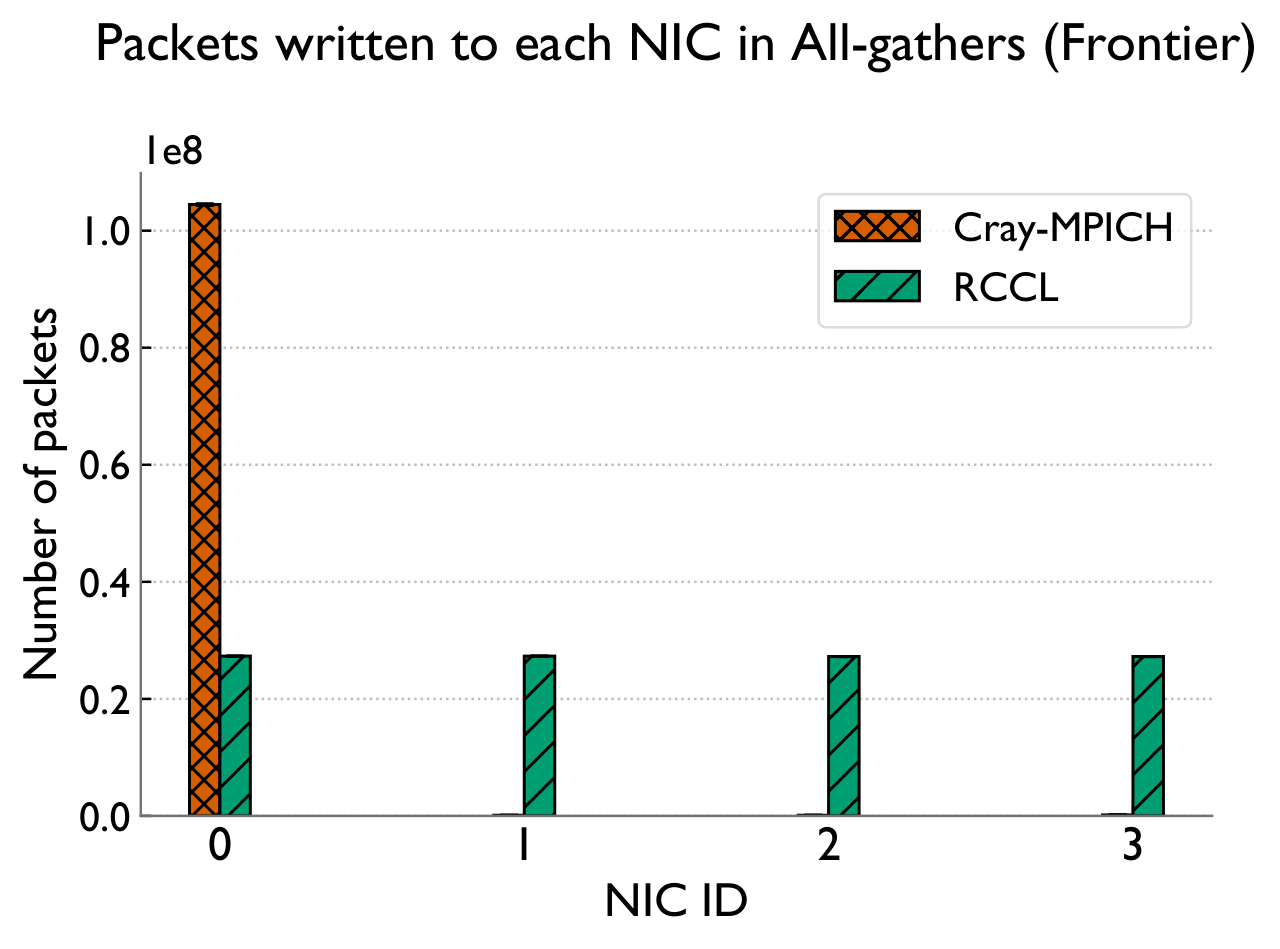
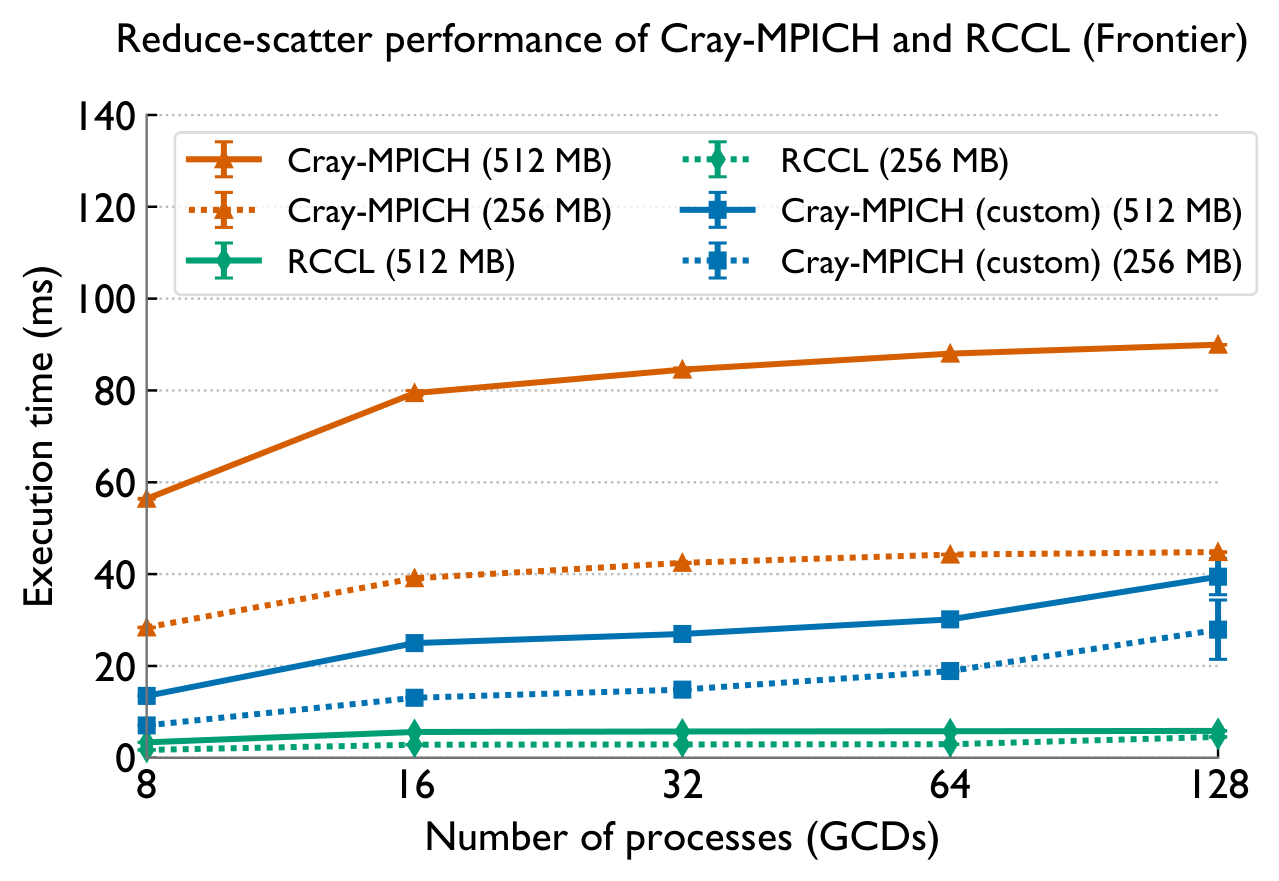
Cray-MPICH severely underutilizes available network (NIC) and computational (GPU) resources. It routes all network traffic through a single NIC, and performs reduction operations on the CPU instead of offloading them to the GPU.
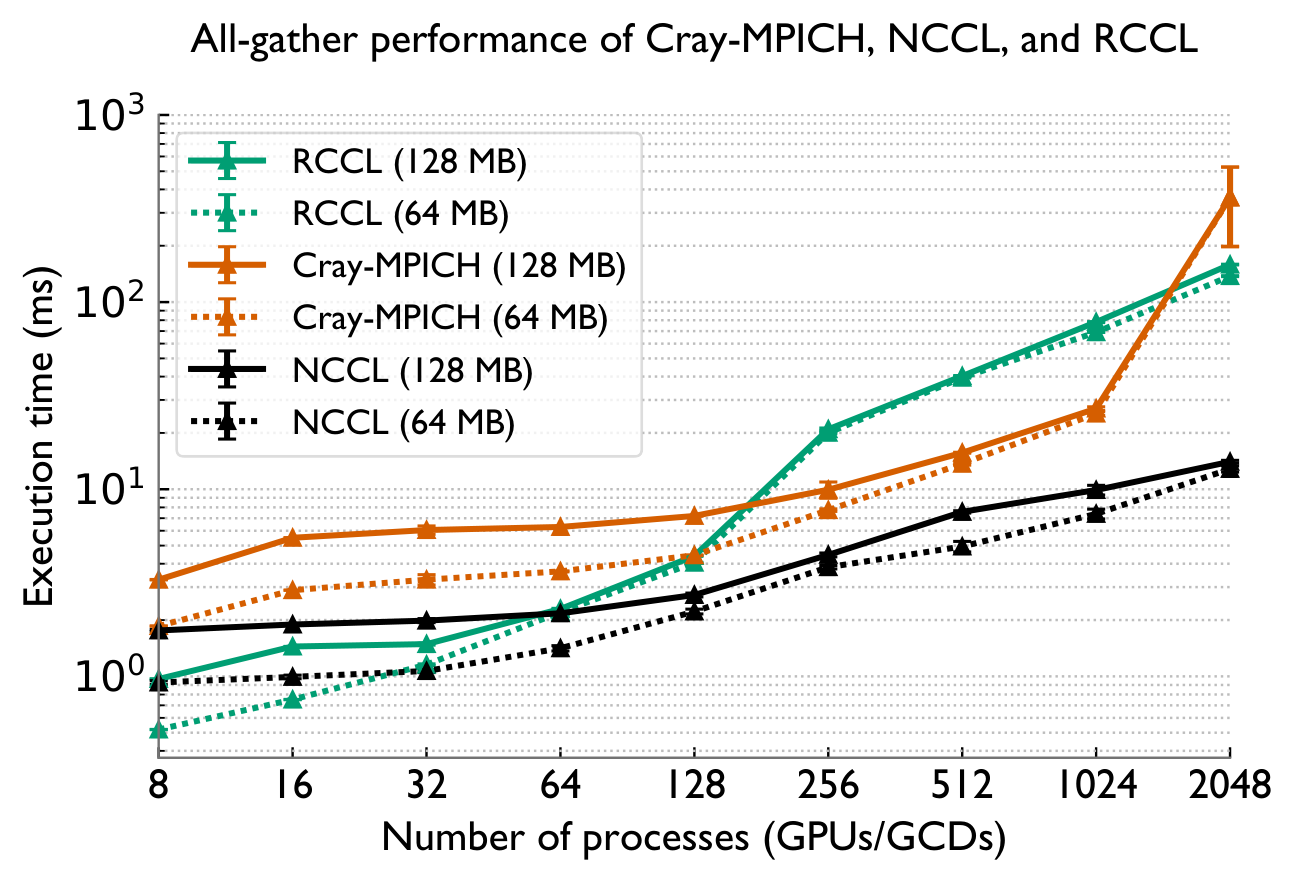
NCCL & RCCL scale poorly at large GPU counts
For all-gather and reduce-scatter, NCCL and RCCL only support the ring algorithm. Each process must send and receive (p−1) messages sequentially, so communication time grows linearly with process count — crippling at scale.
NCCL and RCCL rely solely on the ring algorithm for all-gather and reduce-scatter, leading to poor scaling in latency-bound scenarios. More efficient algorithms such as recursive doubling and halving are not supported.
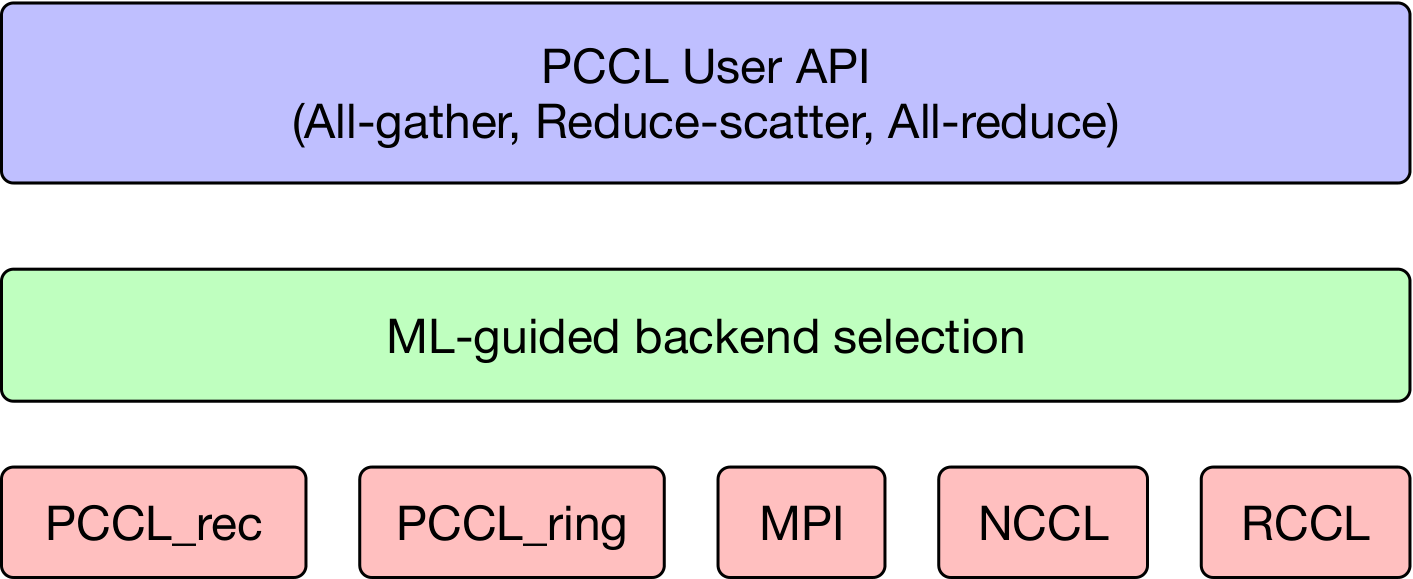
How PCCL Fixes It
PCCL combines a two-level hierarchical algorithm, custom inter-node implementations, and an ML-guided dispatcher that picks the best backend per configuration.
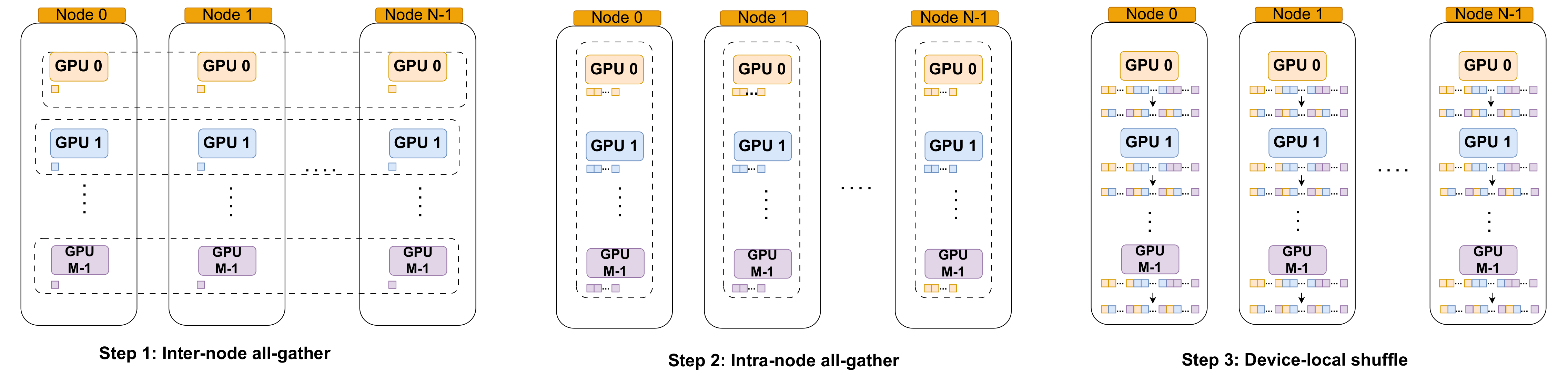
PCCL_ring
- Inter-node ring algorithm
- Best for bandwidth-bound regimes (few processes, large messages)
- Saturates peer-to-peer bandwidth
PCCL_rec
- Recursive doubling (AG) / halving (RS)
- Best for latency-bound regimes (many processes, smaller messages)
- GPU-side reduction kernels; log₂(p) steps
ML-guided adaptive dispatching
No single backend wins everywhere. PCCL trains a lightweight SVM per (machine, collective) on message size and GPU count to pick the best of Cray-MPICH, NCCL/RCCL, PCCL_ring, and PCCL_rec at runtime.
| Machine | Collective | Test size | Correct | Accuracy |
|---|---|---|---|---|
| Frontier | All-Gather | 20 | 17 | 85.0% |
| Reduce-Scatter | 20 | 18 | 90.0% | |
| All-Reduce | 20 | 16 | 80.0% | |
| Perlmutter | All-Gather | 22 | 20 | 90.9% |
| Reduce-Scatter | 22 | 21 | 95.4% | |
| All-Reduce | 20 | 15 | 75.0% |
SVM dispatcher accuracy on held-out test data (20%). High accuracy and low misclassification indicate the dispatcher generalizes to unseen configurations.
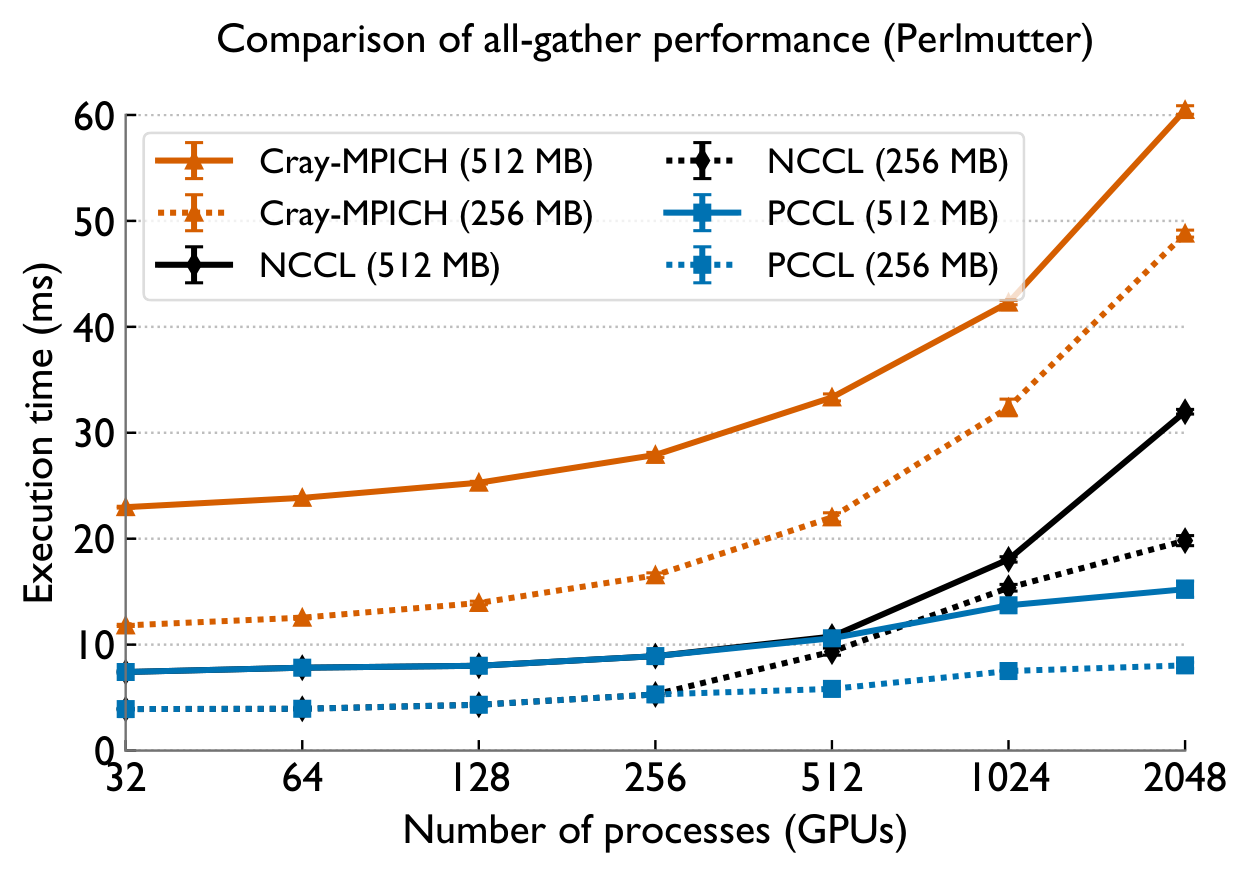
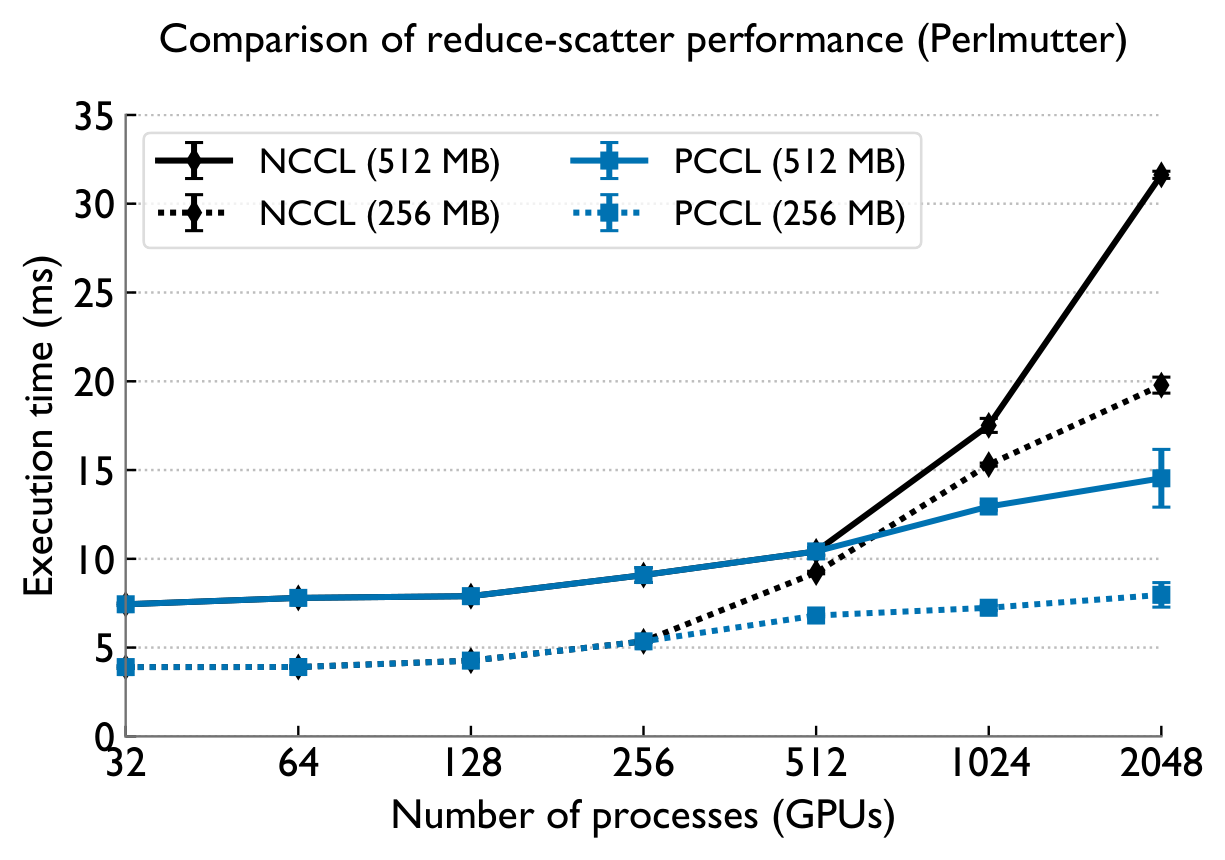
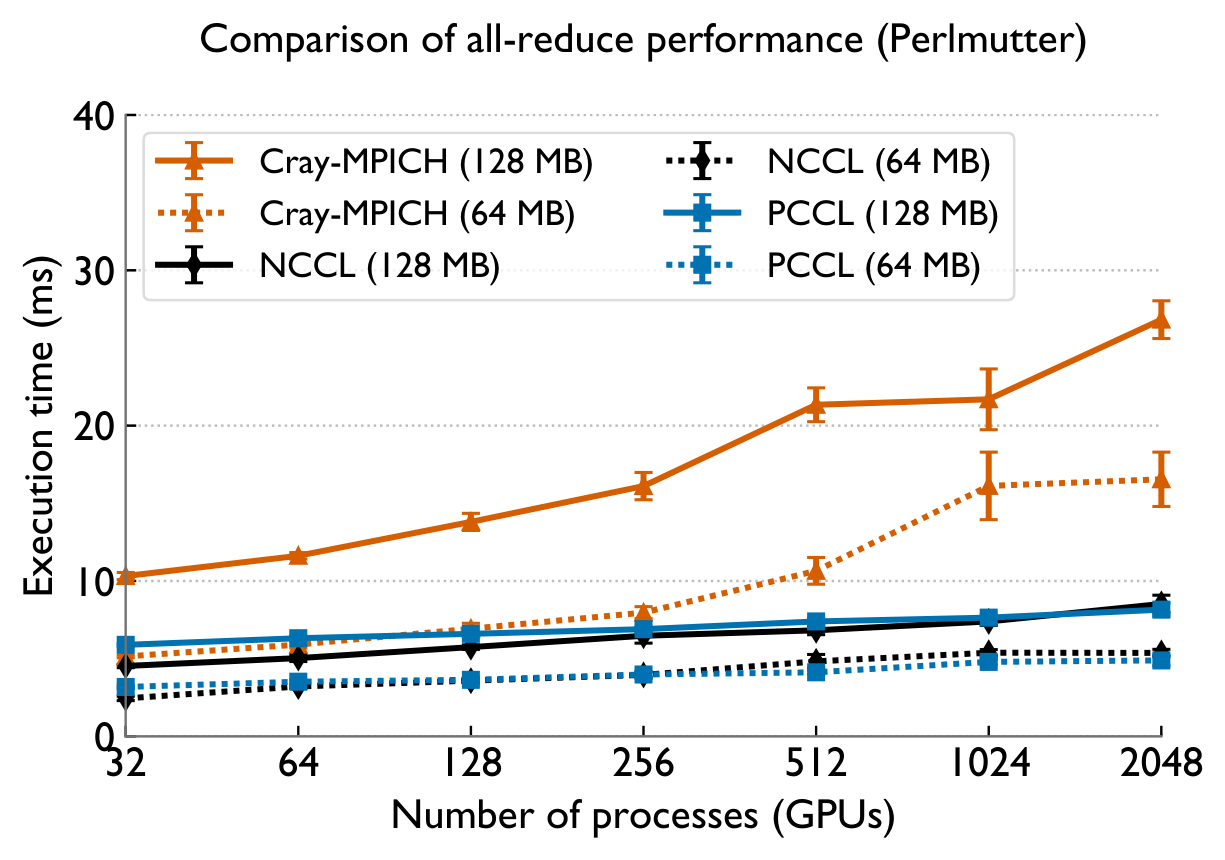
Collective Performance
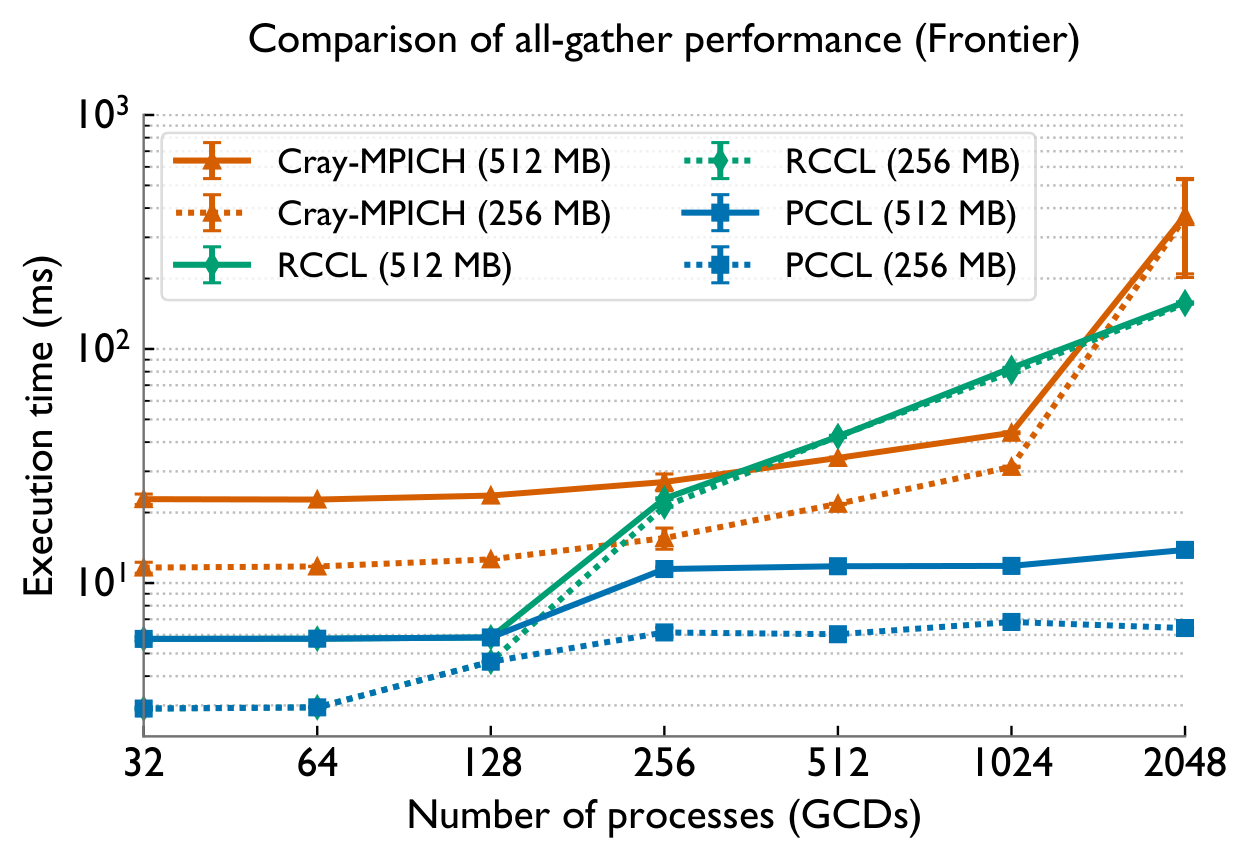
Across both systems, PCCL maintains near-flat scaling where the baselines degrade — the gap widens dramatically with GPU count.
Perlmutter (NVIDIA A100) — vs NCCL & Cray-MPICH
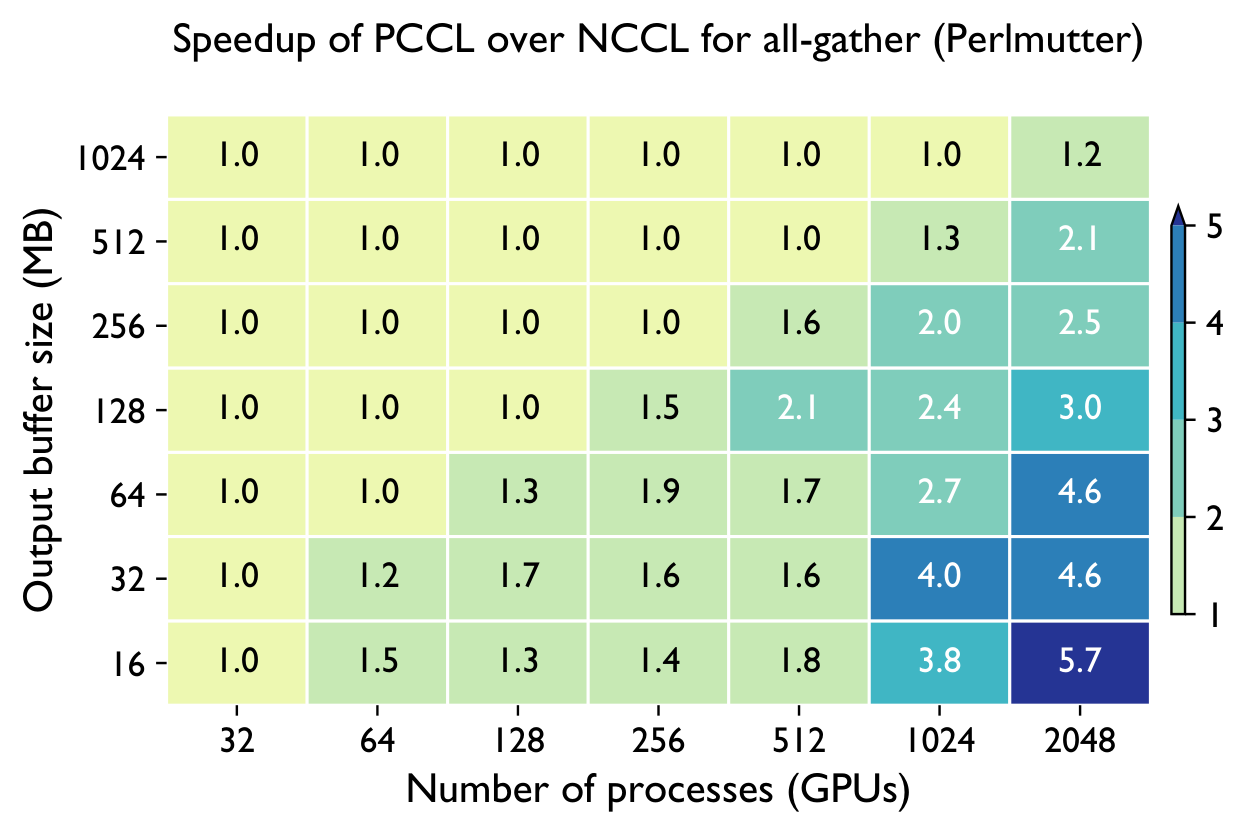
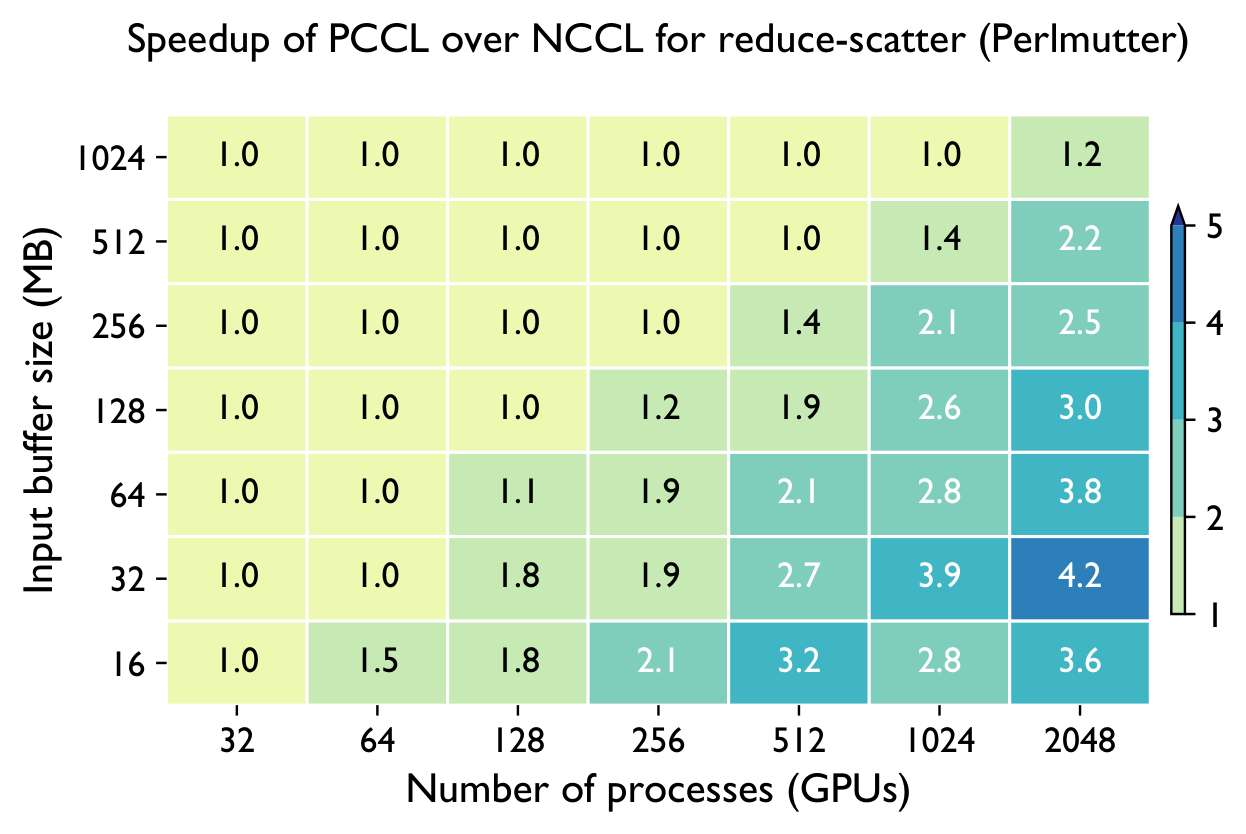
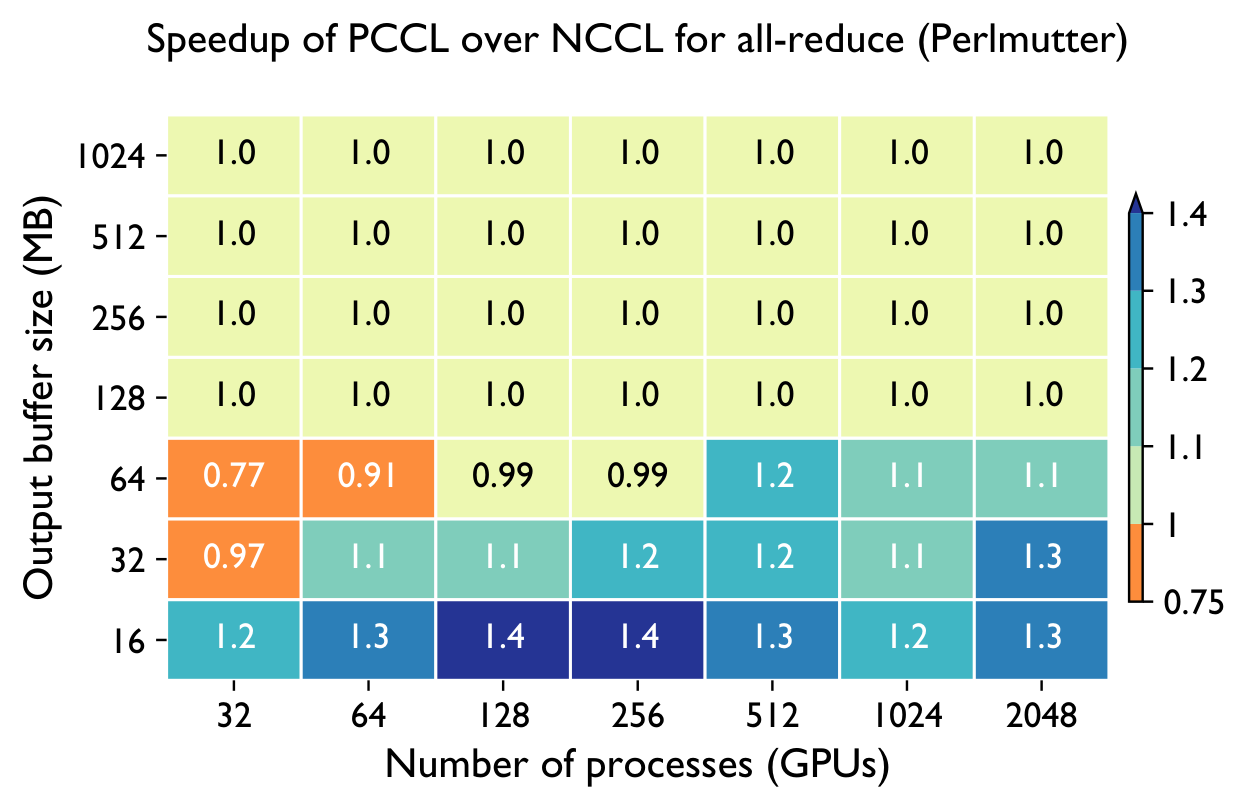
Frontier (AMD MI250X) — vs RCCL & Cray-MPICH
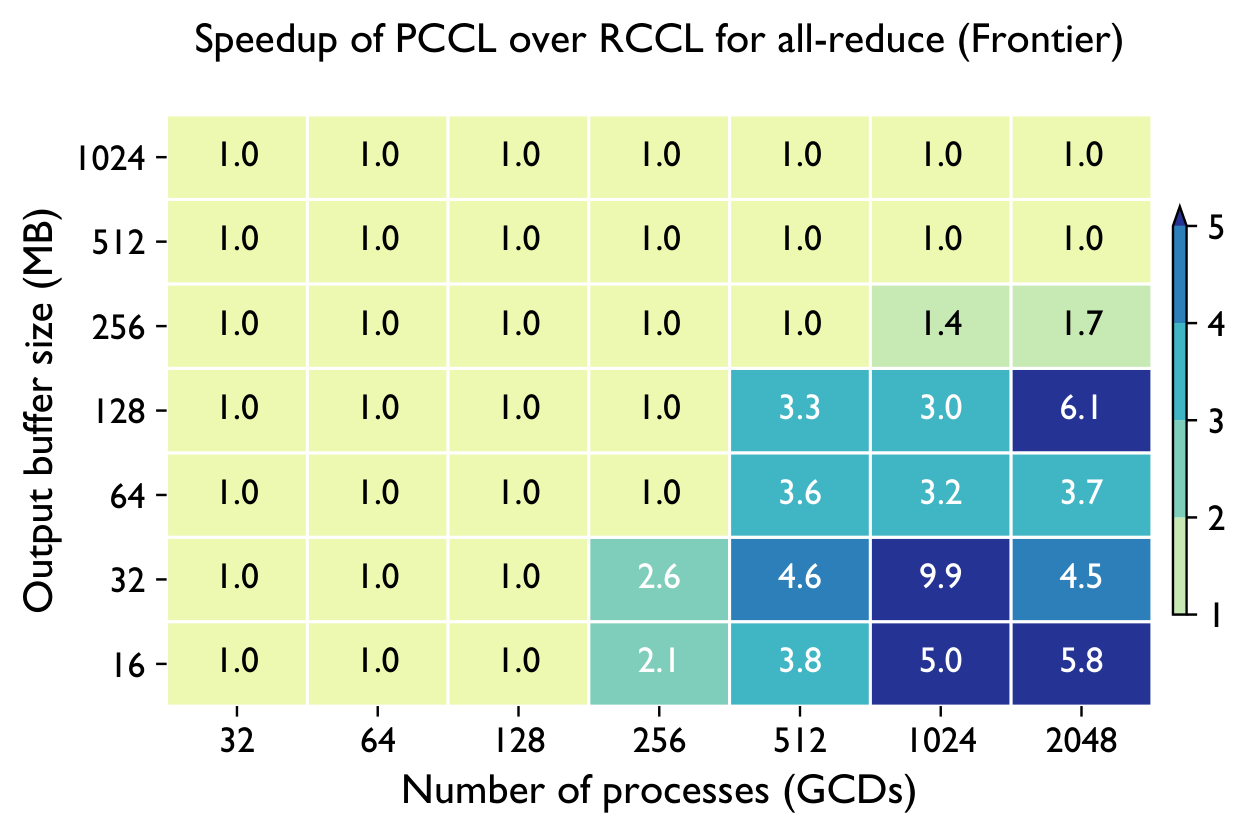
Real Training Speedups
Communication gains translate into faster large-model training as scale increases — exactly where it matters.
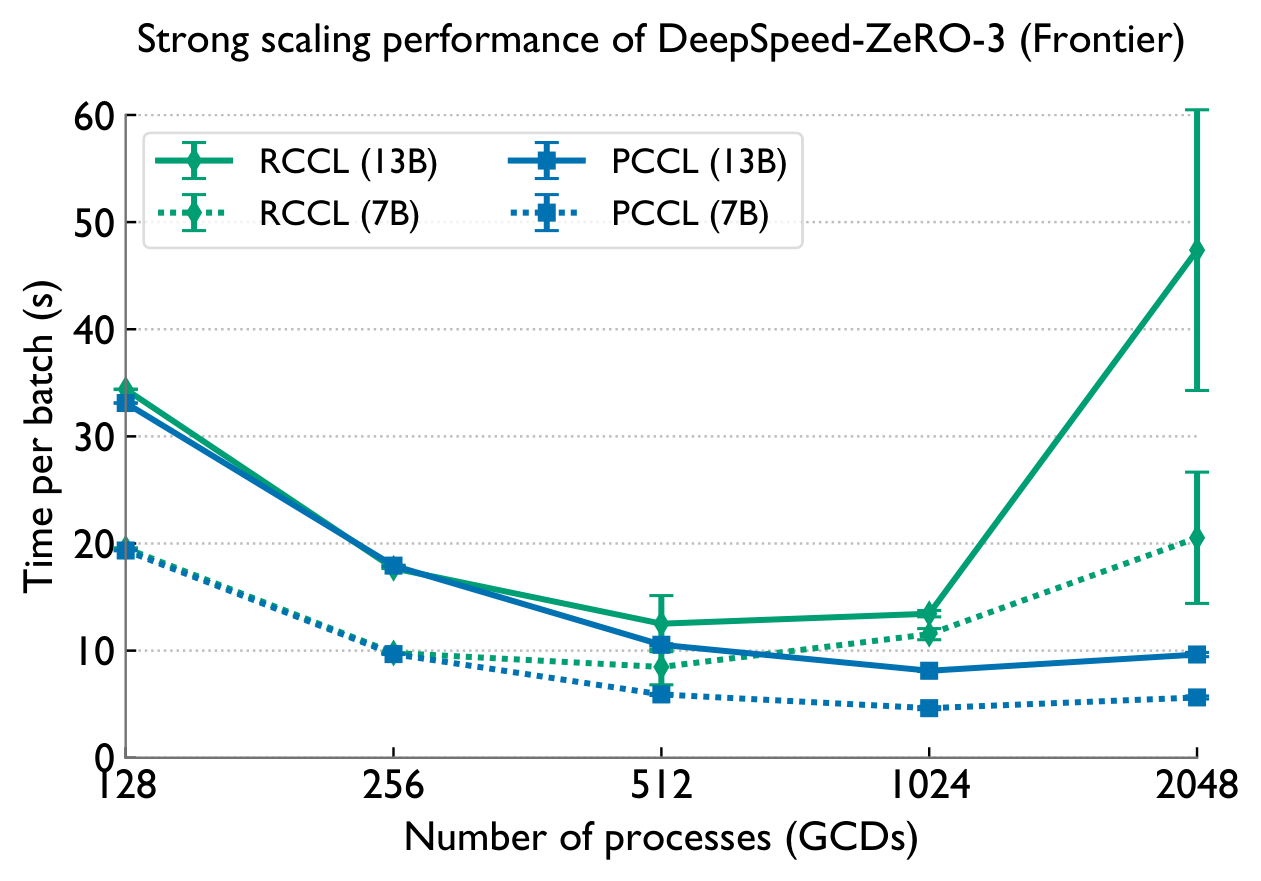
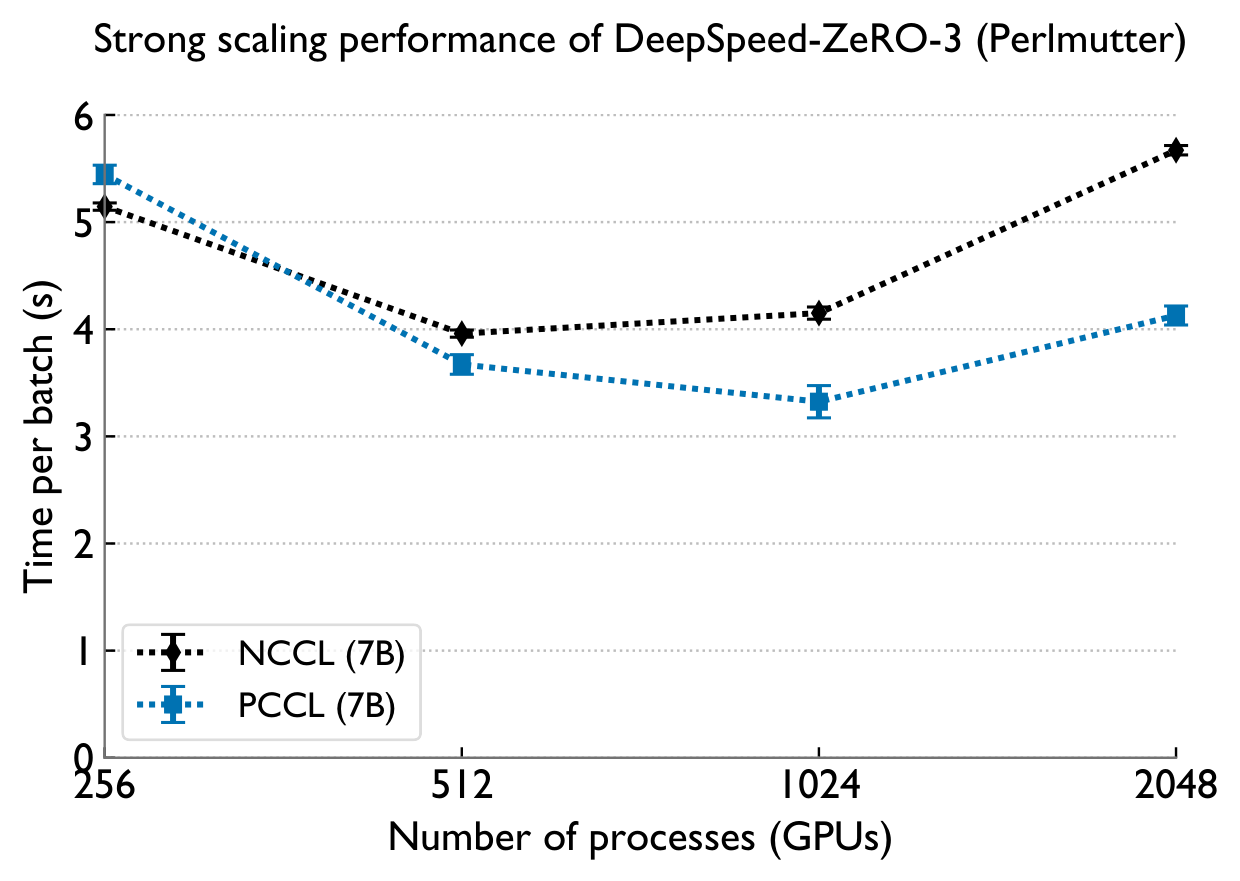
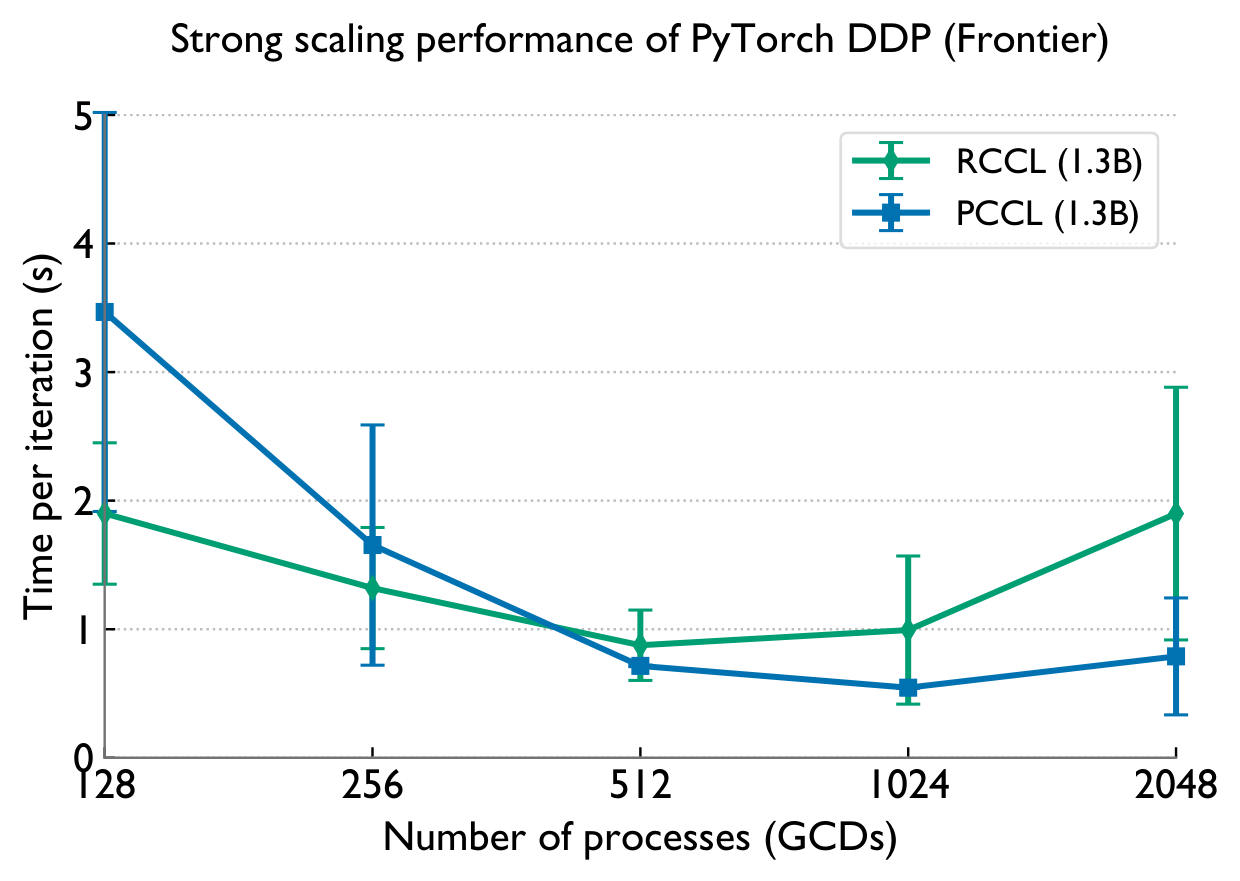
Bottom line
Existing collective libraries leave enormous performance on the table at scale: Cray-MPICH wastes NICs and the GPU, while NCCL/RCCL lack log-latency algorithms for all-gather and reduce-scatter. PCCL's hierarchical design plus ML-guided dispatching delivers 6–160× collective speedups over RCCL on 2048 GCDs of Frontier, and up to 4.9× (ZeRO-3) and 2.4× (DDP) in real LLM training — paving the way for scalable deep learning on next-generation GPU supercomputers.
BibTeX
@inproceedings{singh2025pccl,
title = {The Big Send-off: High-Performance Collectives on
GPU-based Supercomputers},
author = {Singh, Siddharth and Pradeep, Keshav and Singh, Mahua
and Wei, Cunyang and Bhatele, Abhinav},
year = {2025},
note = {University of Maryland, College Park}
}